



Hello, Redis Stack
Learn more


Building multi-model applications with Redis Stack is surprisingly straightforward! Follow along with a tutorial that shows how to build a knowledge base in Python that incorporates powerful search features.
Companies produce an overwhelming amount of data daily. It’s a huge challenge to organize it, filter out obsolete information, and make it available whenever it is needed. That is not a trivial problem.
Making sense of data is a different task than storing it. Accomplishing that goal includes documenting the data’s organization as well as the process by which it is created, edited, reviewed, and published, with awareness of the relationship between editors and consumers.
Knowledge base systems serve as libraries of information about a product, service, department, or topic. In such systems, documents are dynamic assets that can be referenced, improved, classified, shared, or hidden from unauthorized users. Typical examples include FAQ databases, how-to guides, and onboarding material for new hires. A knowledge base should be tailored to a company’s needs, which means it needs to interface with existing tools and processes.
The internet made knowledge base systems popular. Documents could be structured and connected using hypertext, the core idea behind the internet itself. Organizing and linking content in such a way changed forever the way producers and consumers would create value out of knowledge.
In this article, I demonstrate how to use Redis’s data structures and search capabilities to build a web knowledge base platform with basic functionality. This project is well suited to use Redis’s powerful capabilities for real-time full-text searches and queries because it fulfills the main purpose of such systems: providing several methods to retrieve the information a consumer is looking for and as soon as possible.
This tutorial helps you build a knowledge base that can store and serve documents for typical use cases, such as customers who want to learn about a new product feature, troubleshoot a technical issue, or serve as a single, reliable source of truth for internal departments.
The project’s source code is available in a GitHub repository, licensed under the MIT license.
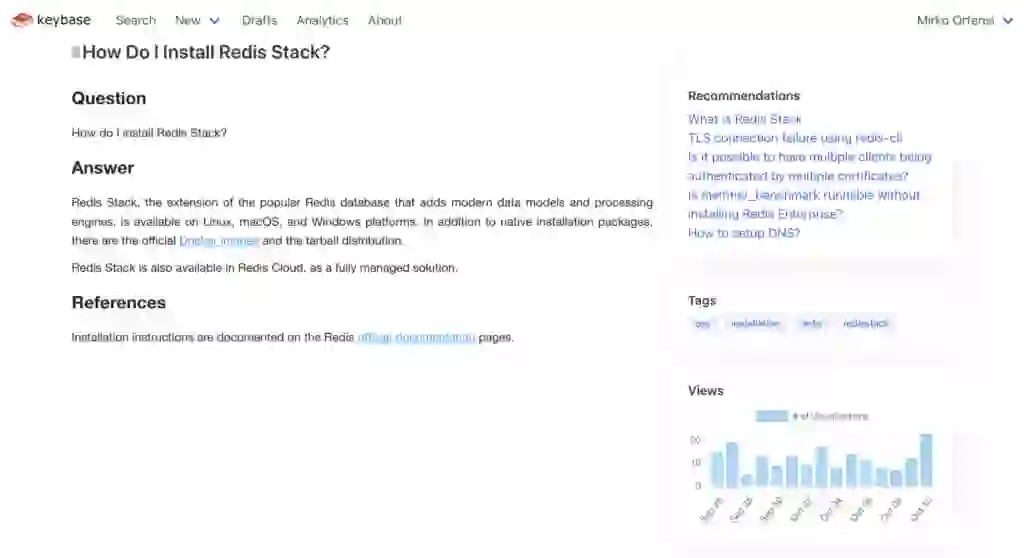
