

In July, we introduced the private preview of a real-time document store with native indexing, querying, and full-text search capabilities powered by the combination of RedisJSON and RediSearch. During the preview, we’ve greatly improved the performance and stability of the offering, simplified packaging for easier onboarding, and enhanced our driver support. Today, we’re happy to announce that RedisJSON* (powered by RediSearch) is now available as a public preview and available in our cloud. Public preview means generally available (GA) quality code that’s available in limited deployment environments.
RedisJSON* is a source-available real-time document store that allows you to build modern applications by using a dynamic, hierarchical JSON document model. Our early customers have started using it in various architectural scenarios across their data stack: as a cache, as a query accelerator to speed-up hotspots, and as a primary database. We’re seeing growing adoption in our developer community as well. In the last 3 months alone, there’ve been a million Docker pulls of RedisJSON and RediSearch combined.
Redis is the most loved database for the 5th consecutive year (Stack Overflow survey) and we wanted RedisJSON* to have the same simplicity, scalability, and, most importantly, speed of Redis that our community is familiar with, so we purpose-built it from the ground up. Given that performance is Redis’ key strength, we decided to check how we fared against the previous version and comparable players in the market. To provide a fair comparison of RedisJSON, MongoDB, and ElasticSearch, we relied on the industry standard Yahoo! Cloud Serving Benchmark (YCSB).
Each product comes with a different architecture and a different feature set. For a given use case, one product might be a better fit than another. In full transparency, we’re aware that MongoDB and ElasticSearch have been around longer. It’s up to you, the developer, to choose the right tool for the problem at hand. We’re adding a lot of context to our benchmark results in this blog because there are many variables at play that might differ from your use case. We found that:
