When we wanted to add real-time full-text search to the Redis documentation site, we turned to RediSearch. The robust search features in the RediSearch module helped us transform a bland form into an awesome search experience. To show off some of what’s possible with RediSearch and to help jumpstart your search projects, I’d like to talk about the architecture of our project and share our code. The Python application we built is called redis-sitesearch. If you want to check out the code or run it for your own site, it’s open source, and you can try RediSearch for free on Redis Cloud Essentials. Read on for the nitty-gritty details!

We built a new search experience because our documentation site had outgrown our previous search engine, Lunr.js. Specifically, we wanted a few things from a new search experience:
We knew that RediSearch could deliver everything on our list. (If you aren’t familiar with RediSearch, it’s a great querying and indexing system for Redis, and includes powerful full-text search capabilities.) So, we got to work. And within a few weeks, we had a brand-new search API powering search on our documentation site. Let’s look at the pieces of the project from a high level, and then we’ll zoom in closer.
Our documentation search has two major pieces: a JavaScript frontend consisting of an HTML input and a search results list, and a REST API backend that queries RediSearch.
While you type, the frontend makes search requests to the backend API and renders the results. Thanks to Redis being an in-memory database, and deployments across multiple zones, getting these results is fast—averaging around 40-to-50 milliseconds in testing from Oregon.

We know that humans perceive response times below 100 milliseconds as instant, so we were happy to hit the 40ms – 60ms range.
What exactly is going on inside the search app to make this happen, though? Here are the pieces involved:
Here’s a diagram of how the pieces fit together:
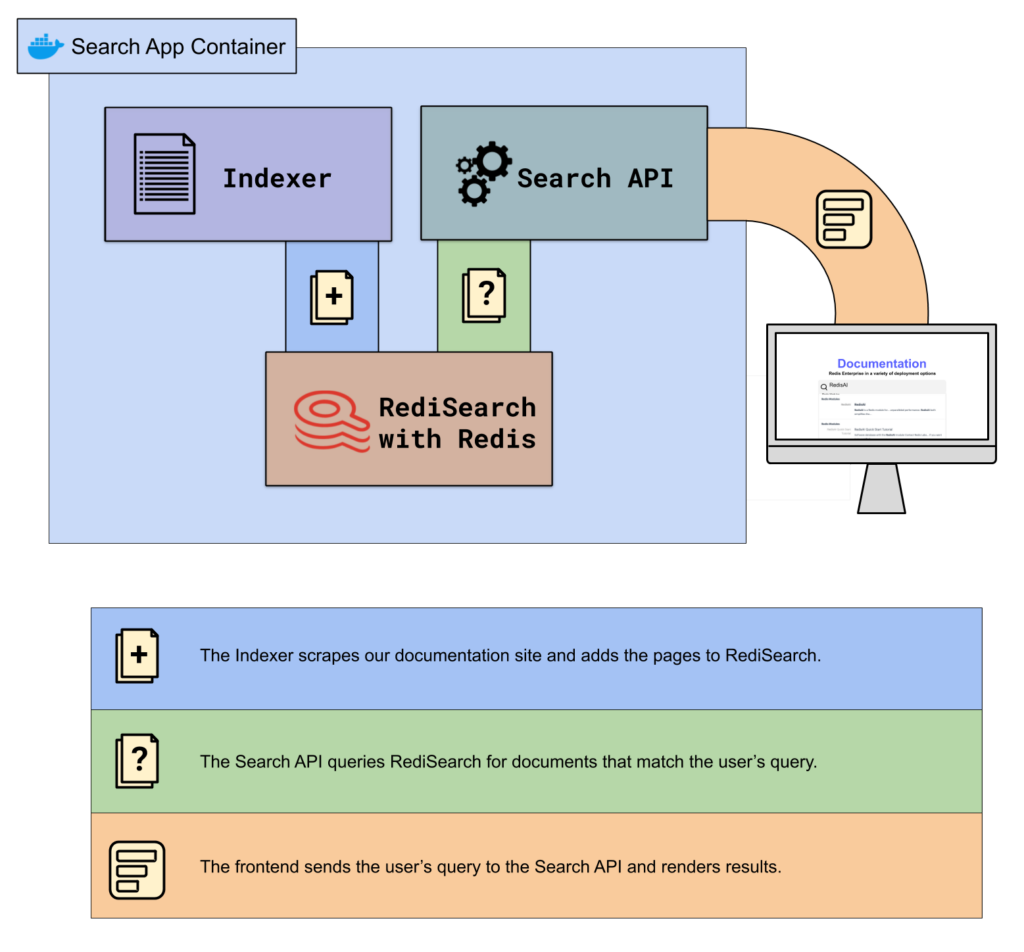
We run these pieces inside a container on Google Cloud, and distribute instances of the container worldwide using a multi-zone deployment behind a global load balancer.
Now let’s take a detailed look at the four steps involved in the backend application:
Before we can handle any search queries, we need to index our documentation site. To do this, we use a RediSearch index definition that contains all of the fields we’ll use to search. A background job in our Python application scrapes the documentation site on a schedule and adds its contents to the RediSearch index. Let’s see how both of these pieces work.
The index definition
With RediSearch, you need to create an index definition before you can make any queries.
RediSearch indexes stay in sync with Hashes in your Redis database. In the redis-sitesearch app, we create a Hash for every document that we want to add to the search index.
Then we create a RediSearch index for the site we want to index. Each index syncs with the Hashes in keys matching the prefix sitesearch:{environment}:{url}:doc:. Currently, we index only our documentation site, but the design allows us to index multiple sites using the same app instance. Index definitions take a SCHEMA argument that defines which Hash fields should be added to the index. redis-sitesearch indexes the following fields:
Using the redisearch-python client, the schema looks like this:
TextField("title", weight=10),
TextField("section_title"),
TextField("body", weight=1.5),
TextField("url"),
You can see that we’ve added a “weight” to the title and body fields. This means that search queries will consider hits in those fields more relevant than other fields.
The indexing job
With the index definition in place, we needed a background job to scrape our documentation site and create the Hashes for RediSearch to index.
To do this, we used Redis Queue to build an indexing job that runs every 30 minutes. This job uses the Scrapy library, which we’ve extended with custom logic to parse scraped page content into structured data.
Parsing structured page data with Scrapy
One of our goals for the new search experience was to show the section of the page in which we found a search result. For example, if the query “gcp” finds a hit in the “Team management” section of the “Account and Team Settings” page, we want to show both the page and section in the search result. This screenshot of a search result shows an example:

