

The popular RediSearch module was designed to extend Redis’s capabilities by adding a secondary index with super-fast full-text search capabilities. RediSearch has been extremely well received, collecting more than 150,000 Docker pulls, 2,000 GitHub stars, 230 forks, and 10 drivers in some 10 different languages. And customers are already taking advantage—see this video on how GAP scaled 100X using Redis.
Today, we’re proud to announce RediSearch 1.6, which refactors the original module to boost performance and adds some important new functionality—including aliasing, a low-level API, and improved query validation—as well as making the Fork garbage collection the module’s default—all designed to make development with RediSearch even more powerful and convenient.
We originally created RediSearch to support a single (or limited in amount) secondary index that would scale by scaling Redis. Over the years, Redis users have turned to RediSearch for a wide variety of use cases that frequently delete and recreate the same index while querying it or that create thousands of small, short-lived indices. In RediSearch 1.6, we refactored our codebase to better support these use cases. In doing so, we added better query validation and improved performance by up to 73%! We also added two major new features: Aliasing lets Redis refer to an existing index and easily switch to another index, while a new low-level API makes RediSearch available as a library that can be used by other Redis modules written in C or Rust. That means developers won’t have to learn additional search query languages to use any Redis module. With this library, modules can add secondary indexing capabilities easily. RedisGraph 2.0 is the first generally available Redis module to exploit this feature by offering full-text search capabilities. The full list of added features in RediSearch v.1.6 can be found on GitHub.
Based on testing with our full-text search benchmark (FTSB), RediSearch 1.6 brings significant performance advantages compared to version 1.4. Specifically, RediSearch 1.6 increased simple full-text search throughput by up to 63%, while cutting latency (q50) by up to 64%. For aggregate queries, throughput increased from 15% to 64%.
(For more on the performance improvements in RediSearch 1.6, see our blog post on RediSearch 1.6 Boosts Performance Up to 64%.)
One of RediSearch’s most powerful capabilities is that every update to a document atomically updates the index. Unlike other, Lucene-based search engines, the RediSearch index does not have to play catch up with the data. In other words, you always read your own writes.
In certain applications, however, it’s more efficient or convenient to reload an entire index rather than tracking the differences between two bulk loads. Updating your applications to connect to the newly loaded index in runtime without downtime is almost impossible, so we introduced aliasing to make RediSearch even more flexible and powerful. Significantly, ElasticSearch users will find the addition of aliasing to RediSearch will ease their migration path to Redis, as shown in the example below.
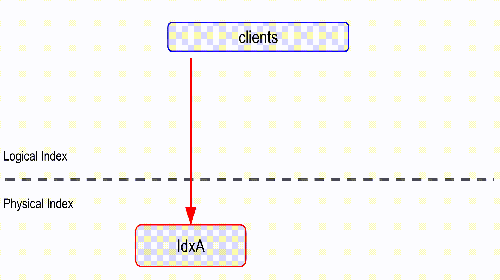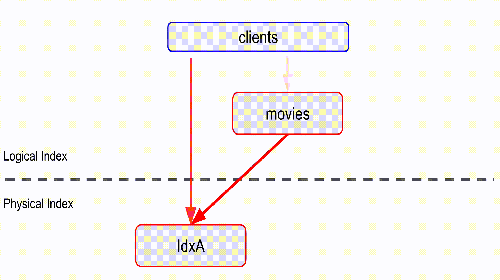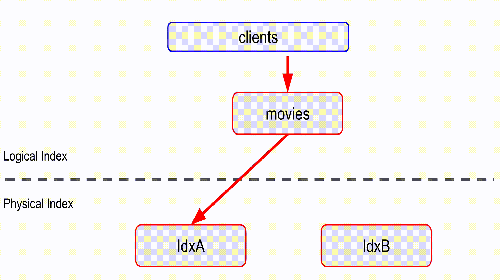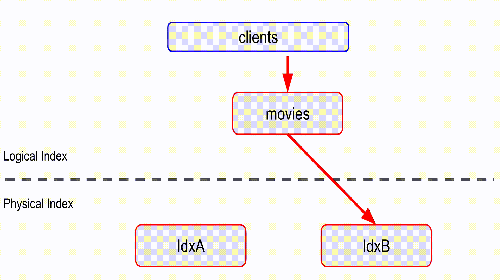
Aliasing lets you redirect application queries from a logical index name to a physical underlying index. Updating an alias allows you to transparently redirect your application queries to another physical index, without any downtime!
This simple example explains how aliasing works with RediSearch commands:
redis:6379> FT.CREATE idxA SCHEMA title TEXT
OK
redis:6379> FT.ADD idxA a:doc1 1.0 FIELDS title "plump fiction"
OK
redis:6379>
OK
redis:6379> FT.SEARCH movies "@title:fiction"
1) (integer) 1
2) "a:doc1"
3) 1) "title"
2) " fiction"
redis:6379> FT.CREATE idxB SCHEMA title TEXT
OK
redis:6379> FT.ADD idxB b:doc1 1.0 FIELDS title "pulp fiction"
OK
redis:6379>
OK
redis:6379> FT.SEARCH movies "@title:fiction"
1) (integer) 1
2) "b:doc1"
3) 1) "title"
2) " fiction"
Going forward, there is an opportunity to enhance this feature with the ability to alias more than one index, for example, to address querying two indices responsible for a distinct set of documents.
