

Click here to download the Probabilistic module which supports scalable bloom and cuckoo filters.
A Bloom filter is a probabilistic data structure conceived in 1970 by Burton Howard which provides an efficient way to verify that an entry is certainly not in a set. This makes it especially ideal when trying to search for items on expensive-to-access resources (such as over a network or disk): If I have a large on-disk database and I want to know if the key foo exists in it, I can query the Bloom filter first, which will tell me with a certainty whether it potentially exists (and then the disk lookup can continue) or whether it does not exist, and in this case I can forego the expensive disk lookup and simply send a negative reply up the stack.
While it’s possible to use other data structures (such as a hash table) to perform this, Bloom filters are also especially useful in that they occupy very little space per element, typically counted in the number of bits (not bytes!). There will exist a percentage of false positives (which is controllable), but for an initial test of whether a key exists in a set, they provide excellent speed and most importantly excellent space efficiency.
Bloom filters are used in a wide variety of applications such as ad serving – making sure a user doesn’t see an ad too often; likewise in content recommendation systems – ensuring recommendations don’t appear too often, in databases – quickly checking if an entry exists in a table before accessing it on disk, and so on.
Bloom filters work by running an item through a quick hashing function and sampling bits from that hash and setting them from a 0 to 1 at particular intervals in a bitfield. To check for existence in a Bloom filter, the same bits are sampled. Many items may have bits that overlap, but since a relational hash function produces unique identifiers, if a single bit from the hash is still a 0, then we know it has not been previously added. The k hash function is a critical component in this process, determining the positions in the bit array that should be checked or set for each item.
Most of the literature on Bloom filter uses highly symbolic and/or mathematical descriptions to describe it. If you’re mathematically challenged like yours truly, you might find my explanation more useful.
A Bloom filter is an array of many bits. When an element is ‘added’ to a bloom filter, the element is hashed. Then bit[hashval % nbits] is set to 1. This looks fairly similar to how buckets in a hash table are mapped, utilizing a relational hash function. To check if an item is present or not, the hash is computed and the filter sees if the corresponding bit is set or not.
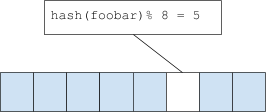
Of course, this is subject to collisions. If a collision occurs, the filter will return a false positive – indicating that the entry is indeed found (note that a bloom filter will never return a false negative, that is, claim that something does not exist when it fact it is present).
In order to reduce the risk of collisions, an entry may use more than one bit: the entry is hashed bits_per_element (bpe) times with a different seed for each iteration resulting in a different hash value, and for each hash value, the corresponding hash % nbits bit is set. To check if an entry exists, the candidate key is also hashed bpe times, and if any corresponding bit is unset, the it can be determined with certainty that the item does not exist.
The actual value of bpe is determined at the time the filter is created. Generally the more bits per element, the lower the likelihood of false positives.
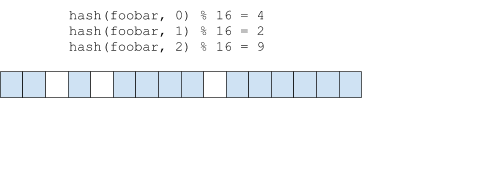
In the example above, all three bits would need to be set in order for the filter to return a positive result.
Another value affecting the accuracy of a Bloom filter is its fill ratio, or how many bits in the filter are actually set. If a filter has a vast majority of bits set, the likelihood of any specific lookup returning false is decreased, and thus the possibility of the filter returning false positives is increased.
Counting Bloom filters and Cuckoo filters are advanced variants of the traditional Bloom filter that offer additional features. Counting Bloom filters allow for the removal of elements by maintaining a count of the number of times a bit is set, rather than simply setting it to 1. This can be particularly useful in dynamic datasets where elements need to be added and removed over time.
Cuckoo filters, on the other hand, provide a more space-efficient alternative to Bloom filters and allow for the deletion of items without significantly increasing the rate of false positives. They work by using a different kind of hash function and a bucket system that can relocate items to resolve hash collisions.
Another recent development is the Ribbon filter, which is designed to be more space-efficient than both Bloom and Cuckoo filters while still providing fast lookup times. Ribbon filters use a series of hash functions in a novel way to create a compact, efficient data structure.
Typically Bloom filters must be created with a foreknowledge of how many entries they will contain. The bpe number needs to be fixed, and likewise the width of the bit array is also fixed.
