

Two weeks ago was the first Feature Store Summit event, filled with talks, panels, and a lively Slack channel with more than 800 active members. The summit brought together industry thought leaders and practitioners from over 25 organizations—all focused on feature stores! The size of the summit and enthusiasm of the attendees shows the growing importance of feature stores and the key role they play in machine learning operations.
The event was held virtually and was hosted by featurestore.org both on the conference side (thanks to Jim Dowling) and on the Slack channel (thanks to Helena Paic), including a Slack Q&A after each talk. Over two days, the 21 talks, 4 panels, and multiple polls covered key themes, including: 1) solving the hardest problems at scale, 2) who benefits from feature stores, 3) the future of feature stores, and 4) whether it’s better to build or buy.
In addition, Taimur Rashid, our Chief Business Development Officer, delivered a presentation with Davor Bonaci and Dr. Charna Parkey from Kaskada called Creating and Operating ML Models from Event-based Data Using Feature Stores and Feature Engines. In it, they also covered the importance of having a scalable, reliable, low-latency online store for serving features in production. More details on their presentation are provided under point three below.
Here are our four key takeaways from the event.
A large and growing portion of Machine Learning (ML) use cases rely on real-time data. And a recurring theme at the Feature Store Summit was delivering ML use cases using real-time data with low latency—and the importance of the online store in delivering it. Consistently, reliably, and quickly serving fresh data for ML models for online predictions is hard and complex, especially for real-time applications that require very low latency.
For example, 100ms end-to-end latency is required for most real-time applications, with some use cases, like AT&T fraud detection, requiring less than 50ms latency. This is especially complicated at the scale companies like AT&T, Twitter, Zomato, Spotify, and DoorDash operate at, with thousands of features, multi-terabyte-sized and sometimes petabyte-sized datasets, and 100s thousands of predictions per second. If we look at the scale of DoorDash as an example, then the total number of feature-value pairs exceeds billions. The throughput required for high volume use cases at DoorDash (like store ranking) reaches tens of millions of reads per second!
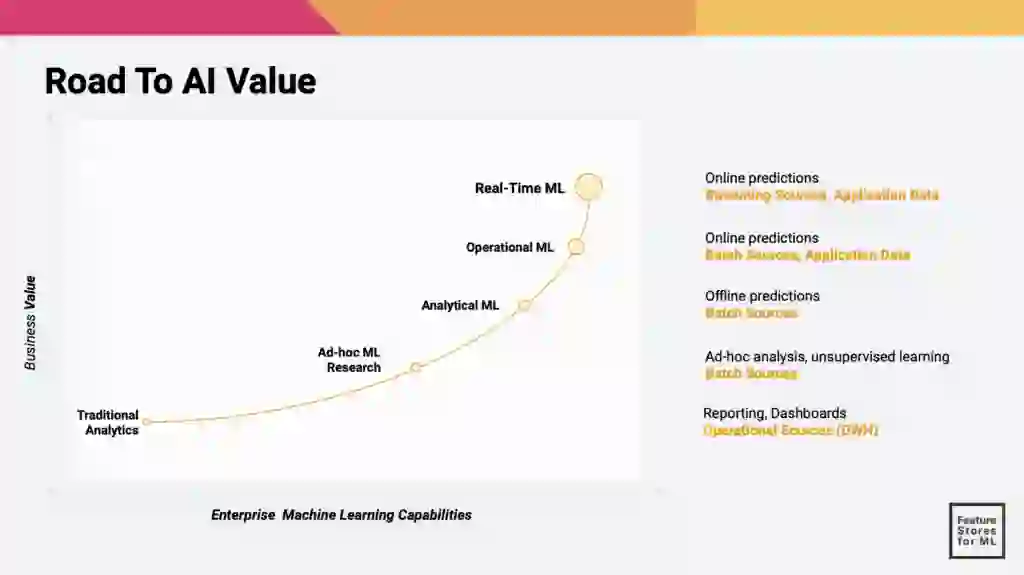
We found the slide above from Hopswork’s presentation to be very perceptive and useful in explaining why companies are working so hard to provide real-time AI at scale to solve that hardest problem. As illustrated by the utility function in the slide, the lower the latency, the greater the business value for the company and its users—and this correlation is exponential! Note the difference between real-time ML and operational ML: While predictions are done online for both (e.g. while the user is interacting with the website), operational ML (and all the other cases below it) uses data from batch sources. Only real-time ML delivers online predictions while at the same time consuming fresh data, i.e. real-time features from streaming sources.