I named this project “Keybase,” and this is a preview of what it looks like:
In this tutorial, I use the following components to develop a working prototype:
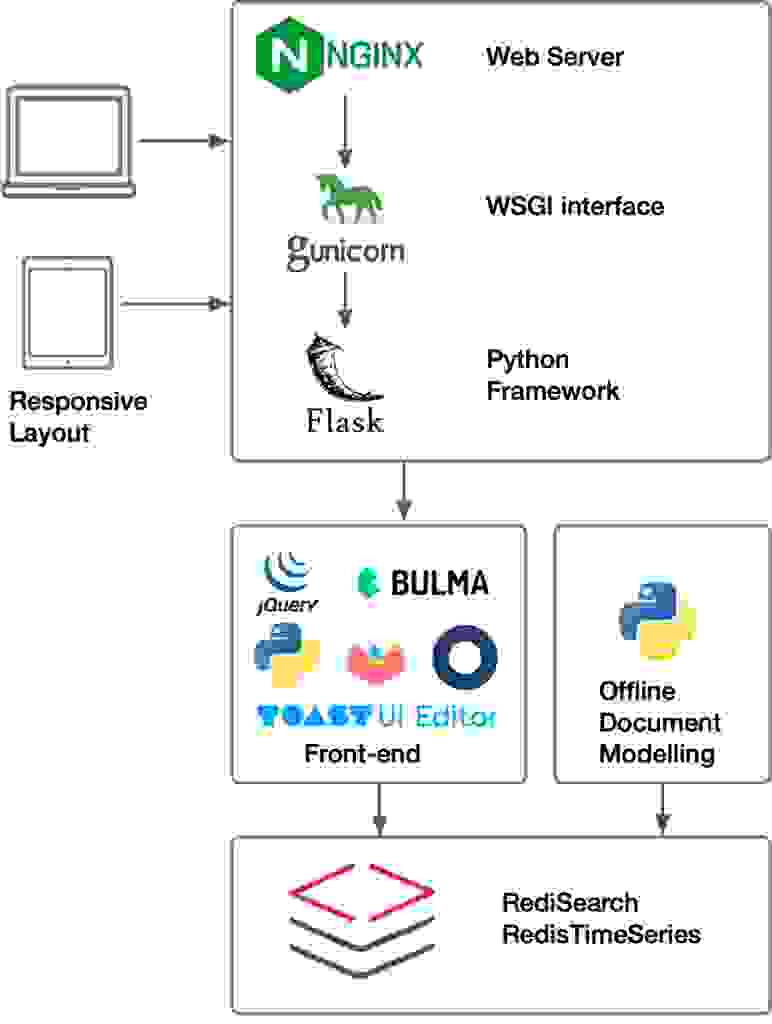
The popular Nginx web server is used together with Gunicorn, which implements the web server gateway interface and serves the Flask application.
The knowledge base backend is implemented as a Python application developed over the popular Flask framework. Flask provides good separation among the views. The application is implemented using the Jinja template engine and the controllers delivered by the Werkzeug WSGI toolkit. User authentication is based on Okta, the popular Identity as a Service platform.
The front-end is styled using the CSS framework Bulma; JQuery is the Javascript library for Ajax communications and user interface manipulation together with JQueryUI, and Notify.js is used for UI notifications.
An additional service, deployed as a cron job, indexes documents for document similarity recommendations. Document indexing is conveniently decoupled from the sessions in order to avoid impacting the user experience.
Finally, in the data layer, the project uses a Redis database plus two Redis modules: RediSearch and RedisTimeSeries, which in the tutorial, I use for document indexation and search, and analytics, respectively.
Documents in the knowledge base are modeled as Hashes. Here is how the data is stored:
HGETALL keybase:kb:9c6c48c2-eb5d-11ec-893a-42010a000a02
1) "update"
2) "1655154783"
3) "processable"
4) "0"
5) "tags"
6) "troubleshooting"
7) "state"
8) "draft"
9) "owner"
10) "00u5brr84hIXBoDRo5d7"
11) "name"
12) "How to Troubleshoot Performance Issues?"
13) "content_embedding"
14) "\xf5\xcc\x1e=D\x82\xd0\xbc\x81\x90\xfa\xbc5&\xab<\x98\xaa\xb0=;`\xf2\xbc\xc1\x00Z\xbb9\xe4\xee\xbc\xee\x88\xce9\xd8^\x80\xbclX\xe0\xbc\a\xaf\x9a\xbdTR\xd8<\xb6Yv=w6^=\x1ftd\xbd M\x19\xbd&BP=\x04\x92\\\xbd@\xb6P=\xd7\xce\x12\xbc\x11" [...]
15) "creation"
16) "1655154783"
17) "content"
18) "Checklist to investigate performance issues.\n\n1. Check slow log looking for\xc2\xa0 `EVALSHA`, `HGETALL`, `HMGET`, `MGET`, and all types of `SCAN` commands. Lower slow log threshold to capture more slow commands. You can configure the threshold using `CONFIG SET slowlog-log-slower-than <THRESHOLD_MICROSECONDS>`\n2. Avoid the" [...]