In this screenshot, “GCP” is the hit, so that term is rendered in bold, an example of RediSearch’s highlights feature. “Account and Team Settings” is the title of the page on which we found the hit, and “Team management” is the name of the section that contained the hit.
We accomplish this by breaking up every page we scrape into SearchDocument objects. SearchDocument is the domain model that our application uses to represent parts of a web page that we want to make searchable.
After Scrapy finishes crawling the site, we convert the SearchDocument objects into Redis Hashes. RediSearch then indexes the Hashes in the background.
Scoring documents
When you create a Hash with a key that RediSearch is configured to index, you can optionally provide a “__score” field. If you do, RediSearch will multiply the final relevance value of that document in a search query by the __score. This means that you can model some relevance-related facts about your data at index time. Let’s review a couple of examples from redis-sitesearch.
We created scoring functions to adjust the scores of documents based on the following rules:
This kind of fine-grained control is a major reason we switched to RediSearch.
Validating documents
Weighting documents differently based on rules helps us boost the relevance of search hits, but there are certain types of documents we want to avoid indexing altogether. Our validators are simple functions that decide whether or not to index a SearchDocument based on arbitrary logic. We use these to skip release notes and any document that looks like a 404 page.
With a background job regularly indexing our documentation site in RediSearch, we could finally build our search API! We used the Falcon web framework for the API, because of its fast performance.
An effective search API translates the frontend user queries into RediSearch queries. RediSearch supports numeric ranges, tags, geo filters, and many more types of queries. For this app, the best fit was prefix matching. With prefix matching, RediSearch compares all terms in the index against the given prefix. If user types “red” into the search form, the API will issue the prefix query “red*”.
With prefix matching, “red*” will find many hits, including:
The search form will start displaying results for hits across all these terms as the user types. When the user finishes the phrase they are typing, the results will begin to focus. If the final search is for “redisearch,” the app issues one last query to Redis for “redisearch*” and the results will be specific to RediSearch.

Google Cloud made deploying redis-sitesearch easy. We built the backend application as a single container on Google Cloud’s Compute Engine, running the following processes:
We deploy this container to instance groups in the US-West, US-East, Zurich, and Mumbai zones on Google Cloud.
Note: Compute Engine can run only a single container per node, which is why we run the Python app alongside Redis. However, this has the benefit of reducing latency!
A global load balancer routes traffic to these instances based on the geographic origin of the request and the current load within the instance group.
We wanted to give our users the best possible documentation search experience. The way to do that, RediSearch, was right in front of us.
If you’re building a full-text site search feature, take a look at RediSearch. It keeps your entire search index in memory, so queries run extremely fast. RediSearch can also filter by numerical range, geographic radius, and much more. You can even jumpstart your project by using our open-sourced redis-sitesearch codebase. And if you want to try RediSearch without hosting it yourself, you can do so for free on Redis Cloud Essentials.
Want to learn more about RediSearch? Watch our latest YouTube video: Querying, Indexing, and Full-text Search in Redis.