During the summit, a poll was conducted on the best strategy for feature stores. Should you build a feature store, or buy one? Here are the results:

Despite the growing maturity of feature stores as a category, 50% of the surveyed companies prefer to build their own feature store rather than buy a commercial off the shelf solution, while only 35% prefer to buy, and 15% are still deciding. Companies who adopted a build strategy include Spotify, Wix, Uber, and DoorDash.
There’s also a hybrid approach using open source solutions like Feast or Hopsworks. This way, the company doesn’t need to reinvent the wheel, but can leverage all the work that was put into the open source project. At the same time, the company can still customize the open source solution, giving it the freedom and flexibility to adapt the feature store to their own unique needs. This can save a lot of time and development efforts compared to starting from scratch. Companies who choose this hybrid approach include Salesforce, Robinhood, Wildlife Studios, Twitter, and Udaan.
Build vs buy decisions depend on a number of internal factors, including where you are in the ML journey, the maturity of your ML platform and your team’s skills, the size of your scale, your unique needs, etc. However, as the category evolves and matures for both open source and commercial off-the-shelf solutions over the next several years, we expect more and more companies will opt to buy a feature store off-the-shelf or use a managed feature store in the cloud rather than building one on their own.
While a lot of emphasis is placed on the centralized nature of managing and storing features, modern feature platforms have additional capabilities including standardized communication and governance layers between teams across data engineering, data science, and ML engineering. This was evident through many stories shared at the summit. For example, Salesforce discussed how their company leverages the feature store to build a collaborative environment across teams, while Twitter described how they solve the challenges of collaboration and feature shareability across teams by centralizing the feature store.
In addition to collaboration, robust feature engines that ensure proper data preparation and minimize (or ideally prevent) challenges like data leakage are also hallmark capabilities required of feature platforms. Vaso Bank shared how their centralized feature store allows them to build a fraud detection system that avoids training and inference skew. This helps them maximize reusability, discoverability, and ensure consistency. Kaskada and Redis shared how they combine an extensible feature engine with time travel and feature storage with low-latency in-memory Redis to operationalize ML models from event-based data (see the slide below).
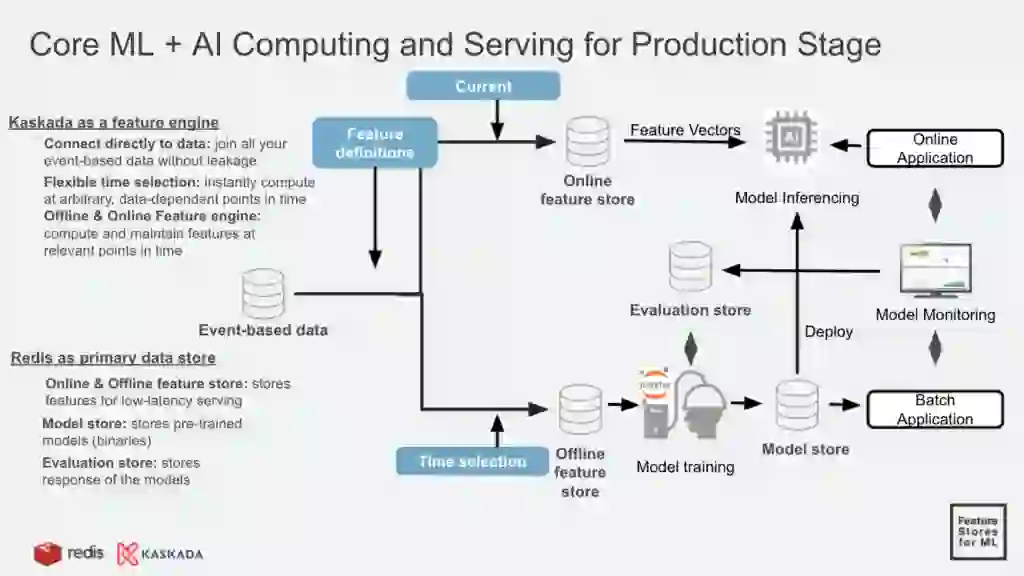
Modern feature platforms provide a solution that closes the entire loop. First, you have an online feature store for low-latency serving, then an offline feature store for training and batch inference. Model binaries get stored in a model store, and as the model is served for predictions, model monitoring is used to determine model effectiveness. This is captured into an evaluation store, which can then be fed back to the feature engine so that models can be updated when the features are no longer predictive (as referenced above). This architecture goes well beyond storage, and ensures ML features are live, fresh, and fast, enabling them to support low-latency serving, augmented vector predictions, and continuous re-training at low latency.