Additionally, RedisJSON*’s latencies for reads, writes, and searches under load are far more stable in the higher percentiles than ElasticSearch and MongoDB. RedisJSON* also handles an increasingly higher overall throughput when increasing the write ratio while ElasticSearch decreases the overall throughput it can handle when the write ratio increases.
As mentioned before, RediSearch and RedisJSON are developed with a great emphasis on performance. With every release, we want to make sure you’ll experience stable and fast products. Whether we’re finding room for improving the efficiency of our modules or pursuing a performance regression investigation, we rely upon a fully automated framework for running end-to-end performance tests on every commit to the repos (details here), and we follow up if required with performance investigations by attaching telemetry and profiling tools/probers.
This allows us, in a concise methodical way, to keep bumping up performance with every release. Specifically for RediSearch, 2.2 is up to 1.7x faster than 2.0 both on ingestion and query performance, when combining the throughput and latency improvements.
The next two diagrams show the results of running the NYC taxi benchmark (details here). This benchmark measures both the throughput and the latency observed while ingesting about 12 million documents (the rides that have been performed in yellow taxis in New York in 2015).
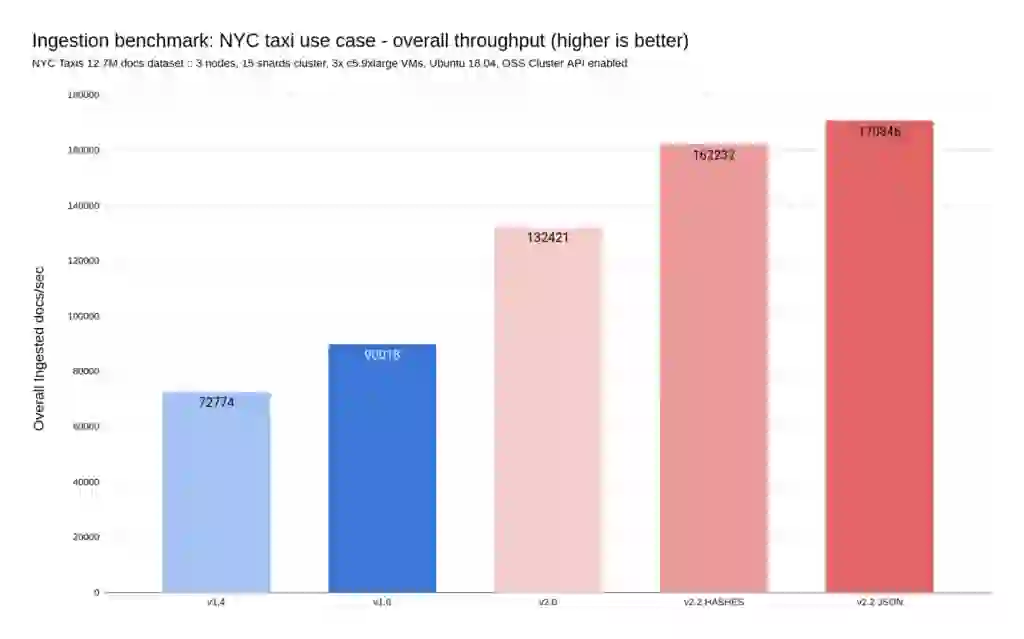
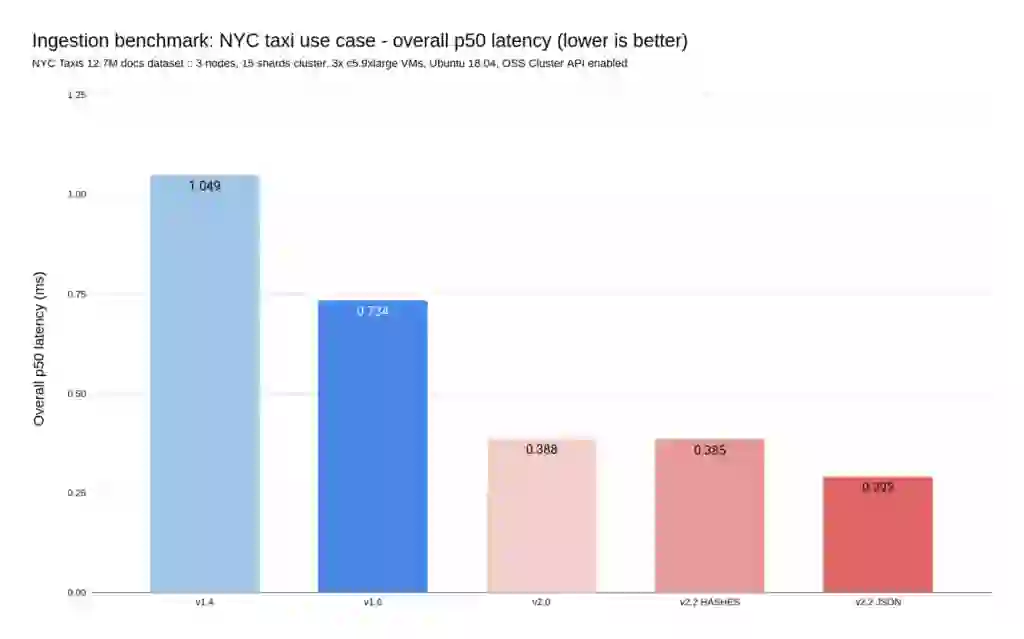
As can be seen on these diagrams, each new version of RediSearch comes with a substantial performance improvement.
To evaluate search performance, we indexed 5.9 million Wikipedia abstracts. Then we ran a panel of full-text search queries (details here).
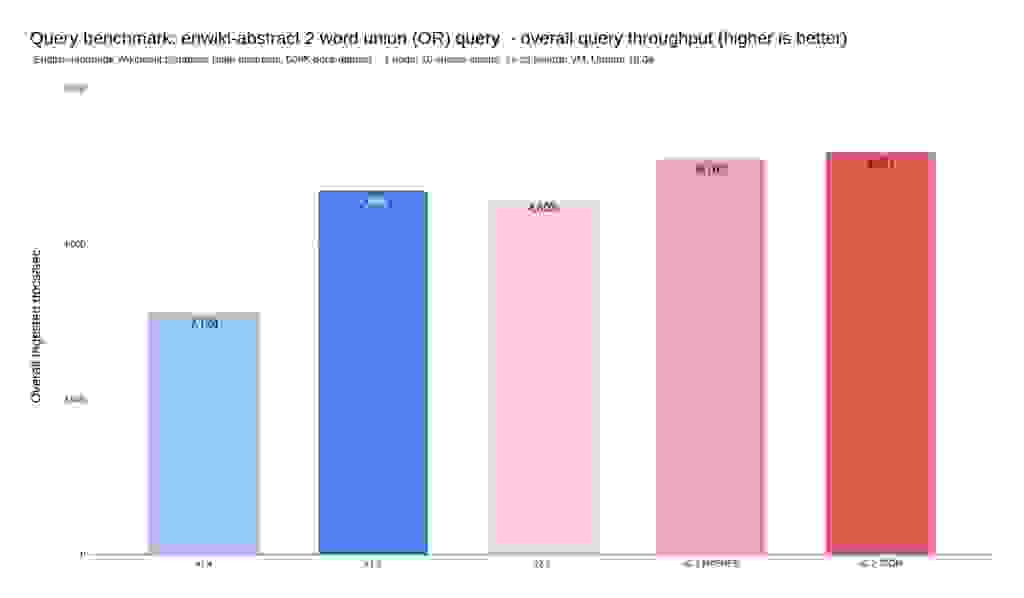
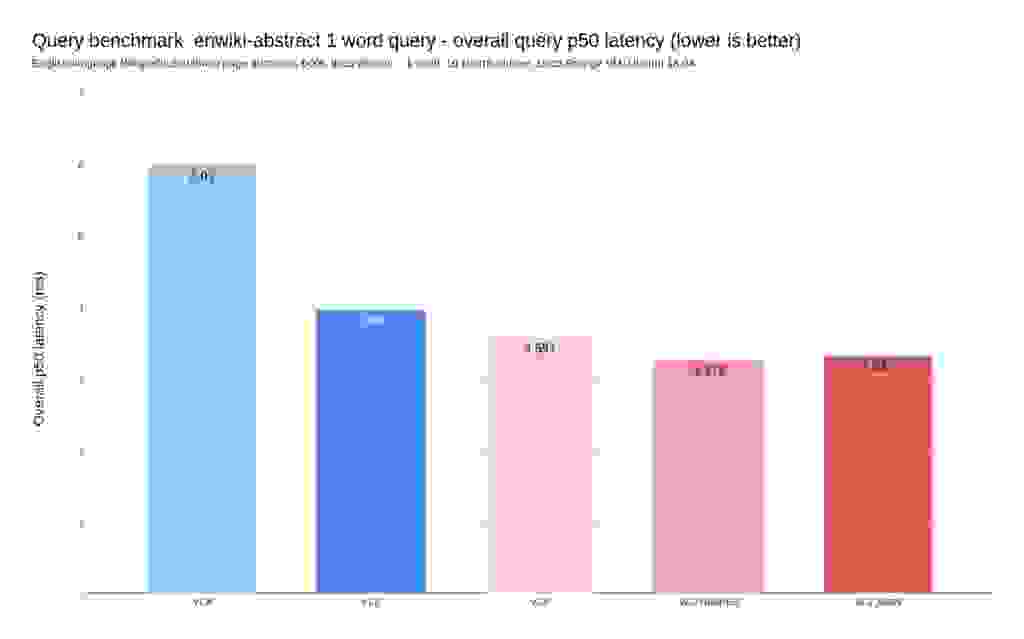
As seen above, you’ll benefit from faster writes/reads/searches (latency charts) by moving from v2.0 to v2.2 and consequently increase the achievable throughput of the same hardware on which Search and JSON are running.