Unlike hash tables, Bloom filters cannot be “rebalanced” because there is no way to know which entries are part of the filter (the filter can only determine whether a given entry is not present, but does not actually store the entries which are present).
In order to allow Bloom filters to ‘scale’ and be able to accommodate more elements than they’ve been designed to, they may be stacked. Once a single Bloom filter reaches capacity, a new one is created atop it. Typically the new filter will have greater capacity than the previous one in order to reduce the likelihood of needing to stack yet another filter.
In a stackable (scalable) Bloom filter, checking for membership now involves inspecting each layer for presence. Adding new items now involves checking that it does not exist beforehand, and adding it to the current filter. Hashes still only need to be computed once however.
When creating a Bloom filter – even a scalable one, it’s important to have a good idea of how many items it is expected to contain. A filter whose initial layer can only contain a small number of elements will degrade performance significantly because it will take more layers to reach a larger capacity.
Bloom filters work by running an item through a quick hashing function and sampling bits from that hash and setting them from a 0 to 1 at particular interval in a bitfield. To check for existence in a Bloom filter, the same bits are sampled. Many item may have bits that overlap, but since a hashing function produce unique identifiers, if a single bit from the hash is still a 0, then we know it has not been previously added.
Bloom filters, including their variants like counting Bloom filters, Cuckoo filters, and Ribbon filters, have been used with Redis for many years via client side libraries that leveraged GETBIT and SETBIT to work with a bitfield at a key. Thankfully, since Redis 4.0, the ReBloom module has been available which takes away any Bloom filter implementation overhead.
A good use case for a Bloom filter is to check for an already used username. On a small scale, this is no problem, but as a service grows, this can be very taxing on a database. It is very simple to implement this with a ReBloom.
First, let’s add a handful of usernames as a test:
> BF.ADD usernames funnyfred (integer) 1 > BF.ADD usernames fredisfunny (integer) 1 > BF.ADD usernames fred (integer) 1 > BF.ADD usernames funfred (integer) 1
Now, let’s run some test versus the Bloom filter.
> BF.EXISTS usernames fred (integer) 1 > BF.EXISTS usernames fred_is_funny (integer) 0
As expected, fred_is_funny yields a 0. A response of zero means we can be sure that this username has not been used. A response of 1 means it might have been used. We can’t say for certain as it might a case of overlapping bits between multiple items.
Generally, the chances of false positives are low, but non-zero. As the Bloom filter “fills up” the chances increase. You can tweak the error rate and size with the BF.RESERVE command.

In this video, Guy Royse, developer advocate will explain what a Bloom filter is, how they work, and how to use one in Redis.
Redis features are written in high performance C, and are able to expose their own commands and data types, as well as define how those data types get persisted. This allowed us to simply create a very powerful Bloom filter module, and have it easily added to Redis.
Getting the module and using it is very straightforward:
You should first download and compile the module:
$ git clone git://github.com/RedisModules/rebloom $ cd rebloom $ make
You should now have a rebloom.so in the rebloom directory.
Once you’ve built the filter module you, point your redis.conf or the redis command line to the module using loadmodule or –loadmodule respectively:
redis.conf:
loadmodule /path/to/rebloom.so
Command-line
$ redis-server --loadmodule /path/to/rebloom.so
You can play with it a bit using redis-cli:
127.0.0.1:6379> BF.ADD bloom mark 1) (integer) 1 127.0.0.1:6379> BF.ADD bloom redis 1) (integer) 1 127.0.0.1:6379> BF.EXISTS bloom mark (integer) 1 127.0.0.1:6379> BF.EXISTS bloom redis (integer) 1 127.0.0.1:6379> BF.EXISTS bloom nonexist (integer) 0 127.0.0.1:6379> BF.EXISTS bloom que? (integer) 0 127.0.0.1:6379> 127.0.0.1:6379> BF.MADD bloom elem1 elem2 elem3 1) (integer) 1 2) (integer) 1 3) (integer) 1 127.0.0.1:6379> BF.MEXISTS bloom elem1 elem2 elem3 1) (integer) 1 2) (integer) 1 3) (integer) 1
You can also create a custom Bloom filter. The BF.ADD command creates a new Bloom filter suitable for a small-ish number of items. This consumes less memory but may be less ideal for large filters:
127.0.0.1:6379> BF.RESERVE largebloom 0.0001 1000000 OK 127.0.0.1:6379> BF.ADD largebloom mark 1) (integer) 1
Rebloom uses a modified version of libloom, with some additional enhancements:
|
Implementation |
Add |
Check |
|
redablooms |
20k/s |
7k/s |
|
lua |
29k/s |
25k/s |
|
bloomd |
250k/s |
200k/s |
|
rebloom |
400k/s |
440k/s |
Once all was done, I benchmarked it and compared it to some other implementations. I wrote this filter initially because a previous filter implementation was too slow. Compared to a Lua implementation which yielded 30k/sec, redablooms was slower with 20k/sec.