Another recurring theme throughout the summit was how to drive user adoption. Once you buy or build a feature store for your ML operations, how do you convince the data scientists and ML engineers to change their behavior and start using the feature store? To invest time in registering each feature? To share features that they would later need to maintain and support?
Introducing “killer features” for fast iterations like point-in-time joins and automated backfills is key, as explained in Spotify’s presentation, as well as making sure the feature store can address a wide range of ML use cases from batch scoring to near-real-time to real-time. But even more than that is instilling trust in the feature store. This trust is instilled, first and foremost, through feature store consistency. Despite the dynamic nature of the feature store environment (including the data, the features, and the models), it is critical that the feature store ensures consistency.
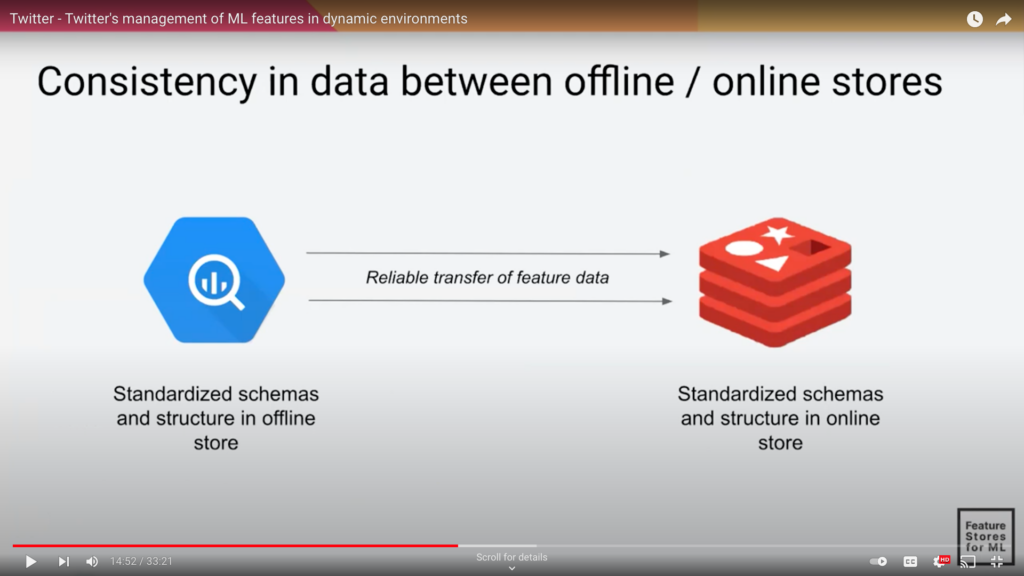
David Liu of Twitter talked about four levels of consistency, and that at the foundation level, the most important level (and the most talked about) is offline to online consistency, as depicted in the slide below by Twitter. The offline/online consistency is ensured at Twitter via a standardized schema and structure that is very rigid in the offline and online stores, so a reliable transfer of feature data is possible.
Other important aspects of feature stores that instill trust are:
Feature store as a category didn’t even exist just a few years ago, but it’s now a critical piece of data architecture that links the past with the present by combining data science models and real-world data. When you consider the incredible traction and advances it has made so far, it’s quite clear that the emerging concept of feature stores is here to stay.
Feature stores solve some of the hardest problems for machine learning operations, and are often mentioned as the cornerstone of MLOps. Looking into the future through Feature Store Summit, we saw interesting directions for features stores, and we look forward to seeing how these are going to materialize in the near future.
This wraps up our key takeaways from the first Feature Store Summit. We learned a lot from it and enjoyed co-presenting with Kaskada. We look forward to the next Feature Store Summit! Huge thanks for featurestore.org for organizing the event and see you next year!
—
Ready to test out Redis as a data store for your feature stores? Try Redis Enterprise Cloud for free!