To assess RedisJSON’s performance, we’ve decided to benchmark it in comparison to MongoDB and ElasticSearch. When talking about document stores, these solutions often come into the picture. They’re both available on-premises, available in the cloud, provide professional support, and are committed to providing scalability and performance. Of course, everything depends on the use case and, in the future, we plan to extend this benchmark to other vendors providing a comparable scope of capabilities to Redis. Let’s have a look at our approach.
We’ve used the well-established YCSB, capable of evaluating different products based on common workloads measuring the resulting latency/throughput curve until saturation. Apart from the CRUD YCSB operations, we’ve added a two word search operation specifically to help developers, system architects, and DevOps practitioners find the best search engine for their use cases. The generated documents have an approximate size of 500 bytes, and each solution creates one secondary index indexing one text field and one numeric field.
For all tested solutions, the latest available stable OSS version was used: MongoDB v5.0.3, ElasticSearch 7.15, and RedisJSON* (RediSearch 2.2+RedisJSON 2.0).
We ran the benchmarks on Amazon Web Services instances provisioned through our benchmark testing infrastructure. All three solutions are distributed databases and are most commonly used in production in a distributed fashion. That’s why all products used the same general purpose m5d.8xlarge VMs with local SSDs and with each setup being composed of four VMs: one client + three database Servers. Both the benchmarking client and database servers were running on separate m5d.8xlarge instances placed under optimal networking conditions, with the instances packed close together inside an Availability Zone, achieving the low latency and stable network performance necessary for steady-state analysis.
The tests were executed on three-node clusters with the following deployment details:
