




High Availability Architecture Demystified
Learn more


A lot happens behind the scenes of a Redis Enterprise cluster. The proxy masks all that activity from the database clients.
Most developers start small when they build an application, using a simple Redis open source (Redis OSS) database, even when they know the software will become part of a complex system. In the beginning, using the database is pretty straightforward. It has a single endpoint, to which the application connects and starts sending requests. That’s about it.
The challenge starts when the Redis application needs more, such as scaling and high availability. You can use Redis OSS Cluster and Redis Sentinel for that purpose. However, it requires the developer to maintain the database topology and handle the practicalities of scaling. In other words, you have to write more code. At the enterprise level, this can quickly become complex.
Redis Enterprise addresses those complexity issues by removing extra work. Whether you start at the enterprise level or migrate from Redis OSS, we designed it to excel at a large scale while keeping it simple for applications to use the database.
In this post, we cast light on Redis Enterprise Proxy. We show common Redis cluster scenario examples, demonstrating how the proxy mitigates topology changes. Finally, we share benchmark numbers that demonstrate the proxy’s efficiency.
Redis Enterprise Proxy is an entity with negligible latency that mediates between applications and the database. It exposes the database endpoint to database clients while masking behind-the-scenes activities that the Redis Enterprise cluster performs. This allows developers to focus on how an application is using the data, instead of worrying about frequent changes in database topology.
The proxy employs a multi-threaded architecture. It can easily scale up by using more available cores. It is designed to cope with high traffic by using multiplexing and pipelining. When thousands of clients are connected to Redis Enterprise simultaneously, the proxy consolidates all of the incoming requests into a set of inner pipelines and distributes them to the relevant database shard. Net result: Requests are processed much faster, allowing high throughput with low latency.
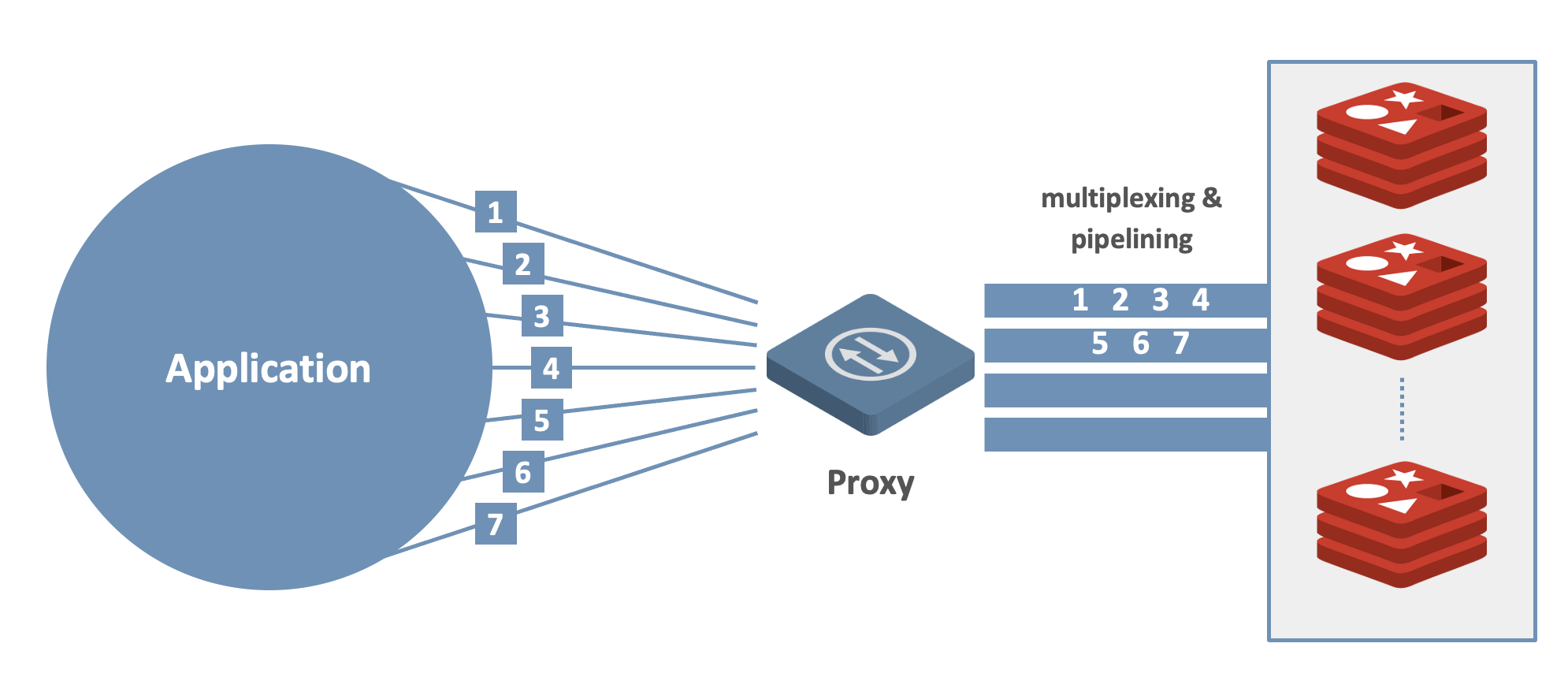
What’s all this mean in practical terms? Let’s look at a few common cluster-level scenarios that result in topology changes. We show how such changes remain hidden behind the proxy, which keeps exposing the same database endpoint to users as before. From the developer’s perspective – yours – this means less coding and a smooth migration from Redis OSS to Redis Enterprise.
