

Today we are happy to announce a preview version of RedisAI, in collaboration with [tensor]werk. RedisAI is a Redis module for serving tensors and executing deep learning models. In this blog post, we will walk you through the capabilities of this new module, what it enables and why we believe it’s a game changer for machine learning and deep learning (ML/DL) models.
RedisAI came to light for two core reasons. First, because moving your data to a host that executes your artificial intelligence (AI) model is expensive, and every millisecond counts in today’s instant experiences. Secondly, because serving models have historically been a DevOps challenge. We built RedisAI so you can run your model where the data lives, and easily serve, update and ensemble your models from multiple back ends inside Redis.
To illustrate why we believe colocality (running your ML/DL model where your data lives) matters, let’s consider a chatbot application example. Chatbots typically use recurrent neural networks (RNN), often arranged in seq2seq architectures to present an answer to an input sentence. More advanced models preserve the context of the conversation in the form of a numerical intermediate state tensor, using two input tensors and two output tensors. As an input, the model takes the latest message by the user, and an intermediate state representing the history of the conversation. Its output is a response to the message and the new intermediate state.
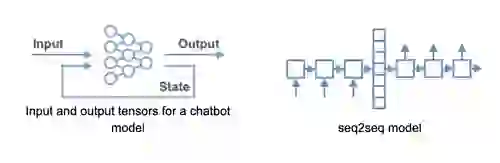
This intermediate state must be kept in a database to support user-specific interaction, just like a session, so Redis is a great choice here. The chatbot’s model could have been deployed in Spark, wrapped in a Flask application or any other DIY solution. Upon receiving a chat request from a user, the serving application needs to fetch the intermediate state from Redis. Since there is no native data type in Redis for a tensor, the database would have to first do some deserialization, and after the RNN model ran, it would have to make sure the latest intermediate state was serialized and sent back to Redis.
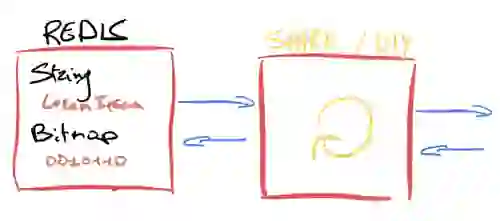
Given the time complexity of a RNN, the wasted CPU cycles on serializing/deserializing and the expensive network overhead, we knew we needed a better solution that could ensure a great user experience.
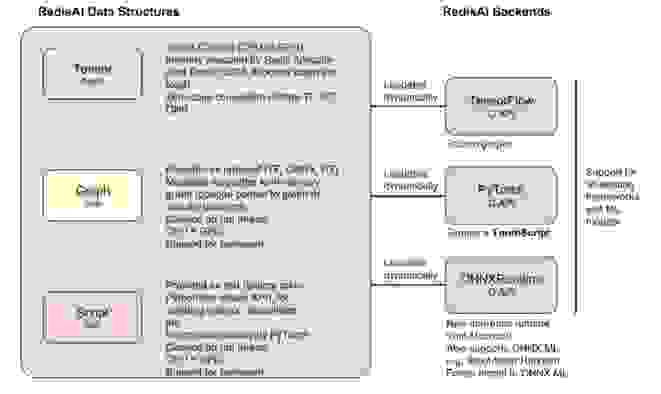
With RedisAI, we’re introducing a new data type called a Tensor. With a set of simple commands, you can get and set Tensors from your favorite client. We’re also introducing two more data types, Models and Scripts, for model runtime features.

Models are set with information about which device they should run on (CPU or GPU) and backend-specific parameters. RedisAI has several integrated backends, such as TensorFlow and Pytorch, and we are working to support ONNXRuntime soon. This runtime for ONNX and ONNX-ML adds support for “traditional” machine learning models. What’s nice, however, is that the command for executing a Model is agnostic of its backend:
AI.MODELRUN model_key INPUTS input_key1 … OUTPUTS output_key1 ..
This allows you to decouple your backend choice (a decision typically made by data scientists), from the application services using these Models to provide functionality. Switching Models is as easy as setting a new key into Redis. RedisAI manages all requests to run Models in processing queues and executes them on separate threads, while Redis stays responsive to all other commands.
Scripts can run both on CPUs and GPUs, and allow you to manipulate Tensors via TorchScript, a Python-like Domain Specific Language for Tensor operations. This lets you pre-process your input data before you execute your Model, and post-process the results, e.g. for ensembling different Models to improve performance.
One more great feature is the ability to run several commands via a directed acyclic graph (DAG) command, which we’ll be adding to RedisAI in the near future. This will allow you to combine several RedisAI commands in one atomic operation, such as running multiple instances of a Model on different devices and ensembling the results by averaging predictions with a script. Using the DAG engine, computations are executed in parallel and then joined. For a full and more in-depth feature list, visit redisai.io.
The new architecture could be simplified like this:

Taking code straight out of your Jupyter notebooks and placing it in a flask app might not provide the best guarantees in production. How can you be sure you’re using your resources optimally? What happens with the intermediate state of our chatbot example when your host goes down? You might end up reinventing the wheel of existing Redis functionality.
On the other hand, dealing with very opinionated solutions might be challenging, as they tend to be less composable than you’d expect.
The goal of RedisAI is to bring the Redis philosophy to the task of serving AI models. Since we’re implementing Tensors, Models and Scripts as full-blown Redis data structures, they inherit all the enterprise-grade features of Redis. If you need to scale model serving, you can simply scale your Redis cluster. You can also use Redis Enterprise’s high availability features to make sure your Model and Tensors are always available. Since Redis scales easily, you can add as many Models as you want or need to run in production, lowering your infrastructure cost and total cost of ownership.
Lastly, RedisAI fits perfectly in the existing Redis ecosystem, allowing you to do everything from reusing Streams for input data and classified output data streams, using RedisGears to make correct translations between data structures, to adopting RedisGraph to keep your ontology up-to-date and more.
In the short term, we want to make RedisAI generally available including its support for the three main ML/DL backends (Tensorflow, Pytorch and ONNXRuntime). In our next phase, we would like those backends to be loaded dynamically, which will allow you to load only the specific backends you need for the devices you want to run them on. For example, this would allow you to use Tensorflow Lite for your Edge use cases.
Another feature we plan to implement in the near future is called autobatching, which will look into queues and automatically consolidate calls to the same Models to squeeze the last bits of efficiency. Furthermore, RedisAI will also expose metrics about how well your Models are behaving, and we’ll look into the DAG feature explained earlier.
We’re looking forward to hearing all your feedback, so please get in touch or comment on github.