In addition to this primary benchmark/performance analysis scenario, we also ran baseline benchmarks on network, memory, CPU, and I/O in order to understand the underlying network and virtual machine characteristics. During the entire set of benchmarks, the network performance was kept below the measured limits, both on bandwidth and PPS, to produce steady stable ultra-low latency network transfers (p99 per packet < 100micros ).
We’ll start by providing each individual operation performance [100% writes] and [100% reads] and finish with a set of mixed workloads to mimic a real-life application scenario.
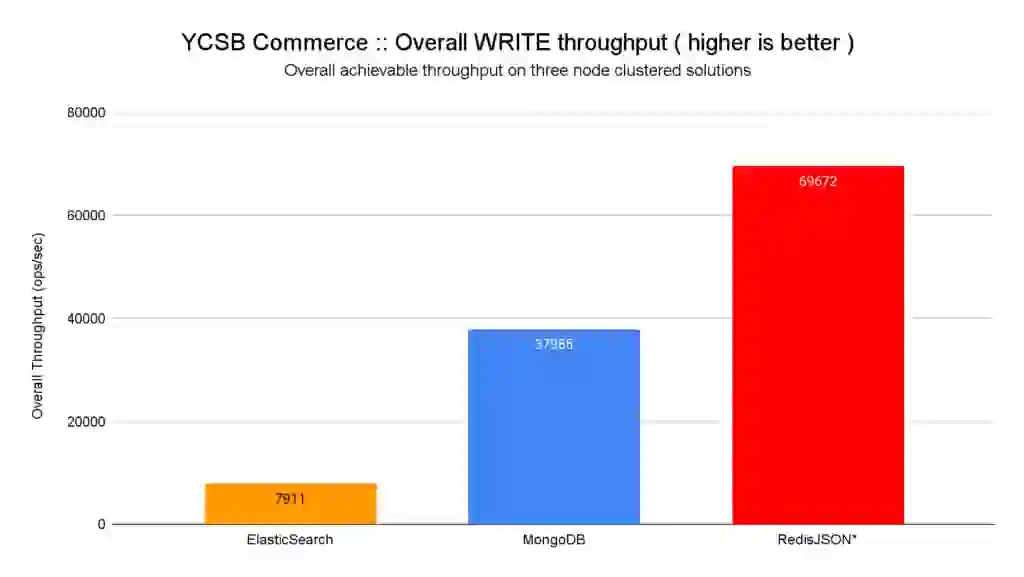
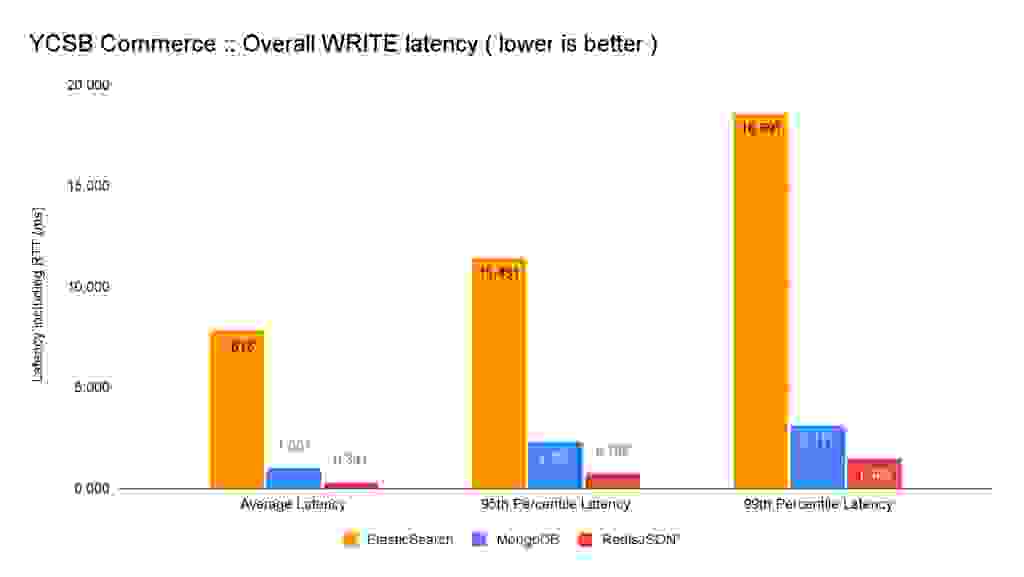
As you can see on the charts below, this benchmark shows that RedisJSON* allows for 8.8x faster ingestion vs. ElasticSearch, and 1.8x vs. MongoDB, while keeping a sub-millisecond latency per operation. It’s worth noting that 99% of the requests to Redis completed in less than 1.5ms.
In addition, RedisJSON* is the only solution we tested that atomically updates its indices on every write. This means that any subsequent search query will find the updated document. ElasticSearch doesn’t have this granular capacity; it puts the ingested documents in an internal queue, and this queue is flushed by the server (not controlled by the client) every N documents, or every M seconds. They call this approach Near Real Time (NRT). The Apache Lucene library (which implements the full-text capabilities for ElasticSearch) has been designed to be fast in searching, but the indexing process is complex and heavy. As shown in these WRITE benchmark charts, ElasticSearch pays a big price due to this “by design” limitation.
When combining the latency and throughput improvements, RedisJSON* is 5.4x times faster than Mongodb and >200x faster than ElasticSearch for isolated writes.
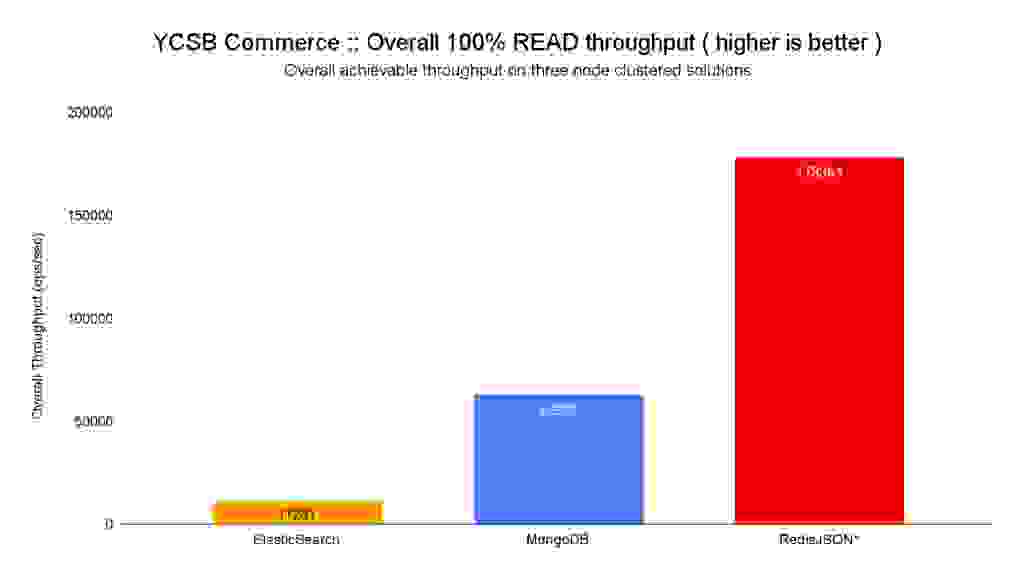
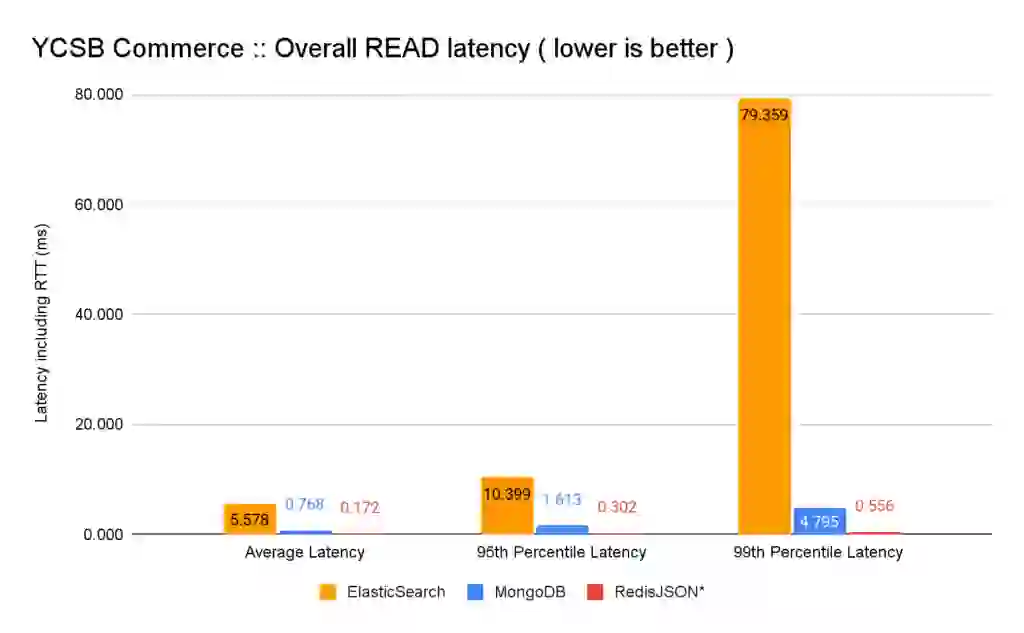
Similarly to writes, we can observe that Redis is the top performer for reads, allowing for 15.8x more reads than ElasticSearch and 2.8x more than MongoDB, while retaining sub-millisecond latency across the complete latency spectrum, as visible on the table below.
