



Async/Await Programming Basics with Python Examples
Learn More


If you’re a Python developer—and since you’re reading this, you probably are—you’ve almost certainly used Redis and thought it was a great cache. (That was my first impression, too.) And Redis does make a great cache. But it turns out that Redis can solve a lot more problems than just caching.
We’re going to explore some of those other uses for Redis and Redis Enterprise. For fun, I’m using the Bigfoot data I used in my blog post on using geospatial data in Redis. And, since we’re Python developers, all of the examples will, of course, be in Python!
For the code samples below, I’ve chosen to use the aioredis client library as it has great support for async/await. If you’re not familiar with async/await, we have a great blog post demonstrating how it helps improve performance.
Redis has numerous data structures for you to take advantage of: strings, hashes, sets, and lists to name a few. They’re all great for storing data, but a list can also make a great queue.
To use a list as a queue, you simply push new items to the end of the list using RPUSH and then pop them off the front of the list using LPOP or BLPOP. Since Redis makes all changes in a single thread, these operations are guaranteed to be atomic.
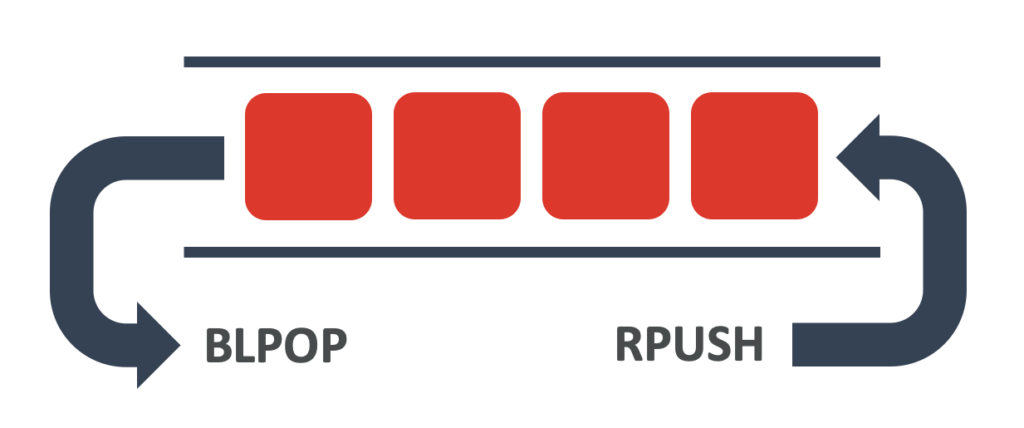
Take a look at this code that adds a few Bigfoot sightings to a queue:
import asyncio
import aioredis
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
await asyncio.gather(
add_to_queue(redis, 'Possible vocalizations east of Makanda'),
add_to_queue(redis, 'Sighting near the Columbia River'),
add_to_queue(redis, 'Chased by a tall hairy creature')
)
redis.close()
await redis.wait_closed()
def add_to_queue(redis, message):
return redis.rpush('bigfoot:sightings:received', message)
asyncio.run(main())
It’s pretty straightforward. We just call redis.rpush on line 18 and it pushes the item onto the queue. Here’s the code that reads from the other end of the queue. It’s equally simple:
import asyncio
import aioredis
from pprint import pp
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
while True:
sighting = await redis.blpop('bigfoot:sightings:received')
pp(sighting)
asyncio.run(main())
Lines 11 and 12 endlessly loop as they await and print Bigfoot sightings pushed onto the queue. I chose to use redis.blpop instead of redis.lpop because it blocks the client and waits until there is something in the list to return. There’s no point in making Redis, our Python code, and the network between them churn through endless polling if we don’t have to. Much more performant to wait for something to process!
There are other cool commands in Redis to make lists work as queues, or even stacks. My favorite is BRPOPLPUSH, which blocks and pops something from the right side of a list and pushes that popped value onto the left side of a different list. You can use it to have queues feed into other queues. Neat stuff!
