

It’s not just latency that’s the problem when we discuss the maximum delay between the time a client issues a request and the time the response is received. How do you know the latency, or the slowness, isn’t actually an outage? Or that it doesn’t result in user abandonment, another form of “outage”?
I’ll use the examples of real-time inventory and fraud detection to illustrate how you can reduce latency and, by extension, eliminate outages.
First, think about real-time inventory specifically in the context of the pandemic. We evolved our shopping habits during COVID-19; when we had to go into the store, we thought long and hard about it, and we made sure that what we needed was actually in stock. Our plan was to go to one store, get in, get our stuff, and get out.
But if the store’s inventory system or the public view of it is slow, I may falsely assume what I’d like is available and simply go to the store. If what I’d like isn’t there, I’m going to leave; after all, I was there for a specific reason. I may also stop by customer service to complain not just about the slow system but also the lack of inventory. The result is lost revenue as well as lost time complaining. In this case, latency in the inventory update is effectively an outage for that system.
Now let’s move on to fraud detection. In a nutshell, fraud systems operate on relatively static data and were developed before there was a need to incorporate real-time data as part of the risk calculation. If we think about a digital identity or user profile, this idea of verifying the customer’s identity can be thought of as a mix of static data (e.g., mailing address) and dynamic data (e.g., recent purchases). Most likely, that static information isn’t so secret due to data breaches. Bad actors know this and can develop strategies to defeat common fraud detection strategies.
The fraud may eventually be detected but only after the transaction is already completed. In effect, that latency, that inability to incorporate real-time data, means the fraud detection system was unavailable. It suffered an outage.
At this point, it would be perfectly relevant for you to say, “Wait a minute. We keep modernizing our architectures (as Figure 1 below indicates). How can this still be an issue?”
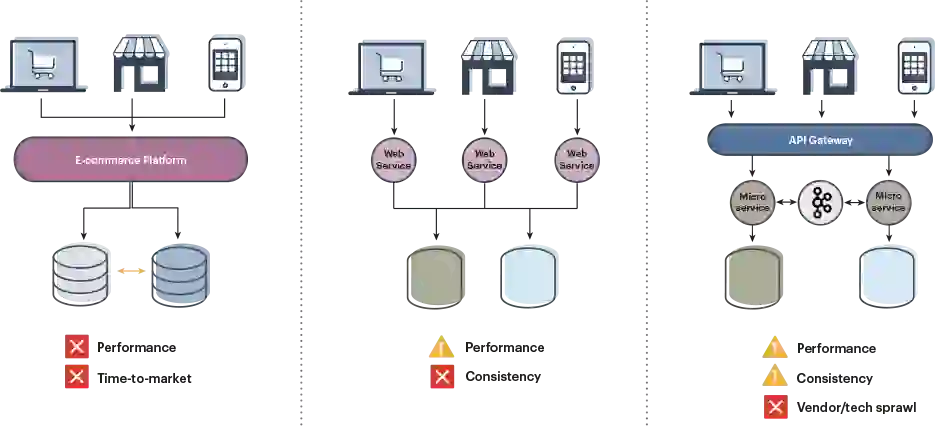
I would suggest that, as we’ve evolved architectures, we’ve solved for availability and delivering on an SLA of five nines. We started out with relational databases, then broke up the data into multiple relational databases for performance, and then introduced data-type-specific stores to further improve performance.
But multiple data stores also introduce multiple copies of data and create consistency challenges. We were able to address this with event-driven architectures using a message bus such as Kafka. We, therefore, accomplished our five-nines of availability, and we’re mitigating the challenge of data consistency across all the systems at the cost of complexity. But we haven’t addressed latency overall. Meanwhile, consumers are more frequently using mobile devices to better inform themselves, all of which points to a need for speed more than ever before.
If we turn our focus in this event-driven microservices architecture to the data store, I would suggest there are many tools to solve the latency problem. As a Solutions Architect at Redis, I can speak to the tools I use that operate at sub-millisecond latency in this type of architecture. Redis Enterprise is an in-memory database platform that maintains the high performance of Open Source Redis and adds enterprise-grade capabilities for companies running their business in the cloud, on-prem, and with hybrid models. This blog post provides further details about how Redis achieves real-time performance with linear scaling to hundreds of millions of operations per second.
For instance, we can reduce the overall data store complexity if we take advantage of Redis Enterprise in our event-driven microservices architecture (see Figure 2).
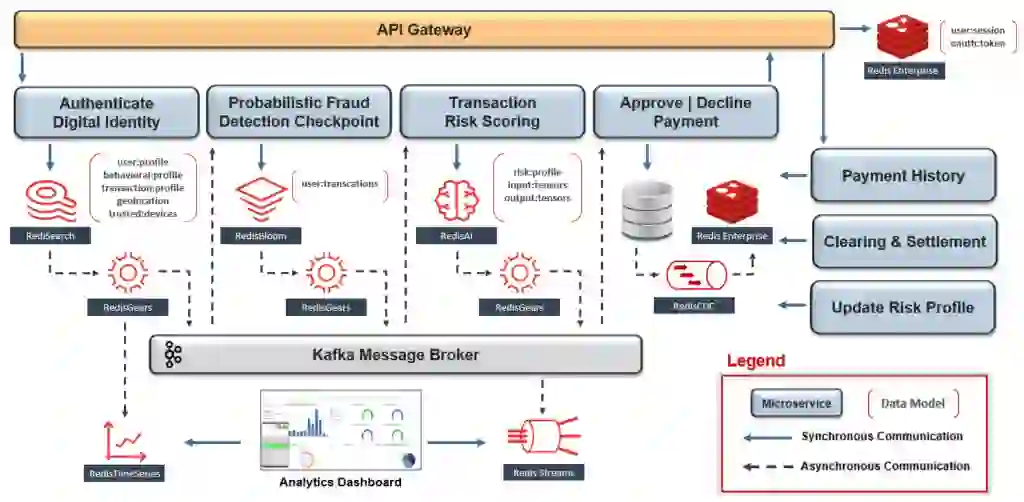
Now as a highly performant system, we address our need for real-time data by incorporating dynamic information into the risk calculation without compromising the need to complete this step inline with the transaction. Similarly, we can return to the is-what-I-need-at-the-store problem with real-time inventory, and, assuming there is only one store or everything is centralized, we can be confident that latency will not create false results.
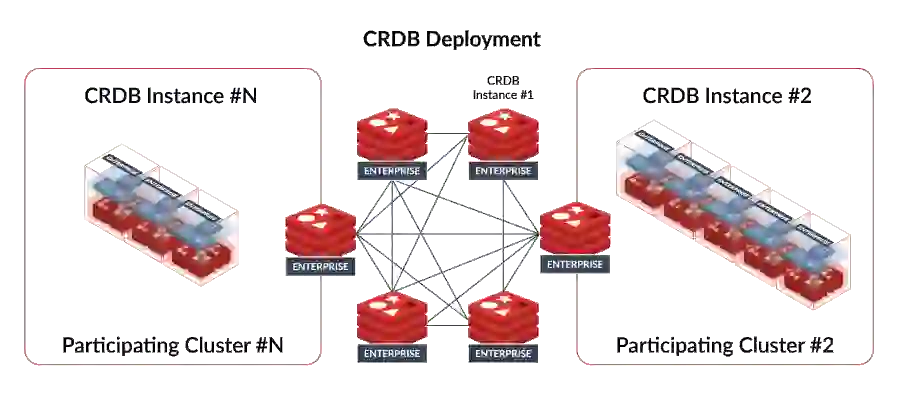
Which takes us to the next level: What happens when there is more than one store and there is no centralization but instead multiple inventory systems? If we do nothing, we have a new level of consistency challenge. Fortunately, we can address this with Active-Active Geo-Duplication and create master data across the entire set of systems. Active-Active, implemented as a conflict-free replicated database, is illustrated in Figure 3. It refers to using at least two data centers that each can service an application at any time and deliver application accessibility even if parts of the network or servers fail unexpectedly. See Active-Active Geo-Distribution (CRDTs-Based) for a deeper dive.
Unfortunately, if my applications are not co-located with the data, I’m still facing an average of 100ms of latency between where the data is needed and where the data lives (see Figure 4 below); latency can still be the source of an outage.
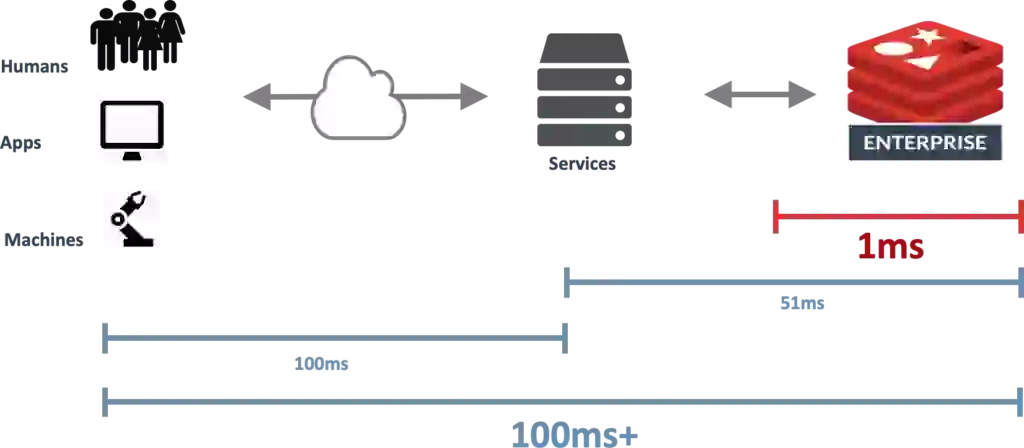
We can solve this challenge by bringing the data closer to where it is being used. If the public cloud is too far away at 100ms, then I leverage network edges like Verizon 5G Edge and AWS Wavelength Zones and reduce the logical distance between the application and the data to 50ms (see Figure 5 below).