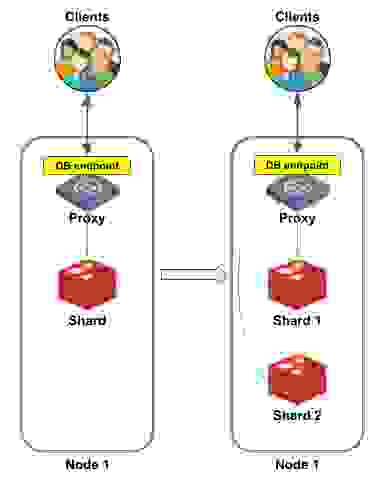
Whenever a database shard reaches a certain (predefined) size, Redis Enterprise can scale it. Scaling is accomplished by launching a new Redis instance and moving half of the hash slots from the original shard to the new shard. This allows the throughput and performance of the database to increase linearly.
There are two ways to scale a database in Redis Enterprise:
Figure 2 shows an example of a single-shard database being scaled–up into a two-shard database. On the left side (before scaling), you can see a single node containing the single shard. On the right side (after scaling is complete), the database is re-sharded. Now Shard 1 and Shard 2 are located in the same node, each holding half of the hash slots.
Does scaling-up change the way clients connect to the database? No, it doesn’t. Clients continue to send requests to the same database endpoint as before, letting the proxy take care of forwarding each request to the appropriate shard.
Note that this is different from the Redis OSS cluster, in which the clients connect to each shard separately, and thus must be aware of the cluster topology.
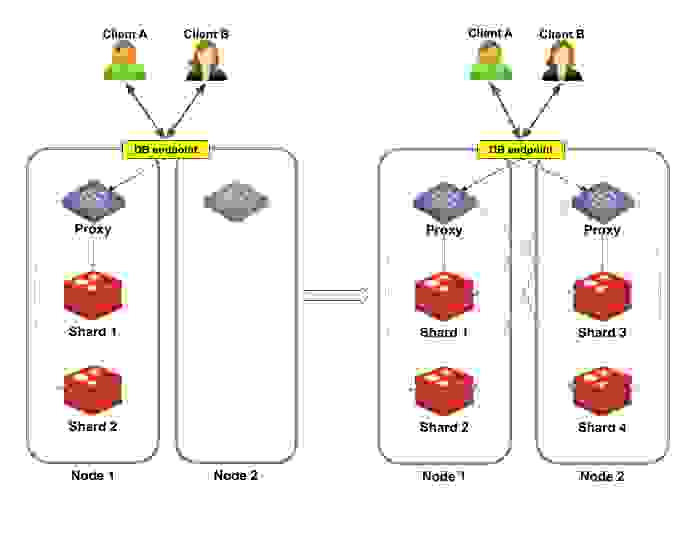
In contrast, consider what happens when we scale-out a database while using a multi-proxy policy. In this situation, we have multiple proxies running behind the same endpoint.
(Note that with Redis Enterprise you can also scale-out a database while using the OSS Cluster API. In that case, however, each proxy has its own endpoint.)
