




Introducing the Redis/Intel Benchmarks Specification for Performance Testing, Profiling, and Analysis
Learn more


Intel and Redis are working together to investigate potential performance optimizations for the RedisTimeSeries compression/decompression algorithm. Here’s how that exploration works.
Time-series data management can be critical in data analytics. Many applications need to store time-stamped data, such as stock prices, IoT sensor data, and CPU performance metrics. By definition, data accuracy is a significant factor in how this information is stored, as is the speed of storage and access.
RedisTimeSeries is a time-series database (TSDB) module that keeps large amounts of streaming data completely in-memory. That makes data available for fast processing, thanks to a state of art compression/decompression algorithm called Gorilla. In this blog post, we review the Gorilla algorithm implementation in RedisTimeSeries as well as potential ideas for further optimization. While at this time we chose to keep the existing compression/decompression implementation unchanged, we want to share our exploration process in our shared pursuit of continuous improvement.
The Gorilla algorithm was developed by Meta for its large-scale and distributed TSDB. One of Meta’s key TSDB requirements is to maintain at least 26 hours of streaming data in-memory. It has to be available for fast analysis. Moreover, newer data is typically of higher value than older data for detecting events, anomalies, etc. That made compression ratio and query efficiency of paramount importance.
Gorilla tailors the compression algorithm specifically to the characteristics of time-series data. In particular, its authors recognize that sequential data points are closely related in value and that using a “delta” style algorithm can achieve an excellent compression ratio with low computational overheads. For example, data points may arrive at regular time intervals – say, every 30 seconds. Thus, the delta between the time stamps is frequently the same or a similar value. The delta between sequential floating point data values is also expected to be closely related.
The authors propose to use a “delta of deltas” algorithm for the integer time stamps and an XOR-based delta encoding for the floating point values. The encoded time stamps and data values are inserted one after the other into an in-memory buffer. See the original paper for the details of the encoding/decoding algorithms.
Overall, the Gorilla algorithm achieves about a 10X compression ratio, with more than 96% of time stamps compressed to a single bit and more than 59% of floating point values compressed to a single bit.
The RedisTimeSeries database implements the Gorilla algorithm for compressing and decompressing time-series data.
It could be faster. (Then again, when it comes to performance optimizations, it could always be faster! That’s what Redis is here for.)
While Gorilla achieves excellent compression ratios and computational efficiency, in some situations – e.g. when computing filtering operations across the time-series database – the decompression routine takes up a significant amount of time. For example, in the flame graph below, we see that decompressChunk takes up a large portion of the execution time, up to 85% in one instance.
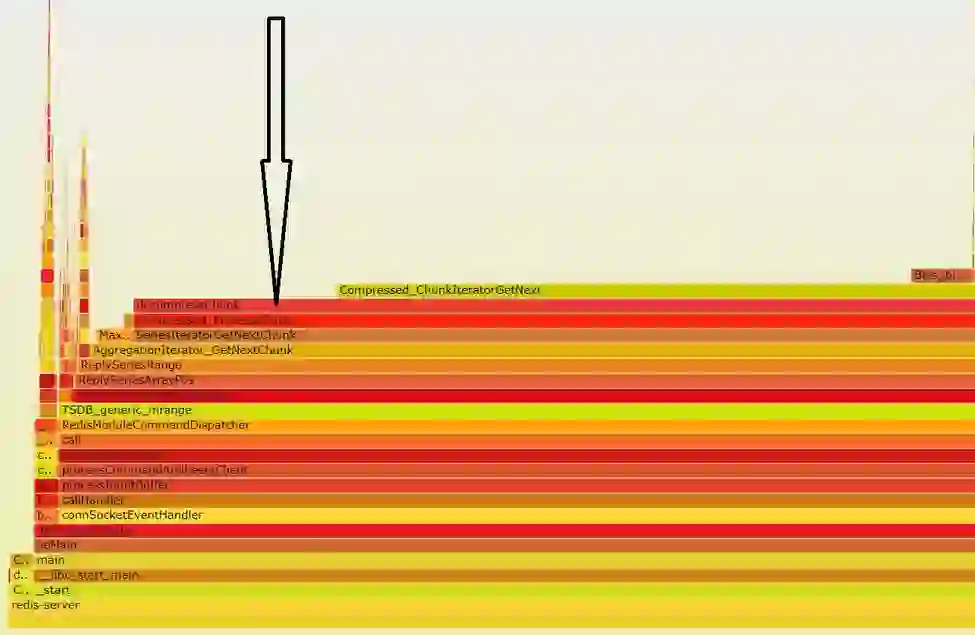
Given that decompression takes up significant CPU resources, Redis teamed up with Intel to investigate. We instrumented RedisTimeSeries to separate the integer timestamps and the floating points values into two separate memory buffers. That permitted us to study their characteristics independently and apply potential optimizations to each data type independently.