Since the creation of Redis’ module API, Redis and the Redis community have created a large set of modules. Some add a whole new database model to Redis, some let you execute code with the data, and others add new data structures to Redis. We noticed, however, that several modules started building their own proprietary way of indexing data. In RedisGraph, for example, indices on properties of nodes in the graph are maintained in a ziplist and RedisTimeSeries uses sorted sets for querying time series data that has certain label conditions.
These implementations provide basic search functionality, but for RediSearch 1.6 we wanted to remove code duplication and enhance search functionality in key use cases with a common query language. In graph databases, for example, it’s common to do a fuzzy search on properties of nodes to enable a graph-aided search. Time-series use cases, meanwhile, often involve all time series where a label matches a certain prefix. Other Redis modules could benefit from secondary indexing support. Imagine what you could do if RedisJSON had full-text search capabilities!
So for RedisSearch 1.6 we created a low-level API that can be consumed by other Redis modules. RedisGraph v2.0 is the first generally available Redis module that uses this module. Graph-aided search lets you find nodes in a graph for which properties match a full-text search query and rank them based on the connections these nodes have in the graph.
LinkedIn’s search functionality is a great example of graph-aided search: People and companies that are closer to you in your network show up higher in your search results. We continue to work on low-level API development for RedisTimeSeries, and you can already try out the preview version of RedisJSON 2.0 with RediSearch embedded.
Like most inverted-index based search engines, when you delete or update a document, RediSearch effectively marks the document as to be deleted. A garbage collection process runs regularly to reclaim the memory used to store deleted documents. Marking the document as removed and making the physical removal asynchronous reduces the command execution time while preserving the correctness of queries.
In RediSearch 1.4, the default behavior was to lock the main thread, which introduced spikes in read latencies during garbage collection. To overcome this, RediSearch 1.4 offered an optional Fork GC that runs in parallel with the main query process, allowing uninterrupted scanning for any deleted documents. This approach provides superior performance for high-traffic environments, where many queries are issued and/or many writes are performed, so we have made this behavior the default in RediSearch 1.6.
You can see the benefits of Fork GC in this two-phase test. In phase one, we insert 10 million new documents. After this phase we drop the index. In phase two, the traffic is mixed: inserting and updating 5 million documents. For each write operation however, there is also an update operation (a 50% update rate), so this also totals 10 million operations.
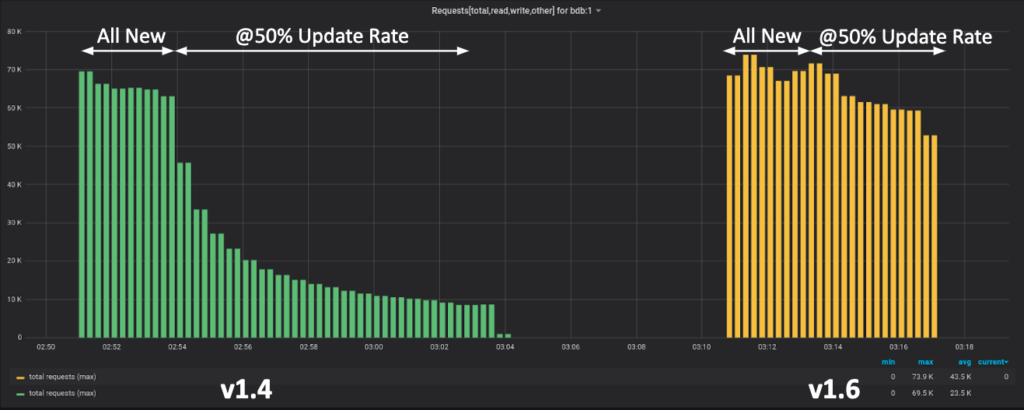
The chart clearly shows how legacy garbage collection performance quickly degrades when there is a 50% update rate. In general, we have observed an 8% improvement in low update rates and up to a 70% performance improvement at high update rates with the new Fork garbage collection:

Finally, RediSearch 1.6 also boasts improved query validation. If a query is determined to contain logical or syntax errors, an appropriate error message is returned to the user, rather than letting the query execute with no results. RediSearch 1.6 also returns an error when an unrecognized keyword is submitted. This query validation will enhance the developer experience and lower the RediSearch learning curve. Also note that RediSearch 1.6 is supported by RedisInsight, our recently announced browser-based management interface for your Redis deployment.
Looking forward, we have many interesting features on the roadmap, such as support for polygon search and creating higher parallelism for read queries on a single shard. That will help us achieve higher throughput for aggregation queries without having to increase the number of shards.
Even more important than the new features, of course, Version 1.6 is the fastest RediSearch ever (learn more about RediSearch 1.6 performance improvements here.) Your applications will experience more consistent latencies, with fewer peaks, across all types of queries.
Finally, we want to thank the Redis community members who helped make RediSearch 1.6 more robust by spotting bugs in earlier release candidates.