Our distributed system is now modernized with an event-based microservices architecture where we have reduced the data store complexity, created data consistency with Active-Active Geo-Duplication, and have reduced latency to meet real-time requirements. Furthermore, I can bring that architecture closer to where it’s being consumed and reduce the impact of latency as a source of an outage. I can leverage network edges with Active-Active Geo-Duplication so that I am now consistent in ensuring everywhere the data lives is close to where it is being used.
Circling back to where we started with real-time inventory and fraud detection, this translates into happy customers who have confidence the items they want to buy will be in the store when they visit. It means businesses keep their customer retention costs down with reduced support interactions, and financial institutions mitigate losses from fraud, as well as manage their costs from real-time transaction analysis. Latency—as well as the risk or perception or reality of an outage—is minimized.
Want to try this out? This 5G Edge Tutorial is a good starting place. Interested in learning about more modern approaches to reducing latency in complex, distributed systems? Read our ebook linked below.

About Robert Belson
Robert joined Verizon’s Corporate Strategy team in October 2019 and is principally focused on leading their Developer Relations efforts for 5G Edge, Verizon’s edge computing portfolio. In this capacity, he serves as Editor-in-Chief of their corporate engineering blog, designs developer tutorials & training modules, and works with large enterprise customers to solve their business challenges using automation, hybrid networking, and the edge cloud. Prior to Verizon, he served as a Network Architect for a blockchain infrastructure project, supporting a number of network planning initiatives to mitigate cybersecurity risks.