Figure 3 shows an example of a two-shard database being scaled-out into a four-shard database. A new node is added to the cluster on the left side, containing a still inactive proxy. After the scale-out is complete, Shard 1 and Shard 2 are located in Node 1, and Shard 3 and Shard 4 are located in Node 2. Both nodes now contain active proxies.
However, scaling-out does not change the way clients connect to the database, as these changes are all transparent to the clients. The databases continue to send requests to the same database endpoint as before. The proxy that handles each request forward those requests to the relevant shard.
A key aspect of Redis Enterprise’s high availability is automatic failover, which relies on data replication. When a failure is detected within a Redis Enterprise cluster – whether it’s a database shard outage or an entire node failing – the cluster is designed to self-heal in a matter of seconds.
The healing process is performed by the cluster manager, and it usually requires database topology changes inside the cluster. The proxy is notified and adjusted according to the new topology.
From the database clients’ perspective, nothing changes. Clients continue to use the same database endpoint as before since the topology changes are internal and are hidden behind the proxy.
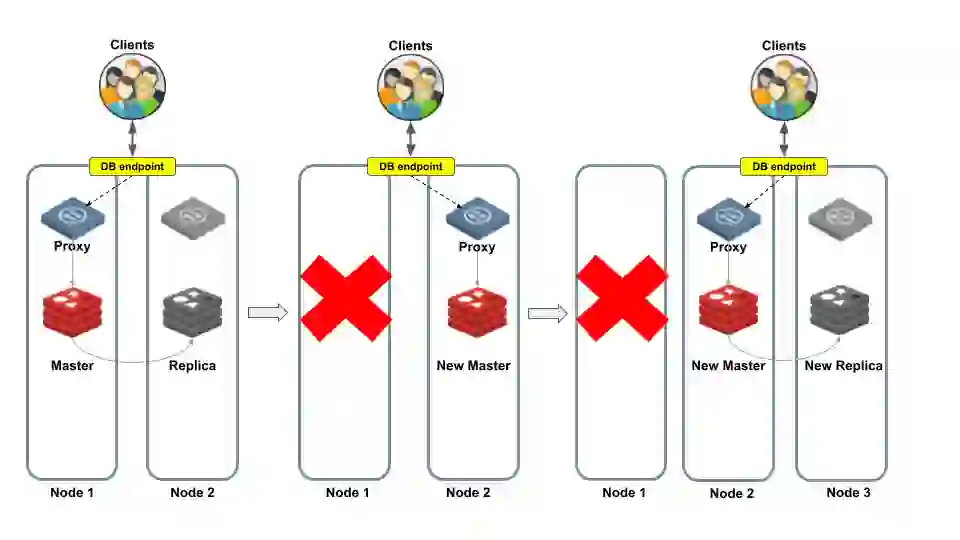
Let’s take a look at two failover examples.
On the left side of Figure 4 is a master shard in Node 1, and its replica is in Node 2. The proxy sends all client requests to the master shard, which continuously synchronizes data changes with its replica. So far, so good. But what happens when things go wrong?
In case of a master shard failure, the Redis Enterprise cluster manager promotes the replica shard to become the master shard. The proxy now redirects incoming requests to the new master shard, letting the clients continue as usual. The last step is to create a new replica shard (shown on the right side of Figure 4).
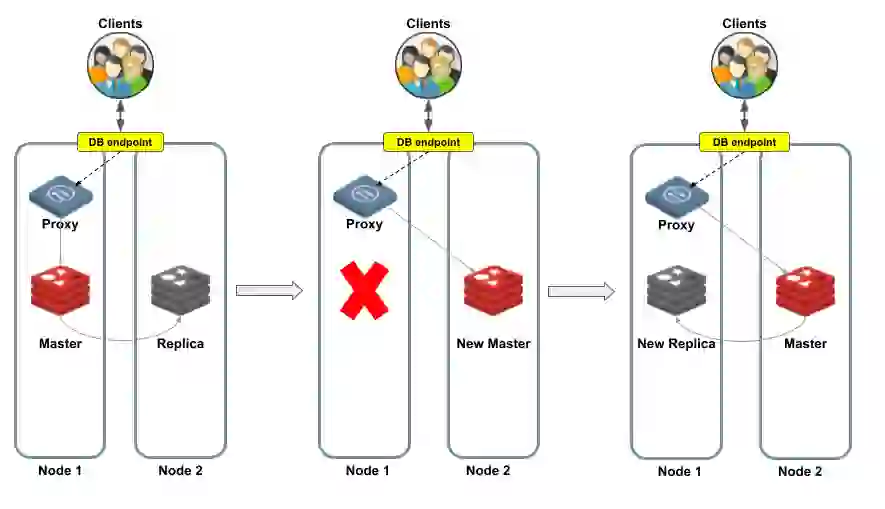
In this example, the entire node fails, which includes both the master shard and the proxy. Database clients are disconnected.