The Hash data structure stores:
Got all that? We’re ready to dive into the Keybase features and how to implement them.
We are extremely proud of the Redis database’s powerful real-time search features; this tutorial lets us show it off.
You probably think of search as a brute-force lookup, but in fact, there are no slow scans when we use RediSearch indexing capabilities. The options we cover briefly here are:
For a more in-depth explanation of search functionality in Redis, see an introduction to the RediSearch module.
RediSearch creates the index using this syntax:
FT.CREATE document_idx ON HASH
PREFIX 1 "keybase:kb"
SCHEMA name TEXT
content TEXT
creation NUMERIC SORTABLE
update NUMERIC SORTABLE
state TAG
owner TEXT
processable TAG
tags TAG
content_embedding VECTOR HNSW 6 TYPE FLOAT32 DIM 768 DISTANCE_METRIC COSINE
The schema of the index document_idx enables the three types of search using the corresponding field types:
The search input field in the web interface is used to perform a full-text search, which looks at the name and content of the knowledge base documents.
Consider this example of a real-time full-text search using the redis-py client library. It performs the search on the query string received from the client. Note that this command excludes documents in draft state; such documents must be kept hidden and not included in the output:
connection.ft("document_idx")
.search(Query(query + " -@state:{draft}")
.return_field("name")
.return_field("creation")
.sort_by("creation", asc=False)
.paging(offset, per_page))
This neat code sample performs a real-time full-text search and returns a batch of per_page documents starting from the specified offset (useful to paginate documents in the UI). It fulfills the search criteria specified: all the documents that satisfy the query the user provided in the input field, it removes the documents that are in draft state, and it sorts the documents by creation timestamp.
An example of real-time querying by tag in Python, where the search is combined with the filter on the tag and also excludes documents that are in draft state, is the following, which returns all the documents tagged with the “troubleshooting” tag:
connection.ft("document_idx")
.search(Query("@tags:{troubleshooting} -@state:{draft}")
.return_field("name")
.return_field("creation")
.sort_by("creation", asc=False)
.paging(offset, per_page))
This snippet of code is a pure real-time query, including all the documents tagged using the troubleshooting keyword but also excluding those documents that are not public and still classified as private drafts. This syntax uses the indices on several fields in order to filter, order, and paginate the results.
You’re surely familiar with this sort of search, especially on e-commerce websites. Personalized recommendations direct users to similar content with prompts such as, “You may also be interested in reading” or “people who bought this also purchased. “
This sample application doesn’t need to increase product sales, as the knowledge base site has nothing to sell, but we do want to provide users with meaningful recommendations.
You can add recommendations using the VSS feature of Redis real-time search.
If you haven’t used this type of search in your projects, start with Rediscover Redis for Vector Similarity Search.
The short instructions: To use the VSS feature, you first create a model, then store it, and finally query it.
The core concept behind recommendations using VSS is to transform the document content into its corresponding vector embedding. The vector is the entity that describes the document and is compared against other vectors to return the best matches. The vector embedding is stored in the Hash data structure (in the content_embedding value).
In this example, we use the Python SentenceTransformer library to calculate the vector embedding using the all-distilroberta-v1 model (from the Hugging Face data science platform) as follows.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1')
embedding = model.encode(content).astype(np.float32).tobytes()
In this sample, the content of the document is vectorized and serialized in binary format, the format that VSS accepts. This operation is triggered twice: at document creation time and for any subsequent document update. In particular, when updating the document content, the vector embedding needs to be recalculated, or the index becomes obsolete and returns imprecise results. To trigger an offline vector embedding recalculation, as described in the architecture, it is sufficient to activate the processable flag and periodically list those documents whose vector embedding needs to be refreshed and then process them. For example:
rs = connection.ft("document_idx")
.search(Query('@processable:{1}')
.return_field("content")
.return_field("processable"))
if not len(rs.docs):
print("No vector embedding to be processed!")
sys.exit()
model = SentenceTransformer('sentence-transformers/all-distilroberta-v1')
for doc in rs.docs:
# Recalculate the embedding and store it
Using the same syntax as in the previous tag search example, this command executes a search to include those documents with the tag processable set to 1. Documents returned by this search get the associated vector recalculated and stored.
Once the vector embedding is generated, you can store it as usual in the document Hash data structure ((in the content_embedding field).
