

The wave of cloud-based, real-time analytics and AI-driven applications is gaining momentum across multiple industries. Organizations want to empower their businesses and teams with emerging technologies, and AI and ML initiatives are front and center for many. We’re in the golden age of AI and ML. It’s becoming a core part of businesses around the world, and its importance has been accelerated by the COVID-19 pandemic. This informative and comprehensive post by William King, CTO and Co-Founder of Subspace, is about the future of real-time AI—and how the Redis technology is a driving force behind it. Drawing from foundational examples such as ML feature stores to more vertically specific applications like NLP for scientific and medical research, there are many ways Redis is being used to bring real-time to AI/ML use cases. And this is just the beginning.
Thanks for letting us share your insights, William!
—Taimur
————————————
Real-time application performance is a perspective exercise; you could view it either from the standpoint of user experience or corporate profitability, depending on audience. The end conclusion, however, remains: The world increasingly demands immediate data processing and responsiveness, and those who can provide it will enjoy greater success.
Real-time functionality is increasingly critical across industrial automation, Internet of Things (IoT) services, cybersecurity, multiplayer gaming, business communications, autonomous vehicles and aircraft, and countless other spaces. The requirements of artificial intelligence (AI) continue to apply and evolve across these areas.
Arguably the greatest challenge to real-time applications is achieving instantaneous performance with seamless, potentially vast scalability. As an analogy, think about vehicle speed relative to cargo capacity.
With only a passenger seat or two for capacity, a performance sports car achieves high responsiveness and speed. Could you get the same results from a loaded 18-wheel big rig?
This is what Redis has been dedicated to with its open-source, in-memory data structure store (also named Redis).
As the company describes it, Redis can be “used as a database, cache, and message broker” through various data structures. Redis provides for on-disk persistence, asynchronous replication, high availability, and automatic partitioning. Most importantly for this discussion, Redis achieves its real-time results by keeping datasets in memory. With traditional data architectures, a subset of the application’s total dataset—typically the “hottest” or most immediately needed data—resides in DRAM-based system memory, while the majority of data sits in slower but much less expensive disk (and/or SSD) storage. In-memory architectures swallow the bitter pill of higher costs to avoid time-intensive fetching of data from high-capacity storage media.
In April 2021, the company announced its new Redis 7.0 platform, which comprises several components and technologies. For example, rather than forcing users to pick between scalability and performance or data consistency across potentially globally distributed nodes, Redis 7.0 offers the best of both worlds. Part of this functionality depends on Redis’ “Active-Active” technology, which allows applications to deploy in any cloud model or location to keep data as close as possible to customers. When combined with the company’s AI inferencing engine, RedisAI, users can deploy real-time AI applications wherever AI features are stored, resulting in improved “AI-based application performance by up to two orders of magnitude”
For people who don’t work on databases every day, it’s easy to miss the significance of Redis 7. However, these advances illustrate how the world is racing toward real-time applications and highlight the technical underpinnings that make those advances possible. A better understanding of Redis can shed valuable light on the broader trends shaping tomorrow’s application environments.
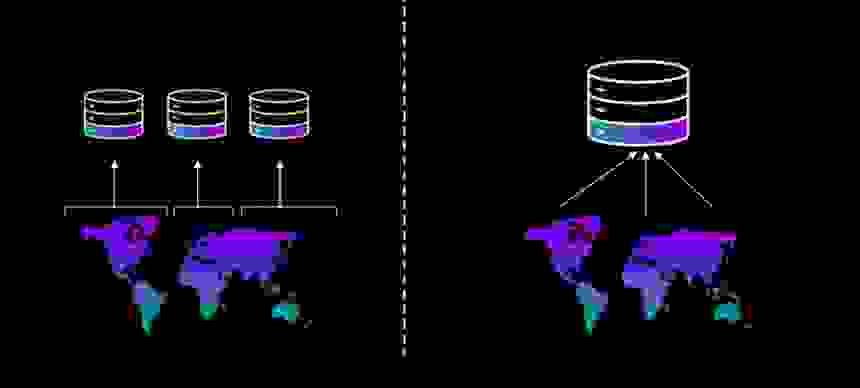
As noted, in-memory architecture favors real-time application performance because it keeps data in RAM, closer to the CPU. The architecture minimizes data travel time. Similarly, Redis’ Active-Active Geo-Distributed topology spans a global database across multiple node clusters. The system achieves inter-node consistency through a mesh of concurrent updating and data replication. Even if the majority of nodes in a database somehow fail, the remaining geo-replicated nodes will continue to provide uninterrupted service with full data integrity. This decentralized approach echoes the internet’s own architecture (designed for maximum network viability) while simultaneously allowing users to access data from the closest possible point and thus achieve near-local performance. Again, the idea is to minimize read/write data travel time without sacrificing consistency.