Running the equivalent command with rebloom:
mnunberg@mbp15III ~/Source/rebloom $ redis-benchmark -e -r 100000000 -n 1000000 -c 20 bf.add test __rand_int__ ====== bf.add test __rand_int__ ====== 1000000 requests completed in 8.92 seconds 20 parallel clients 3 bytes payload keep alive: 1 99.99% <= 1 milliseconds 100.00% <= 2 milliseconds 100.00% <= 3 milliseconds 100.00% <= 3 milliseconds 112082.49 requests per second
With pipelining and perhaps modifying the thread count, it would have been possible to get even nicer numbers, but a fair benchmark is an apples-to-apples comparison.
I compared bloomd’s own benchmark to an equivalent rebloom commandset. Bloomd by default uses an initial capacity of 100k and an error ratio of 1/10k, or 0.0001. Its benchmark program simply sets 1,000,000 items and then reads them. It uses fire-and-forget semantics when setting items so network latency doesn’t become a factor when sending the commands:
mnunberg@mbp15III ~/Source/bloomd $ ./bench Thread started.Using filter: foobar1464749818 Connect: 0 msec Create: 1 msec Set: 4090 msec. Num: 999987 Check: 6130 msec. Num: 1000000
So we get 1M sets in 4 seconds, or 250K op/s, and 1M reads in 6 seconds, or 166K ops/sec.
The equivalent with rebloom:
mnunberg@mbp15III ~/Source/rebloom $ redis-cli del test; redis-cli bf.reserve test 0.0001 100000; redis-benchmark -e -r 1000000 -l -n 1000000 -P 100 -c 1 bf.add test __rand_int__ (integer) 1 OK ====== bf.add test __rand_int__ ====== 1000000 requests completed in 2.65 seconds 1 parallel clients 3 bytes payload keep alive: 1 100.00% <= 0 milliseconds 376931.75 requests per second
I let this loop for a while because unlike the bloomd benchmark which uses sequential keys, redis-bench uses random IDs. this means that there would be a greater chance for collision.
Rebloom performs at 370k/s, or about 50% faster than bloomd.
For reading:
mnunberg@mbp15III ~/Source/rebloom $ redis-benchmark -e -r 1000000 -n 1000000 -l -P 100 -c 1 bf.exists test __rand_int__ ====== bf.exists test __rand_int__ ====== 1000000 requests completed in 2.65 seconds 1 parallel clients 3 bytes payload keep alive: 1 99.99% <= 1 milliseconds 100.00% <= 1 milliseconds 377073.91 requests per second
Which is about 150% faster than bloomd!
Finally, I added a BF.DEBUG command, to see exactly how the filter is being utilized:
127.0.0.1:6379> BF.DEBUG test 1) "size:987949" 2) "bytes:239627 bits:1917011 hashes:14 capacity:100000 size:100000 ratio:0.0001" 3) "bytes:551388 bits:4411101 hashes:16 capacity:200000 size:200000 ratio:2.5e-05" 4) "bytes:1319180 bits:10553436 hashes:19 capacity:400000 size:400000 ratio:3.125e-06" 5) "bytes:3215438 bits:25723497 hashes:23 capacity:800000 size:287949 ratio:1.95313e-07"
This outputs the total number of elements as the first result, and then a list of details for each filter in the chain. As you can see, whenever a new filter is added, its capacity grows exponentially and the strictness for errors increases.
Note that this filter chain also uses a total of 5MB. This is still much more space efficient than alternative solutions, since we’re still at about 5 bytes per element, and the uppermost filter is only at about 12% utilization. Had the initial capacity been greater, more space would have been saved and lookups would have been quicker.
You can download rebloom yourself at https://github.com/RedisModules/rebloom. If you’re using Redis Enterprise, it will be bundled with version 5.0.
Let me know if you think you can make it even faster, or file a github issue if you are having problems.