Redis has a few bits that aren’t really data structures. Pub/Sub is one of those. It’s just what it sounds like, a publish and subscribe mechanism built right into Redis. With just a handful of commands you can add robust Pub/Sub to your Python applications.
We’ll start with subscribing to events, since it’s easier to see an event if you subscribe to it! Here’s the code:
import asyncio
import aioredis
from pprint import pp
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
[channel] = await redis.psubscribe('bigfoot:broadcast:channel:*')
while True:
message = await channel.get()
pp(message)
asyncio.run(main())
I made a choice here to subscribe to a glob-style pattern using redis.psubscribe on line 10, as I want to receive all the Bigfoot messages. By using bigfoot:broadcast:channel:* as my pattern, I’ll receive all events published that start with bigfoot:broadcast:channel:.
The redis.psubscribe (and the less-patterned redis.subscribe) functions are both variadic, so they return Python lists—one entry for each argument. I destructure (or unpack in Python parlance) that list to get the one channel I asked for. Once I have that channel, I make a blocking call to .get to await the next message.
Publishing events is very simple. Here’s the code:
import asyncio
import aioredis
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
await asyncio.gather(
publish(redis, 1, 'Possible vocalizations east of Makanda'),
publish(redis, 2, 'Sighting near the Columbia River'),
publish(redis, 2, 'Chased by a tall hairy creature')
)
redis.close()
await redis.wait_closed()
def publish(redis, channel, message):
return redis.publish(f'bigfoot:broadcast:channel:{channel}', message)
asyncio.run(main())
The key line to understand is line 18, where I publish the message to the desired channel using the well-named redis.publish function.
It’s worth noting that Pub/Sub is a fire-and-forget mechanism. If your code publishes an event and nobody is listening, it’s lost forever. If you want your events to stick around, consider using the aforementioned queue or check out our next topic.
Redis can be used to publish and read events to a stream. Redis Streams are a big topic even though there are only a few commands to master. But from Python, it’s reasonably straightforward and I’ll show you how to do it.
The following code adds three Bigfoot sightings to a stream:
import asyncio
import aioredis
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
await asyncio.gather(
add_to_stream(redis, 1, 'Possible vocalizations east of Makanda', 'Class B'),
add_to_stream(redis, 2, 'Sighting near the Columbia River', 'Class A'),
add_to_stream(redis, 3, 'Chased by a tall hairy creature', 'Class A'))
redis.close()
await redis.wait_closed()
def add_to_stream(redis, id, title, classification):
return redis.xadd('bigfoot:sightings:stream', {
'id': id, 'title': title, 'classification': classification })
asyncio.run(main())
The important code here is in lines 17 and 18, where we use the redis.xadd function to add the fields of a sighting to the stream.
Each added event has a unique identifier containing the timestamp in milliseconds since the start of 1970 and a sequence number joined with a dash. For example, as I write this, 1,593,120,357,193 milliseconds (1.59 gigaseconds?) have expired since midnight on January 1, 1970 (the Unix epoch). So, if I had run the code and that command had executed in Redis at that exact moment the event id would be 1593120357193-0.

When you add an event, you can specify ‘*’ instead of one of these identifiers and Redis will use the current time to generate one. And, since the redis.xadd function defaults it to that value for you, you don’t need to worry about it too much.
Until you go to read from the stream that is. When you read from a stream, you need to specify a starting identifier. You can see that on line 10 where we have it set the variable last_id as 0-0 which represents the first record for the first moment in time:
import asyncio
import aioredis
from pprint import pp
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf8')
last_id = '0-0'
while True:
events = await redis.xread(['bigfoot:sightings:stream'], timeout=0, count=5, latest_ids=[last_id])
for key, id, fields in events:
pp(fields)
last_id = id
asyncio.run(main())
On line 12, using the redis.xread function, we ask for (at most) five events from the stream that are after 0-0. This returns a list of lists which we loop over and destructure to get the fields and the identifier of the event. The identifier of the event is stored for future calls to redis.xread so we can get new events and reread the old ones.
Redis can be extended to add new commands and capabilities. There are scads of modules available for things as diverse as time-series data, and, for this example, search.
