

Released in October 2018, the Redis Enterprise Kubernetes Operator is only about a year old, but multiple customers are already using it to run Redis Enterprise clusters in production. Now, as we celebrate our Kubernetes Operator’s first birthday, we are adding another powerful Day-2 operations enabler to its toolset: Automated cluster recovery.
For the first time, a Kubernetes Operator can manage a stateful service as if it were stateless, transforming how system operators and developers test, deploy, and manage Redis across environments.
For some background, the Redis Enterprise cluster is a platform for managing multiple databases of various configurations in a multi-isolated-tenant architecture. We like to think of it as an orchestration platform for Redis database instances, also known as shards.
Each of these databases can be set up in one of the following ways:
In a typical deployment scenario, the cluster can manage hundreds of shards, scale to tens of terabytes of data, and run tens of millions of operations per second.
Redis Enterprise cluster employs multiple mechanisms to guarantee the availability of the cluster even in cases of multiple shards failure or node failure events, as long as the majority of the cluster nodes remain alive.
In the unlikely event of what is known as quorum loss, when more than half of the cluster nodes are down, many bad things occur. Caches no longer store complex operations or return cached results, extending application-response time. Web sessions are lost, and e-commerce shopping carts are emptied.
Any such incident can have far-reaching negative business consequences to organizations, anything from poor customer experience to loss of multiple transactions, and those effects are magnified during busy hour, high season, or other special events like product launches.
In all of these scenarios, restoring a cluster and its data to the original, fully operational state is crucial for business-critical Redis use cases where even a second of downtime could translate to the loss of thousands or even millions of operations.
Beyond recovering from uncommon disasters and errors, there are other operational scenarios where automated cluster recovery is essential. Redis operators often relocate or replicate a cluster to a new environment in order to provide services in new regions or serve an expanding population. They also want to recycle the underlying infrastructure of a cluster for maintenance, patching, and scaling with minimal impact to production services. To improve resiliency, they need a precise, repeatable, and expeditious recovery model to facilitate chaos engineering in production environments.
Kubernetes natively orchestrates the lifecycle of stateless services, whereas, in the case of a stateful service such as our cluster, that responsibility would fall on the system operator. This is where the Redis Enterprise Kubernetes Operator comes in.
Our new cluster recovery mechanism lets users address all of these scenarios and more, by enabling recovery from an entire cluster failure event in just minutes. Kubernetes Operator cluster recovery executes a fully automated, predictable, and consistent process to recover the Redis Enterprise cluster. These operations, which previously could have taken hours to complete with increased vulnerability to human error, are now fast, reliable, and fully automated.
Empowered by years of operational knowledge in which we manage more than a million Redis instances in production across all major public clouds and hundreds of on-premises environments, we have introduced a dedicated process to choreograph cluster bootstrapping. Under normal operating conditions, the bootstrapper creates a new cluster upon the instantiation of the deployment. When cluster recovery is required, the system operator can easily update the cluster’s declarative spec to initiate the recovery process.
For auto-recovery, the bootstrapper recreates the cluster and automatically mounts the persistent volume claims of the previous cluster, which contain persistence data. It then recovers the original cluster configuration, joins the remaining nodes, and recreates all the databases provisioned on the original cluster to the new, recovered cluster. Next, recovery loads the datasets, balancing the data across the cluster nodes, and associating the endpoints previously used with each database.
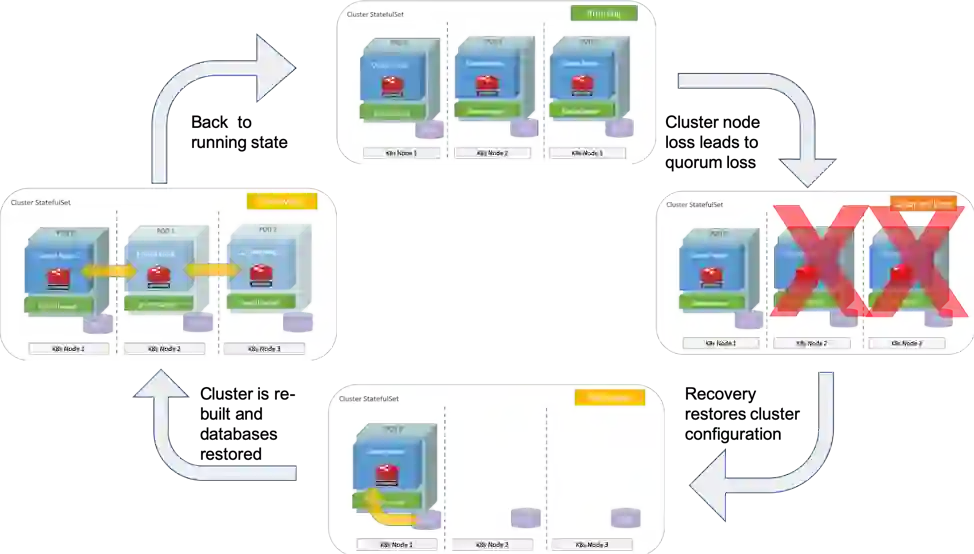
In most scenarios, the cluster recovers in a matter of minutes with no human intervention.
The new Kubernetes Operator-powered recovery experience is available now, with our latest version of the Kubernetes deployment and Redis Enterprise cluster.
If you’d like to experience how the Redis Operator performs automated cluster recovery, you can set up a Redis Enterprise cluster on any one of multiple Kubernetes distributions, on-premises on in the cloud, by following the instructions on our Kubernetes documentation or GitHub. Then, visit the Redis Enterprise Cluster Recovery for Kubernetes page for a walkthrough.