However, once the Redis Enterprise cluster manager completes the failover process, clients reconnect to the same database endpoint as before and continue as usual. From the developers’ and operations point of view, there is no need to make any changes, because the cluster failover mechanism assigns the same endpoint to a different proxy.
Figure 5 illustrates the process when Node 1 fails. The proxy of Node 2 becomes active and Redis Enterprise promotes the replica to become the master. The database is now available again, so clients can reconnect without being aware of this topology change. The cluster manager also finds a healthy node (Node 3), in which Redis Enterprise creates a new replica shard.
The proxy certainly simplifies things for database clients. But how fast does it happen? To examine its efficiency, let’s see some benchmark numbers.
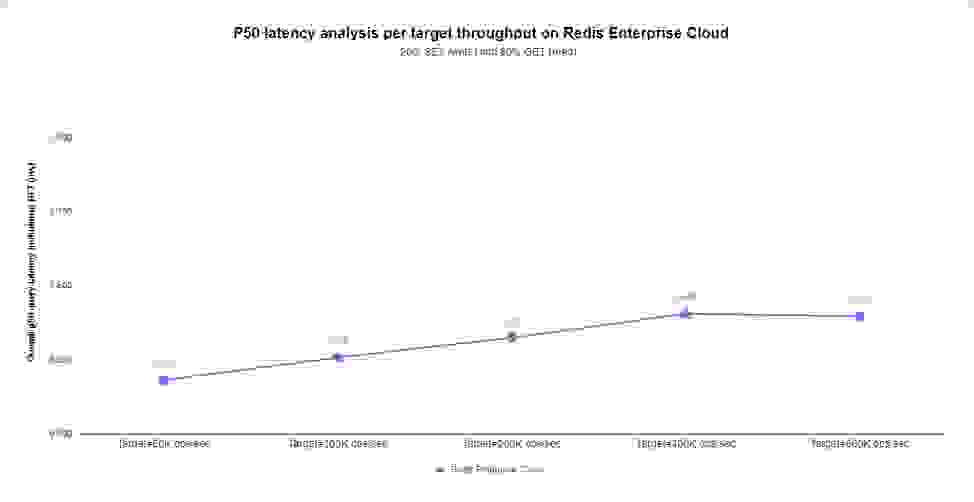
To benchmark latency, we used a single endpoint Redis Enterprise Cloud cluster. We executed a common scenario containing a mixture of 20% SET (write) and 80% GET (read) commands.
We created one database with a memory limit of 5GB and we chose five throughput targets: 50K, 100K, 200K, 400K, and 800K operations per second (ops/sec). For each configuration, Redis Enterprise Cloud selects the appropriate cloud instance to use, making sure that the cluster has sufficient resources at a minimal cost.
The following results demonstrate just how fast Redis Enterprise is. The benchmark maintains sub-millisecond median (p50) latency for all target throughputs. In some cases, it achieves sub-millisecond p99 latency.
| Target throughput (ops/sec) | Number of client connections | Number of shards | p50 latency per connection (msec) | p99 latency per connection (msec) |
| 50,000 | 2000 | 2 | 0.182 | 0.317 |
| 100,000 | 2000 | 4 | 0.258 | 0.588 |
| 200,000 | 2000 | 8 | 0.325 | 1.184 |
| 400,000 | 2000 | 16 | 0.406 | 2.791 |
| 800,000 | 2000 | 32 | 0.398 | 2.907 |
We at Redis believe in the power of simplicity. That’s why we designed Redis Enterprise as the best option when moving from Redis OSS to the enterprise level.
Try Redis Enterprise Cloud or download the latest Redis Enterprise Software to start a free trial.

