AWS I3 instances are x2.6 faster and 80% cheaper with Redis Flash
Learn more


Redis on Flash works with Redis Enterprise for Kubernetes. That’ll speed up your software – and save your company money.
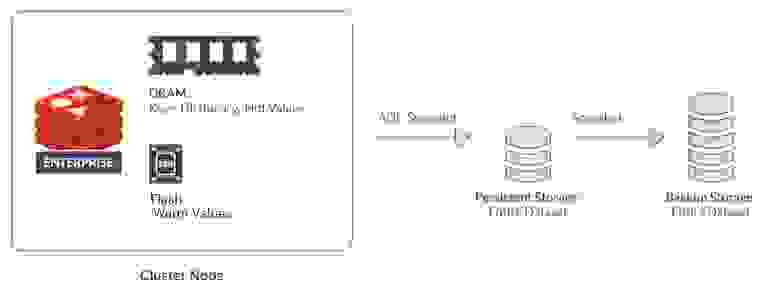
One exciting feature in Redis Enterprise is called Redis on Flash (RoF). RoF enables databases to extend DRAM capacity using Flash memory or solid-state drives (SSDs).
Ordinarily, Redis Enterprise keeps an entire dataset in DRAM. That is good for most purposes, but it becomes an issue when a dataset is prohibitively large. However, when you use RoF, far less information is stored in DRAM: the keys, the Redis dictionary (the data structure behind the keys), and the dataset’s frequently accessed data (also called “hot data” or the working set). DRAM is still the faster tier, which is why it holds the critical data.
However, with RoF the inactive data (also called “the warm values”) are moved to the lower tier, the local Flash storage tier.
RoF is based on a multi-threaded asynchronous architecture that guarantees no blocking between a heavy caching request made to Flash and a light caching request made to DRAM. That avoids head-of-the-line blocking scenarios resulting from the single-threaded nature of Redis Enterprise.
Redis on Flash is not designed as an alternative mechanism for data persistence. The same Append Only File and snapshot data-persistence mechanisms, persisting data to disk, are used with RoF as with Redis Enterprise.
So far, so good. We’ve had RoF for several years. Beyond its technical merit, RoF has saved companies a lot of money.
However, RoF wasn’t part of our Kubernetes offering – until now.
RoF is now available for Redis Enterprise for Kubernetes, starting with version 6.2.12 (option to enable) and with 6.2.18 due in mid November – a boon for customers with large datasets. Even when a RAM-only solution works technically, it often is cost-prohibitive, and customers would prefer to use Flash.
Just as with RoF on non-Kubernetes clusters, there are, of course, storage prerequisites. The underlying hardware needs to be performant and directly attached to the Kubernetes cluster node. Kubernetes also has a particular way to use storage, so be sure to follow the setup guidelines to ensure a smooth installation.
After the prerequisites, the rest of what you do in Redis Enterprise for Kubernetes feels like any other operation. We extended the usual way you create and use Redis Enterprise Cluster (REC) and Redis Enterprise Database (REDB) by adding YAML to express the configuration.
Getting started is remarkably easy. All you need is a simple configuration inside Kubernetes to use this powerful capability. Simple, fast, and efficient. What else could you ask for?
To turn on this feature, add these lines to a REC:
redisOnFlashSpec:
enabled: true
flashStorageEngine: rocksdb
storageClassName: local-scsi
flashDiskSize: 100G
This code example turns on RoF for the cluster, then sets the storage engine, the Kubernetes storage class, and the amount on disk for this cluster node.
Similarly, you turn on RoF support for your database by adding these lines to the REDB spec:
isRof: true
memorySize: 2GB
rofRamSize: 0.5GB
With these instructions, you tell REDB to use RoF by turning it on, identifying how much memory to allocate for the database size, and how much you want in RAM.
Naturally, there are options, and some of them are mighty important. For instance, the setting here for how much data is in RAM directly impacts performance. Don’t merely copy the example above; there are configuration guidelines, so take the time to read the documentation for Redis on Flash configuration and the Kubernetes-specific details.
Happy RoF-ing, and have a great day!