When combining the latency and throughput improvements, RedisJSON* is 12.7x times faster than MongoDB and >500x faster than ElasticSearch for isolated reads.
Real-world application workloads are almost always a mix of reads, writes, and search queries. Therefore, it’s even more important to understand the resulting mixed-workload throughput curve as it approaches saturation.
As a starting point, we considered the scenario with 65% searches and 35% reads, which represents a common real-world scenario, in which we do more searches/queries than direct reads. The initial combination of 65% searches, 35% reads, and 0% updates also results in an equal throughput for ElasticSearch and RedisJSON*. Nonetheless, the YCSB workload allows you to specify the ratio between searches/reads/updates to match your requirements.
“Search Performance” can refer to different kinds of searches, e.g. “match-query search,” “faceted search,” “fuzzy search,” and more. The initial addition of the search workload to YCSB that we’ve done focuses solely on the “match-query searches” mimicking a paginated two-word query match, sorted by a numeric field. The “match-query search” is the starting point for the search analysis for any vendor that enables search capabilities, and, consequently, every YCSB-supported DB/driver should be able to easily enable this on their benchmark drivers.
On each test variation, we’ve added 10% writes to mix and reduce the search and read percentage in the same proportion. The goal of these test variations was to understand how well each product handles real-time updates of the data, which is something we believe is the de facto architecture goal, i.e. writes are immediately committed to the index and reads are always up to date.
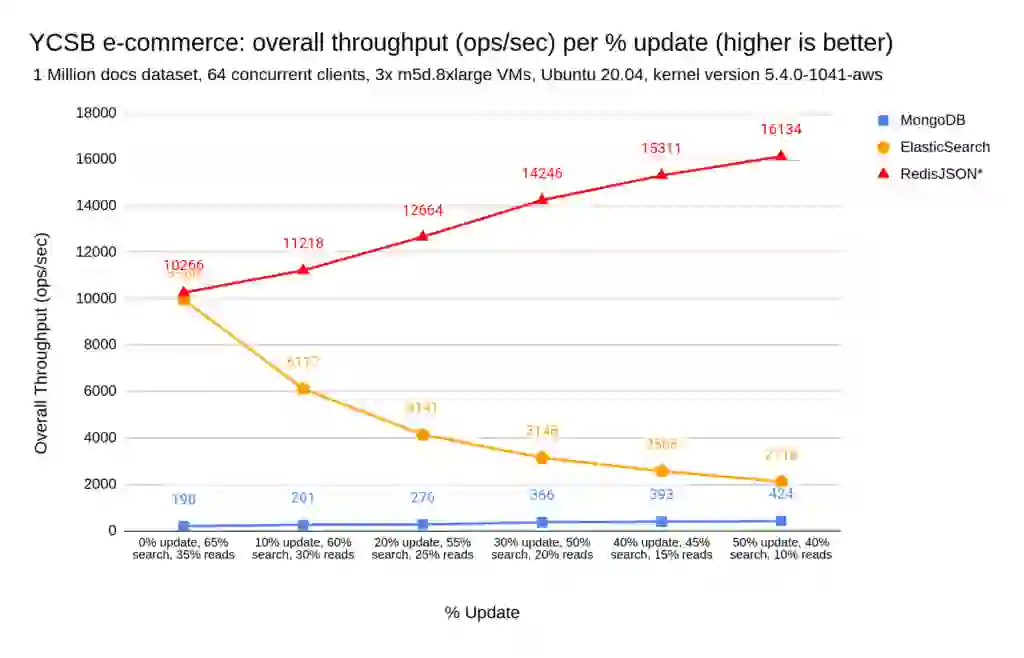
As you can see on the charts, continuously updating the data and increasing the write proportion on RedisJSON* doesn’t impact the read or search performance and increases the overall throughput. The more updates produced on the data, the more affected ElasticSearch performance is, ultimately making the reads and searches slower.