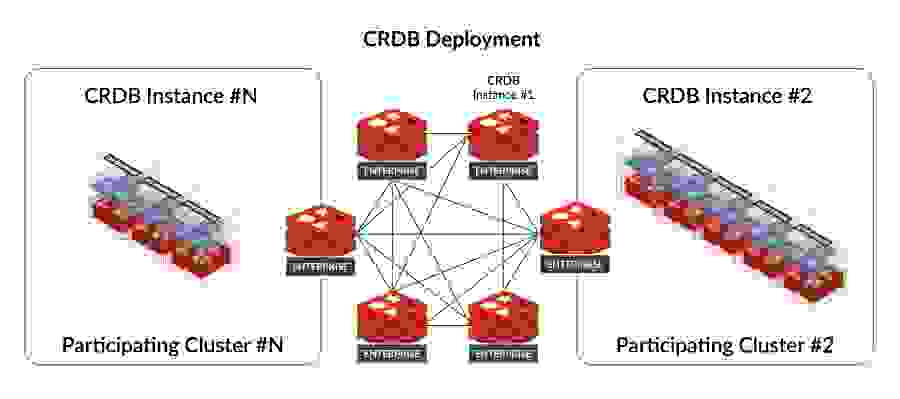
Redis has been talking up its Active-Active Geo-Distributed topology since at least 2018, but each year brings iterative improvement and expansion. For example, Redis 7.0 updated the platform’s implementation not only to accept the data interchange format JSON as a supported data type but also support JSON with Active-Active Geo-Distribution. With this addition, Redis goes beyond its usual asynchronous replication. Now, Redis facilitates local operational autonomy by enabling read/write execution without waiting for commits from any single centralized master. Not waiting for permission means faster operational performance.
The question remains:
**Now that this active-active geo-distribution technology exists, how can it radically improve conventional application approaches? **
Redis isn’t shy about touting how its ability to realize high throughput, sub-millisecond latency and global distribution is helping it oust the largest legacy database systems from their market entrenchment.
As Redis explains, traditional application architecture entailed having a primary database (DB) to handle most requests unless the request was particularly time-critical. Then, the application would resort to a secondary DB (like Redis) for functions such as caching and queueing. With its latest enhancements, Redis essentially said, “Yeah, our database can also do…everything. And then do it in real-time.”
The more Redis extends its database features and functionality, the more Redis will make its competition obsolete. Hence, Redis calls its approach “DBLess,” although the term is meant to go beyond databases in particular and instead convey the idea of a new, much more efficient technology than legacy approaches have produced.
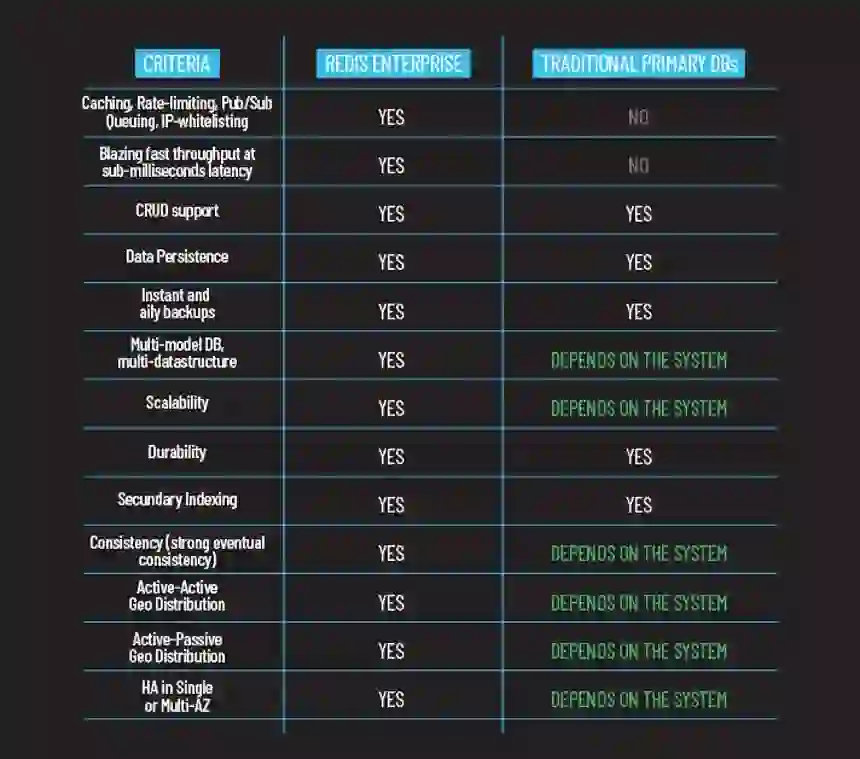
Redis believes that its real-time DBLess architecture offers a significant enough leap in solution value to disrupt major incumbents and potentially change markets.
In parallel with this DBLess push, Redis has bolstered support for feature store functionality in RedisAI. In short, a feature is a potentially useful tidbit contained in one or more raw data points. As you might expect when dealing with terabyte- to petabyte-scale datasets, organizing features for machine learning (ML) training can be grueling and incredibly time-consuming. A feature store serves as both a repository and a system for the automated input and management of features. If that sounds like something that might suit Redis, well, of course it is. Blending the ML models of RedisAI with a lightning-fast, globally scalable platform like Redis 7.0 will give the world a new way to accelerate toward real-time AI systems based on live, geographically disparate conditions.