Finally, set the processable flag to zero. No further update is needed to the vector embedding until the next document change.
doc = { "content_embedding" : embedding, "processable":0}
connection.hmset("keybase:kb:{}".format(key), doc)
Every time the user sees a document, the sidebar proposes a list of recommendations. That means the Keybase application has to discover what the recommendations are.
To accomplish that, we fetch the vector embedding from the Hash of the document currently presented (that is, the one the user is looking at).
current_doc_embedding = connection.hget("keybase:kb:0373bede-d2c1-11ec-b195-42010a000a02", "content_embedding")
The hget returns the value associated with the field content_embedding.
To retrieve the most similar documents, compare the vector to the rest of the stored vectors.
q = Query("*=>[KNN 6 @content_embedding $vec]")
.sort_by("__content_embedding_score")
res = connection.ft("document_idx")
.search(q, query_params={"vec": current_doc_embedding})
for doc in res.docs:
# Show the documents in the box
In this example, the query is configured to execute the powerful vector similarity search to return the six most similar documents by retrieving the k-nearest neighbors (KNN).
For more VSS syntax examples, see the client library documentation.
Every business application needs to establish who can and cannot access the software. For our knowledge base authentication, we use the popular Identity as a Service platform Okta. Users are stored in the Redis database as Hashes prefixed by the string “keybase:okta:”. I tested the integration with the Okta Developer Edition.
Here’s an example of a user profile:
127.0.0.1:6380> HGETALL keybase:okta:00u5clwmy9dGg6wPC5d7
1) "name"
2) "Test Account"
3) "given_name"
4) "Test"
5) "email"
6) "test@account.com"
7) "group"
8) "viewer"
9) "signup"
10) "1655510121.2172642"
11) "login"
12) "1655510121.217265"
To search the knowledge base users, we create an index on the user Hash data structures:
FT.CREATE user_idx ON HASH PREFIX 1 "keybase:okta"
SCHEMA
name TEXT
group TEXT
The group formalizes the implementation of Role-Based Access Control (RBAC). I created three user types for this example application, although additional roles can be added. The current roles are:
Finally, it is also possible to bookmark documents by storing their IDs in a collection. Once more, the Hash is the best option because of its flexibility; you can store the document ID and also a personal comment on the bookmark.
Here’s an example of a collection for the authenticated user:
127.0.0.1:6380> HGETALL keybase:bookmark:00u5brr84hIXBoDRo5d7
1) "efb73056-d2c0-11ec-b195-42010a000a02"
2) "May solve several customer cases"
3) "0373bede-d2c1-11ec-b195-42010a000a02"
4) "TLDR"
5) "2f678872-d2c1-11ec-b195-42010a000a02"
6) ""
Many business scenarios require the organization to monitor a knowledge base’s activity. For instance, you might want to evaluate document popularity by subject area, minimize repeated questions, or mine for new feature ideas.
The RedisTimeSeries capability is a natural choice for analytics functions because it is optimized to store and aggregate large amounts of data.
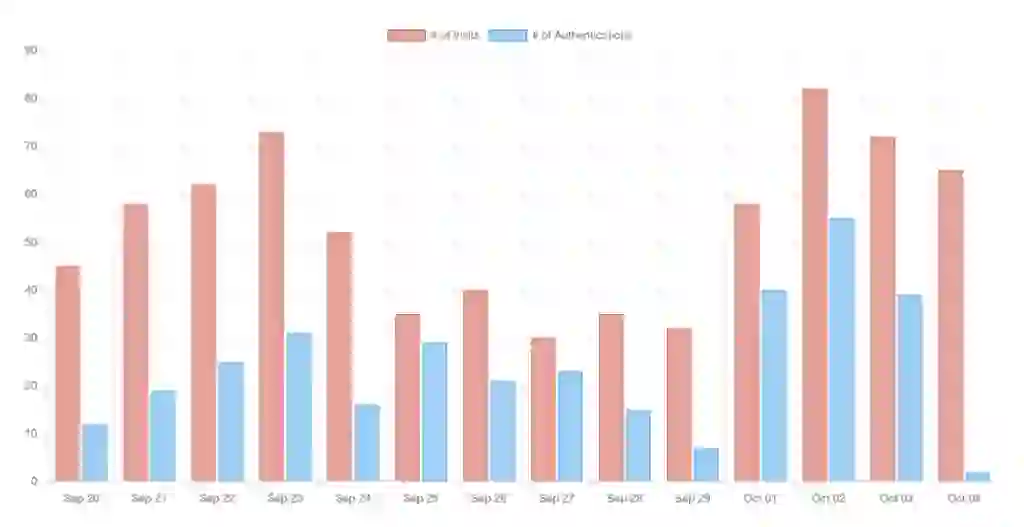
The code to track the overall visits to the knowledge base, as an example, is:
connection.ts().add("keybase:visits", "*", 1, duplicate_policy='first')
This code calculates the visits in the last month, aggregated by day. It is formatted as JSON, ready to feed to the Chart.js visualization library:
bucket = 24*60*60*1000
duration = 2592000000
ts = round(time.time() * 1000)
ts0 = ts - duration
# 86400000 ms in a day
# 3600000 ms in an hour
visits_ts = connection.ts()
.range("keybase:visits", from_time=ts0, to_time=ts, aggregation_type='sum', bucket_size_msec=bucket)