Looking at the achievable ops/sec evolution from 0 to 50% updates for ElasticSearch, we notice that it started at 10k Ops/sec on 0% update benchmark and is deeply affected up to 5x fewer ops/sec reaching only 2.1K ops/sec on the 50% update rate benchmark.
Similar to what we observed in the individual operations benchmarks above, MongoDB search performance is two orders of magnitude slower than RedisJSON* and ElasticSearch, with MongoDB reaching a max overall throughput of 424 ops/sec vs. the 16K max ops/sec with RedisJSON*.
In the end, for mixed workloads, , RedisJSON* enables up to 50.8x more ops/sec than MongoDB and up to 7x times more ops/sec than ElasticSearch. If we center the analysis on each operation type latency during the mixed workloads, RedisJSON* enables up to 91x lower latencies when compared to MongoDB and 23.7x lower latencies when compared to ElasticSearch.
Similarly to measuring the resulting throughput curve until saturation of each of the solutions, it’s important to also do a full latency analysis at a sustainable load common across all solutions. This will allow you to be able to understand what is the most stable solution for all issued operations in terms of latency, and the one less susceptible to latency spikes provoked by application logic (for example, the Elastic query cache miss). If you want to dive deeper into why we should do it, Gil Tene provides an in-depth overview of latency measurement Do’s and Don’ts.
Looking at the throughput chart from the previous section, and focusing on the 10% update benchmark to include all three operations, we do two different sustainable load variations:
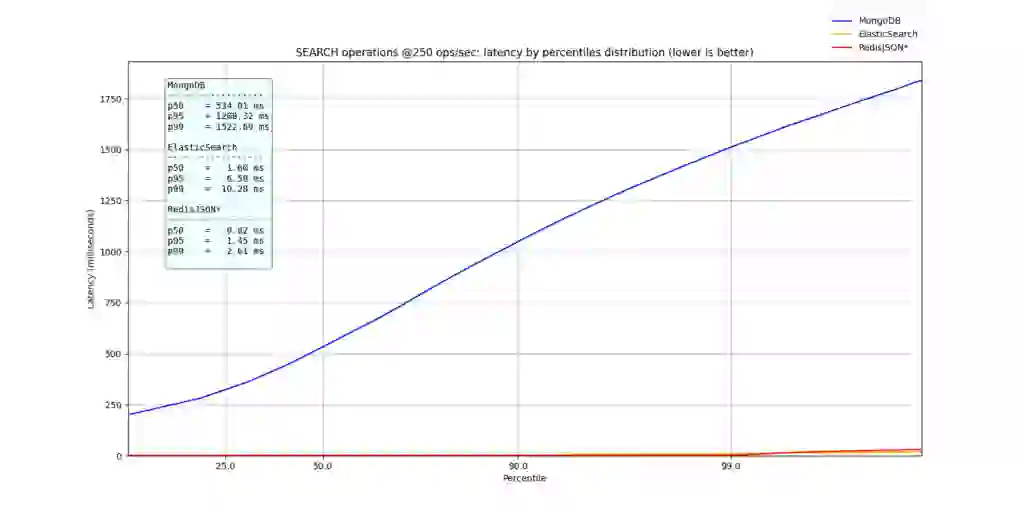
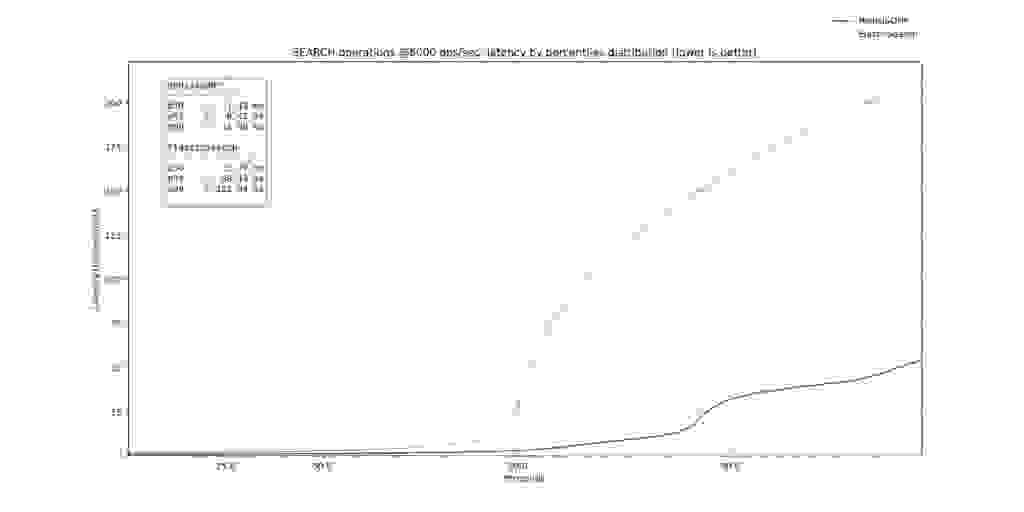
In the first image below, showcasing the percentiles from p0 to p9999, it’s clear that MongoDB is deeply outperformed by Elastic and RedisJSON* on each individual time to search. Furthermore, focusing on ElasticSearch vs. RedisJSON*, it’s clear that ElasticSearch is susceptible to higher latencies which are most likely caused by Garbage Collection (GC) triggers or search query cache misses. The p99 of RedisJSON* was below 2.61ms, in contrast to the ElasticSearch p99 search that reached 10.28ms.