Our first idea was to explore vectorizing the compression/decompression computation. A good overview of the techniques used to vectorize compression algorithms can be found in “A general SIMD-based approach to accelerating compression algorithms.” In general, in order to operate on multiple elements concurrently, some regularity must be imposed on the bit widths used for encoding the values. Such imposed regularity may result in sacrificing the compression ratio.
To evaluate, we tested vectorized implementation of different compression algorithms available online at TurboPFor: Fastest Integer Compression using as data the input from the Time Series Benchmark Suite DevOps use case. In our analysis, we discovered that the decompression of the floating point values was the most time-consuming (the integer timestamps were much quicker to decompress), so that’s where we focused our attention. We extracted a trace of floating point values from a dataset and tested it with TurboPFor as well as with our Gorilla implementation.
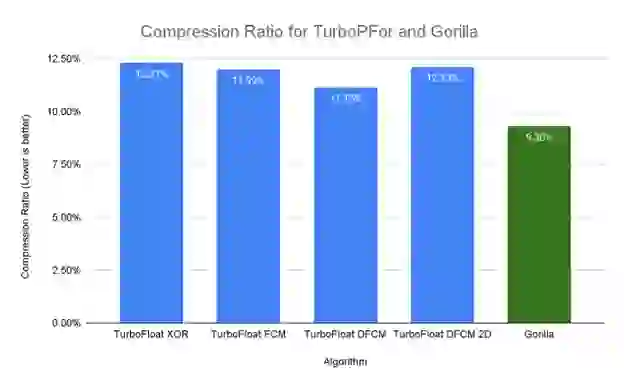
In Figure 2, we show the best-performing algorithms in terms of compression ratio from the TurboPFor library on our dataset. It shows that the TurboFloat DFCM was the best algorithm in terms of compression ratio: The values were compressed to 11.15% of the original. However, the compression ratio with Gorilla for the same dataset was still significantly better at 9.3% or 6.01 bits on average for every 64-bit float.
Since Gorilla offers a better compression ratio than TurboPFor, we decided to stay with the existing algorithm and turn our attention to further fine-tuning the Gorilla implementation.
Next, we delve deeper into the data patterns observed in our dataset for clues for other possible optimizations.
First, we instrumented RedisTimeSeries to print out the number of bits used to encode each integer timestamp and floating point value in a 4K chunk. Most of the time, integer time stamps are compressed to a single bit, which is consistent with the findings in the Gorilla paper. On the other hand, the bit patterns used to encode floating-point values are much more varied and irregular.
These results lead us to conclude that focusing on optimizing double delta floating point decompression through vectorization would not pay off in terms of performance and code complexity. Based on that realization, we decide to delve into other potential optimizations that would not be based upon vectorizing the floating point xor encoding.
We printed out the floating point values in our test dataset and analyzed their characteristics. Doing so helped us discover that in many cases (and also noted in the Gorilla paper), the floating point values are actually integers represented as doubles (e.g. 72.0, 68.0, 71.0). However, as compared to the timestamps, these integer values do not sequentially increase or decrease.
Furthermore, after generating a histogram of the frequency of occurrence of different values, we discovered that only a small number of values (fewer than 128) represent the overwhelming majority of observed data points in our example dataset.
Based on these observations, we believe that we may achieve better performance and/or compression ratio by using a combination of Gorilla and a dictionary and/or run-length encoding. However, we still have to do further analysis with a more extensive set of datasets.
Floating point data may be overkill or an inefficient way to store information. Data usually measures a physical quantity (such as temperature) and sensors have a given range and accuracy. Even stock prices have a resolution of plus or minus one cent.
So an alternative in creating a time series may be to instruct the user to specify a range (e.g. 0-100) and resolution (e.g. 0.01).
The external interface would remain floating point, but internally we could convert the measurements into integers in the most efficient manner (size- and performance-wise).
Based on our analysis of the compression ratio of Gorilla and other fast compression algorithms, our Gorilla algorithm is currently the better compression ratio option. We also explored the characteristics of a typical time-series dataset for ideas about how we might further improve the Gorilla implementation.
Our conclusion: So far, so good. We decided not to make changes to the existing implementation. However, we continue to study the characteristics of different datasets and to evaluate enhancement ideas, such as extending the usage of vectorization to accelerate data processing with RedisTimeSeries, reducing the serialization overhead of our protocol, and even improving the way we store and access our data structures.
This is just an example of the performance explorations Redis is engaging in, made possible by the collaboration between Intel and Redis. If you like what we described so far, we encourage you to check how we’re extending Redis’s ability to pursue core Redis performance regressions and improve database code efficiency, which we detail in Introducing the Redis/Intel Benchmarks Specification for Performance Testing, Profiling, and Analysis.