visits_labels = [datetime.utcfromtimestamp(int(x[0]/1000)).strftime('%b %d') for x in visits_ts]
visits = [x[1] for x in visits_ts]
visits_graph = {}
visits_graph['labels'] = visits_labels
visits_graph['value'] = visits
visits_json = json.dumps(visits_graph)
Then, to render the chart in the Jinja template, use this Javascript:
var data_js = {{ visits_json|tojson }};
const ctx = $('#visits');
const myChart = new Chart(ctx, {
type: 'bar',
data: {
labels: JSON.parse(data_js).labels,
datasets: [{
label: '# of Visits',
data: JSON.parse(data_js).value,
fill: false,
backgroundColor: 'rgba(203, 70, 56, 0.2)',
borderColor: 'rgb(203, 70, 56)',
borderWidth: 1
}]
},
options: {
responsive: true,
maintainAspectRatio: true,
scales: {
y: {
beginAtZero: true
}
}
}
});
The chart is rendered in an HTML canvas element.
<canvas id="visits"></canvas>
This method lets you monitor additional metrics, such as views per document or user activity. You can use Redis time series aggregation features to compute averages, variance, standard deviation, and all kinds of statistics.
To round out the sample application, we need to ensure that the knowledge base can be managed.
The administrator can grant or revoke roles to users with the RBAC policy. Access control is implemented using Python decorators and a custom User class. (Refer to the repository for details.)
For example, the signature of a protected method to perform backups might be:
@admin.route('/backup', methods=['GET'])
@login_required
@requires_access_level(Role.ADMIN)
def backup():
# Take the backup
You can generate Redis database backups natively using the asynchronous BGSAVE command. In addition to the native backup method, the knowledge base also implements logical data import and export routines. Exporting data is achieved by iterating the Redis keyspace with the non-blocking SCAN command in batches of 20 elements.
while True:
cursor, keys = conn.scan(cursor, match='keybase*', count=20, _type="HASH")
for key in keys:
hash = conn.hgetall(key)
# Do something with the data
# ...
if (cursor==0): # Exit condition when the iteration is over
break
This project is a proof-of-concept to showcase Redis features when employed as a primary database. The source code in a GitHub repository, under the MIT license, is shared for demonstrative purposes and is not to be used for production environments. However, the repository can be consulted, cloned, and/or forked and all the examples reused to better understand the search and indexing features discussed in this article. I encourage you to do so.
I developed Keybase to demonstrate how easily Redis can replace a relational database for these types of web applications. And it was surprising to discover how rewarding it was to model the data. Hash data structures are neat and compact! I was also happy to learn that Redis’s unique features for similarity searches and time series provide full out-of-the-box solutions to standard problems that otherwise would require multiple specialized databases. Building multi-model applications with Redis Stack is surprisingly straightforward!
You could add many additional features to complement this project, such as improving the authoring experience with multi-user drafts, revisions, and feedback collection. This project could also be integrated with Slack, Jira, ZenDesk, or any platform that organizes teamwork. Additional features such as scanning the documents’ sensitive words, detecting broken links, and user auditing capabilities could be designed to take this software from the utility to the enterprise level.
I invite you to clone or fork the Keybase repository and set it up. You can run it on your laptop with a local Redis Stack installation (or a free Redis Cloud database) and in the context of a Python environment. I hope you have fun with it!