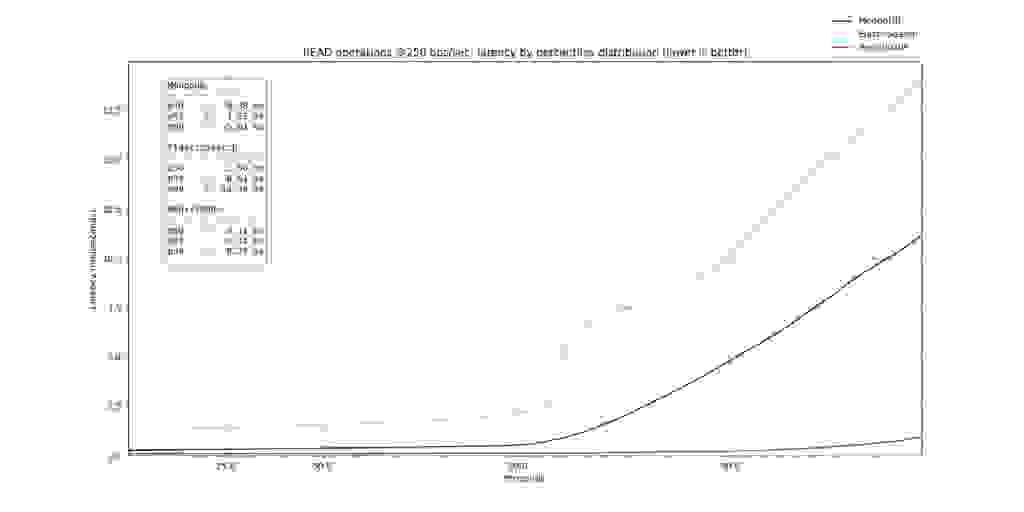
In the read and update charts below, we can see that RedisJSON* is the top performer across all latency spectrums, followed by MongoDB and ElasticSearch.
RedisJSON* was the only solution to maintain sub-millisecond latency across all analyzed latency percentiles. At p99, RedisJSON* had a latency of 0.23ms, followed by MongoDB at 5.01ms, and ElasticSearch at 10.49ms.
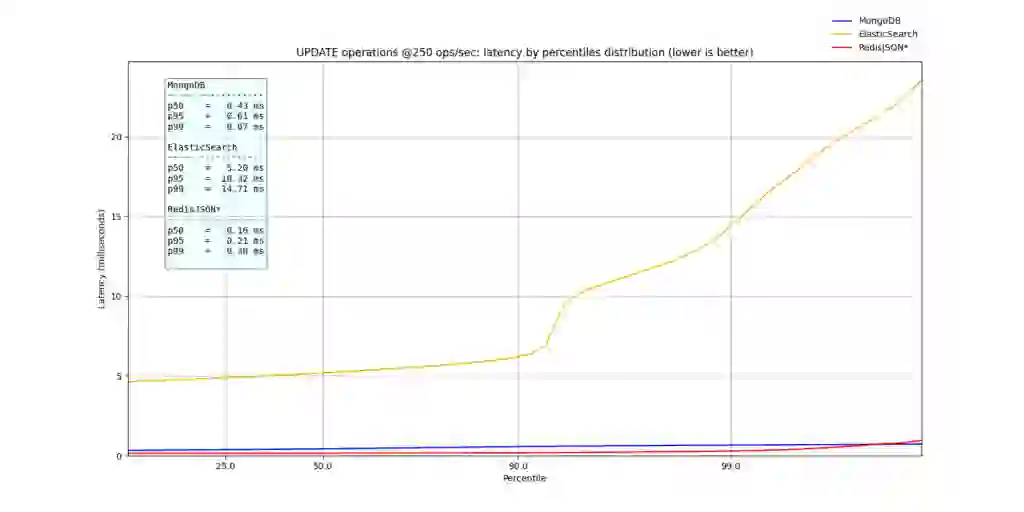
On writes, MongoDB and RedisJSON* maintained sub-millisecond latencies even at p99. ElasticSearch, on the other hand, showed high tail latencies (>10ms), for most likely the same reasons (GC) that cause the Search spikes for ElasticSearch.
Focusing solely on ElasticSearch and RedisJSON*, while retaining a sustainable load of 6K ops/sec, we can observe that the read and update patterns of Elastic and RedisJSON* remained equal to the analysis done at 250 ops/sec. RedisJSON* is the more stable solution, presenting p99 reads of 3ms vs. the p99 reads of 162ms for Elastic.
