

Instagram recently published a post on their engineering blog about the concept of promisifying cached values. The idea is that, on a cache miss, it takes a while to fetch the missing value, which could cause stampedes on the underlying DBMS that the cache is supposed to protect. A stampede, among other things, consists of multiple parallel requests that, on a cache miss, trigger multiple instances of the same work to populate the cache (see below)
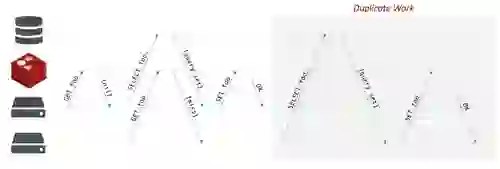
In their post, Instagram’s Nick Cooper showcases the idea of storing a dummy value (i.e. the promise) in the cache to signal to competing requesters that someone else is preparing the data, so they know to wait instead of hitting the DBMS to death. This is the article I’m referring to, it also received a few comments on Hacker News.
This idea is not new (it’s one of the features you get out of the box with read/write-through caches, since they handle the database transparently), but I think it’s very good and worth discussing. In this post, I’ll share a simple implementation of this approach and how you can get out of it even more benefits than typically offered with (r/w)-through caches.
Before going into the details of how my implementation works, here’s an overview of what I was able to achieve after mapping this use case to Redis operations. My implementation:
My implementation primarily relies on three Redis features: key expiration (TTL), atomic operations (SET NX) and Pub/Sub. More generally, I made good use of the principle I explained in a previous post:
Shared state begets coordination and vice-versa.
Redis understands this very well, which is why it’s so easy to build this kind of abstraction using it. In this case, the Pub/Sub messaging functionality helps us tie together a locking mechanism to easily create a real cross-network promise system.
I’m calling my implementation of this pattern Redis MemoLock. At a high level, it works as follows:
In practice, the algorithm is slightly more complex so we can get the concurrency right and handle timeouts (locks/promises that can’t expire are borderline useless in a distributed environment). Our naming scheme is also slightly more complicated because I opted to give a namespace to each resource, in order to allow multiple independent services to use the same cluster without risking key name collisions. Other than that, there is really not much complexity required to solve this problem.
You can find my code here on GitHub. I’ve published a Go implementation, and soon I’ll add a C# one in conjunction with my upcoming talk at NDC Oslo (and probably more languages in the future). Here’s a code example from the Go version:
package main
import (
"fmt"
"time"
"github.com/go-redis/redis"
"github.com/kristoff-it/redis-memolock/go/memolock"
)
func main () {
// First, we need a redis connection pool:
r := redis.NewClient(&redis.Options{
Addr: "localhost:6379", // use default Addr
Password: "", // no password set
DB: 0, // use default DB
})
// A memolock instance handles multiple resources of the same type,
// all united by the same tag name, which will be then used as a key
// prefix in Redis.
queryResourceTag := "likes"
queryMemoLock, _ := memolock.NewRedisMemoLock(r, queryResourceTag, 5 * time.Second)
// This instance has a 5 second default lock timeout:
// Later in the code you can use the memolock to cache the result of a function and
// make sure that multiple requests don't cause a stampede.
// Here I'm requesting a queryset (saved in Redis as a String) and providing
// a function that can be used if the value needs to be generated:
resourceID := "kristoff"
requestTimeout := 10 * time.Second
cachedQueryset, _ := queryMemoLock.GetResource(resourceID, requestTimeout,
func () (string, time.Duration, error) {
fmt.Println("Cache miss!\n")
// Sleeping to simulate work.
<- time.After(2 * time.Second)
result := fmt.Sprintf(`{"user":"%s", "likes": ["redis"]}`, resourceID)
// The function will return a value, a cache time-to-live, and an error.
// If the error is not nil, it will be returned to you by GetResource()
return result, 5 * time.Second, nil
},
)
fmt.Println(cachedQueryset)
fmt.Println("Launch the script multiple times, see what changes. Use redis-cli to see what happens in Redis.")
}
If you run two instances of this program within 5 seconds, “Cache miss!” will only show once, regardless of whether your first execution already concluded (i.e. the value was cached) or is still computing (sleeping instead of doing useful work, in the case of this sample code).
Two big reasons:
This brings us to the reason I called my solution MemoLock. If you generalize the promisified caching idea to cache not only queries, but any (serializable) output of a (pure-ish) function call, you are talking about memoization (not memorization). If you’ve never heard about memoization, read more about it — it’s an interesting concept.
The pattern described by Instagram isn’t surprisingly new, but it’s worth discussing. Better caching can help a ton of use cases, and we, as an industry, are not always fully familiar with the concept for promises, especially when it’s outside the scope of a single process. Try out the code on GitHub and let me know if you like it.