Search is a powerful search engine that ingests data ridiculously fast. Some folks like to use it for ephemeral search but you can use it to search in lots of ways. Here’s how to use it:
import asyncio
import aioredis
from pprint import pp
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
await redis.execute('FT.DROP', 'bigfoot:sightings:search')
await redis.execute('FT.CREATE', 'bigfoot:sightings:search',
'SCHEMA', 'title', 'TEXT', 'classification', 'TEXT')
await asyncio.gather(
add_document(redis, 1, 'Possible vocalizations east of Makanda', 'Class B'),
add_document(redis, 2, 'Sighting near the Columbia River', 'Class A'),
add_document(redis, 3, 'Chased by a tall hairy creature', 'Class A'))
results = await search(redis, 'chase|east')
pp(results)
redis.close()
await redis.wait_closed()
def add_document(redis, id, title, classification):
return redis.execute('FT.ADD', 'bigfoot:sightings:search', id, '1.0',
'FIELDS', 'title', title, 'classification', classification)
def search(redis, query):
return redis.execute('FT.SEARCH', 'bigfoot:sightings:search', query)
asyncio.run(main())
On lines 12 and 13 we use FT.CREATE to create an index. An index requires the schema describing the fields in each document we will be adding. In my example, I’m adding Bigfoot sightings and we have a title and a classification—both of them text fields.
Once we have an index, we can start adding documents to it. This happens on lines 27 and 28 with the FT.ADD command. Each document requires a unique ID, a rank between 0.0 and 1.0, and the fields that make it up.
With the index loaded with documents, we can now search it using the FT.SEARCH command and a query. You can see this on line 31. The particular query (on line 20) is “chase|east” which instructs Search to find documents containing either of these terms. In our case, this will return two documents.
Redis can also be used as a database. A wicked fast, in-memory database. Just add the data you want to Redis and go read it later. This example uses hashes to do this, which is a good data structure for modeling the types of records you might want to store, and includes the primary key to the data as part of the key name:
import asyncio
import aioredis
from pprint import pp
async def main():
redis = await aioredis.create_redis('redis://:foobared@localhost:6379/0', encoding='utf-8')
await asyncio.gather(
add_sighting(redis, 1, 'Possible vocalizations east of Makanda', 'Class B'),
add_sighting(redis, 2, 'Sighting near the Columbia River', 'Class A'),
add_sighting(redis, 3, 'Chased by a tall hairy creature', 'Class A'))
sightings = await asyncio.gather(
read_sighting(redis, 1),
read_sighting(redis, 2),
read_sighting(redis, 3))
pp(sightings)
redis.close()
await redis.wait_closed()
def add_sighting(redis, id, title, classification):
return redis.hmset(f'bigfoot:sighting:{id}',
'id', id, 'title', title, 'classification', classification)
def read_sighting(redis, id):
return redis.hgetall(f'bigfoot:sighting:{id}')
asyncio.run(main())

I know what you’re thinking: “What if I turn the computer off? What if it crashes? Then I lose everything!” Nope. You can modify your redis.conf file to persist your data in a couple of different ways. And, if you’re using Redis Enterprise, we have solutions that manage that for you so you can just use it and not worry about it.
RedisInsight isn’t Python specific but it’s something any developer would find useful. What is RedisInsight? It’s a free, capable GUI for looking at and managing the data you have in Redis. With it you can look at your queues and streams, execute searches with Search, and browse all the data in your database. All the stuff I’ve just shown you!
It supports Search and Query, of course, including JSON, and Time Series. I’ve been using RedisInsight since it was first released and have found the visuals to be particularly beautiful and genuinely useful. Go check it out!
If you want to try some of these examples yourself, all of my code is up on GitHub. You can clone it and get started. If you’re a Docker user, there is a shell script named start-redis.sh that will pull down an image and start a version of Redis that works with all these examples.
And once you’re done playing and want to build some software, sign up and try Redis Enterprise Cloud. It’s the same Redis you know and love, but managed for you in the cloud so you can focus on your software.