On updates, RedisJSON* retained a p99 of 3ms vs. a p99 of 167ms for ElasticSearch.
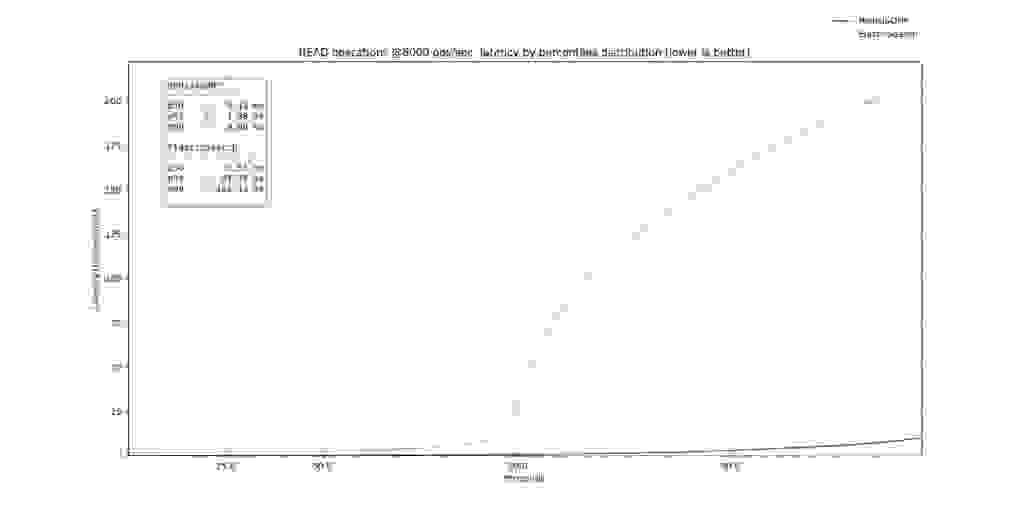
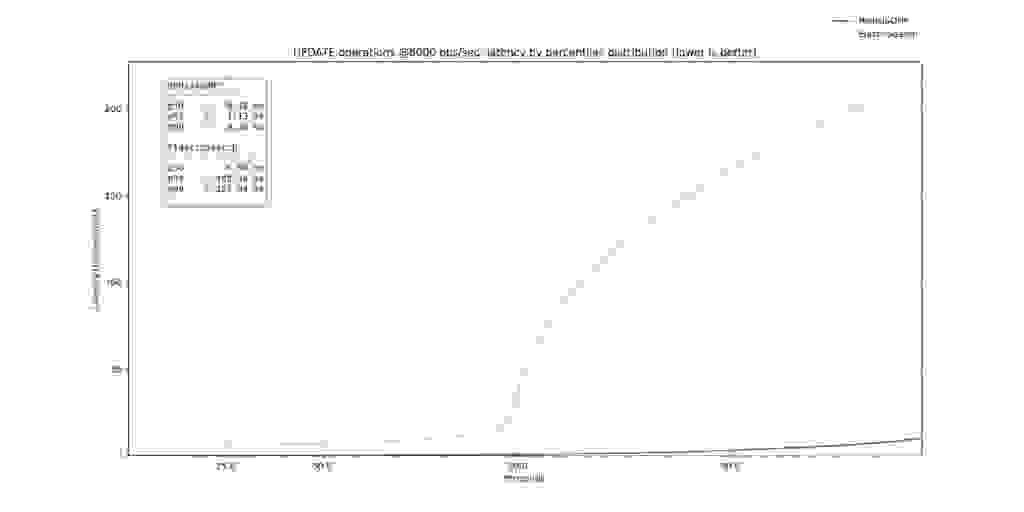
Focusing on the Search operations, ElasticSearch and RedisJSON* start with single-digit p50 latencies (p50 RedisJSON* of 1.13ms vs. p50 of ElasticSearch of 2.79ms) with ElasticSearch paying the price of GC triggering and query cache misses on the higher percentiles, as is clearly visible on the >= p90 percentiles.
RedisJSON* retained a p99 below 33ms vs. the 5x higher p99 percentile at 163ms on ElasticSearch.
We take performance very seriously and would like to invite other partners and community members to collaborate in our efforts to create a standard benchmark definition for search and document workloads. RedisJSON and RediSearch performance data and tooling will be opened to the community over the coming months.
Similar to the self-managed (on-premises) benchmark numbers above, we’ll also be benchmarking the DBaaS performance of Redis Cloud against other comparable cloud document databases in the coming weeks. In addition to the benchmarks, we’ve published a technical blog on how to build a fast, flexible, and searchable product catalog using RedisJSON.
Lastly, we’ve also extended RediSearch with vector similarity search, which is now in private preview.
To get started with RedisJSON* you can create a free database on Redis Cloud in all regions. Alternatively, you can use the RedisJSON docker container. We updated the documentation on redisjson.io to easily get started with query and search capabilities. Additionally, as mentioned in our recent client libraries announcement, here are the client drivers for several popular languages to help you get started.
| RedisJSON* | |
| Node.js | node-redis |
| Java | Jedis |
| .NET | NRedisJSON NRediSearch |
| Python | redis-py |
Here’s some links to get you started