Redis and AI also figured prominently in the company’s RedisConf 2021 Hackathon. Dr. Alexander Mikhalev was one of five Platinum Prize winners for his submission “The Pattern: Machine Learning Natural Language Processing meets VR/AR.” (Editor’s note: Check out The Pattern and other examples of what you can do with Redis on Redis Launchpad.) Mikhalev perceived a problem with the lack of proper review and vetting in modern medical sources, even referencing one interesting paper published in the American Journal of Biomedical Science & Research “claiming that eating a bat-like Pokémon sparked the spread of COVID-19.” (The purpose of the paper was to spotlight predatory scientific journals.) He used Redis AI and UX tools to turn documents into analyzed language that could then be searchable and visualized as three-dimensional graphs. The user then might explore those more intuitively in augmented or virtual realities.
Another Platinum Prize winner, Dustin Wilson, used multiple Redis tools to create a live view of the Helsinki metro system. (Editor’s note: Check out this app and other examples of what you can do with Redis on Redis Launchpad.) Users could click on any transport to trace its position and delay statuses for the prior two hours. The live view, which showed transports moving in real time (similar to Uber), was accurate to within five seconds. A different view allowed users to click on any neighborhood to see the current average speed and delay time of transports in that area.
The applicability of Redis to a dazzling spectrum of challenges was truly impressive. One Diamond Prize winner created an e-learning platform stocked with back-end metrics for educators. One Silver Prize winner created an RSS reader application, and another created a social network for movie buffs.
And we would be remiss not to mention the Gold Prize-winning top-down shooter from Janis Vilks. Notable for being the world’s first active-active geo-distributed arcade shooter, the game’s graphics make Atari’s 1977 shooter, Combat, look like a Monet. That’s innovation for you, and this is only a proof of concept of pretty interesting things to come.
While some of these applications appear simple, Redis continues to prove itself a capable platform for powering some of the world’s largest real-time applications. For instance, using a list data structure, Twitter uses Redis to store users’ 800 most recent tweets to help improve application responsiveness and scaling. Pinterest uses extensive Redis sharding to maximize resource utilization and break through caching bottlenecks found with prior systems when graphing data at scale. Malwarebytes uses Redis for security data ingestion, aggregation, and visualization, and U.K.-based energy company Utilitywise uses Redis to enhance performance and uptime for its IoT application. There are plenty of examples; the performance, scaling, and reach continue to push boundaries.
Organizations have long had to make tough choices around whether to have databases for structured (SQL) or unstructured (NoSQL) data. Fortunately, Redis has been at the forefront of settling the SQL/NoSQL dilemma by delivering the best of both worlds: flexibility for today’s data processing as well as the high level of consistency needed to scale. This all-in-one suitability makes Redis a stellar fit for the diverse needs of modern AI and ML, which need to operate within the entire spectrum of modern applications, even among the industry’s most demanding, cutting-edge organizations.
“The use of machine learning algorithms in simulations continues to grow to improve scientific research with efficiency and accuracy,” noted Benjamin Robbins, Director AI & Advanced Productivity, Hewlett Packard Enterprise. “By leveraging Redis and RedisAI in SmartSim, our new open-source AI framework which advances simulations that run on supercomputers, users can exchange data between existing simulations and an in-memory database while the simulation is running. The ease of data exchange helps unlock new machine learning opportunities, such as online inference, online learning, online analysis, reinforcement learning, computational steering, and interactive visualization that can further improve accuracy in simulations and accelerate scientific discovery.”
This press release featured a Forrester Consulting study that found:
40% of respondents believe their “current data architectures won’t meet their future model inferencing requirements.”
38% of leaders are developing “roughly a third” of AI/ML models on a real-time basis.
44% cite performance as a top challenge for getting models deployed.
The links between architecture, performance, and achievement continue to challenge today’s business innovators. No matter how fast a cluster is or how next-generation the decentralized data framework, network latency remains an inhibiting factor when working across the public internet. Subspace created a high-performance network that operates in tandem with the public internet specifically to solve these performance bottlenecks.
This type of low-level solutioneering to enable faster access to all kinds of data types appeals to both my technical and personal viewpoint. Technically, I like it when large obstacles like this start getting tackled, because it means that people are seeing the performance problems first hand and thinking about this new way the internet needs to operate.
Now, quite a large group of DevOps and network engineers are picking up their tools and getting to work on solutions. What comes after these types of problems get solved is a natural adoption curve towards a new way of doing things; I think we’re in the middle of that curve right now.
Personally, any organization who is working on enabling better access to this giant datastore we call the internet is doing good work, especially if they’re trying to utilize new architectures and technologies to do so. This is how innovation starts, and why it continues.
The interesting part about Redis is they’re pushing the boundaries of what we can achieve in real-time computing, and enabling stable access at the same time. I’ll certainly be keeping my eye on them to see what innovations come next.
See how Subspace can help you optimize and accelerate your real-time communication.
————————————
Ready to start your real-time AI journey? Try Redis Enterprise free.

