

After aggregating massive amounts of disparate data coming in across hundreds or thousands of diverse systems and locations, DigitalRoute’s Usage Data Platform (UDP) then analyzes and acts upon all that data… in real time! Not only does the UDP transform the data, it also filters and forwards the data, creating an intelligent layer across a company’s infrastructure. Sounds daunting, right?
It is daunting, but tracking customer consumption in large and complex environments is exactly what DigitalRoute’s Usage Data Platform was built to do, not only for organizations in the telecom industry, but other industries too such as utilities, financial services, and travel.
Our technology processes 300 billion transactions per day and much of that data is streaming. Needless to say, our platform has a real need for speed. Industry benchmarks demand times of less than 500ms for end-to-end processing of what can easily reach thousands of transactions per second per customer. Even more demanding are our customers, who are counting on us to provide real-time insights that they can then act upon in real time to improve user experience.
My application development team recently introduced a new trace feature to DigitalRoute’s platform offerings. This feature tracks the path of any given record through a customer’s system: where it originated, where it currently resides, and what types of transformations have been applied to it along the way. Since one single transaction can be propagated to many areas of a system for fine-grain correlations, we needed a robust back-end capable of efficiently storing this information and presenting it to the requesting application on the fly. And like every other aspect of our platform, it needed to be fast.
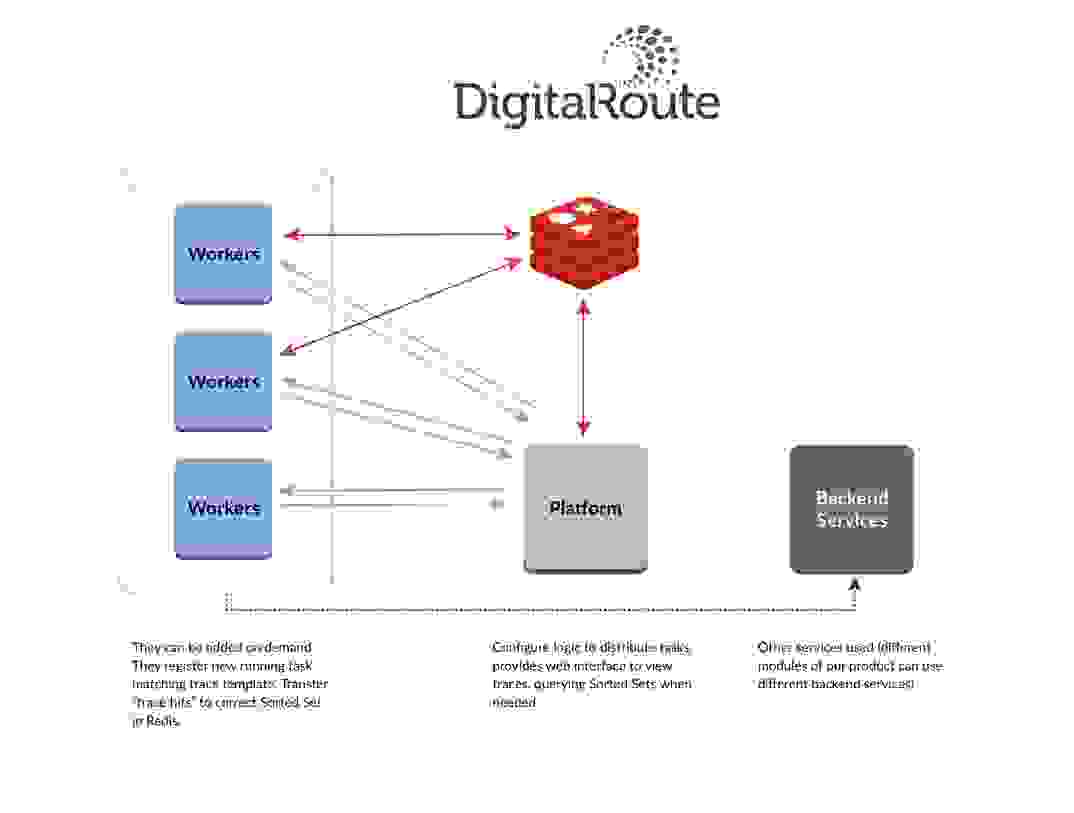
Initially, we used Akka Clusters running on top of our own “abstract executor” as the back-end tool for these communications, but this deployment turned out to be quite painful for us to manage because each time connection was lost we had to perform a series of cumbersome administrative steps to recover the cluster. After receiving a couple of problem reports, we decided to give Redis’ pub/sub messaging capabilities a try.
Under a pub/sub communications pattern, the publisher publishes that the state of the data has changed (along with the changes themselves) and the subscribers, which are in constant listening mode, update their internal states in response. Redis’ pub/sub message broker proved to be extremely simple to set up and very, very fast. We use it to exchange trace messages. Because our interface has many instances, Redis channels listen to traces reported by active workers at any given point in time. Then, using the reported ID, we can find a sorted set holding traces in correct order. We benefit from the ability to subscribe to a channel at any time, and listen to any new trace reported by any worker; there’s no need to create separate services.
After hearing about Redis Streams at RedisConf18, I did some research and believe that this new data structure will be an even better fit for our use case. The pub/sub messaging pattern is one of fire and forget, but Redis Streams persists data—even when data consumers are offline or disconnected. This built-in data persistence is a perfect complement to the historical view our tracing feature is looking to provide. Redis Streams also creates a many-to-many data channel between producers and consumers, which is ideal for us because our platform most typically deals with multi-sourced data destined for consumption by multiple consumers.
With Redis lending a helping hand, it’s full speed ahead for DigitalRoute!
See how you too can use Redis Streams in your apps and follow Digital Route on their Twitter to see what’s next for them.


