

Last week, we released RedisGraph 1.2.0. If you’ve been using RedisGraph or considering trying out the module, this is a good time to see what we’ve been up to as we continue to enhance its graph processing capabilities. Let’s review some of the more notable additions in the new release:

Up until this release, connecting node A to node B via an edge of type R and then forming another connection of the same type between the two was not possible. as the latter would overwrite the former one, because of the way connections used to be represented in RedisGraph.
For every relation type, e.g. `friend`, `works_at` or `owns`, RedisGraph maintains a mapping matrix M, in which M[I,J] = EdgeID where I and J are the source and destination node IDs, respectively. Forming the first connection of type R between A and B would have M[I,J] set to X, and introducing a second edge of type R between the two would overwrite M[I,J] with Y.

With release 1.2.0, RedisGraph now enables multiple edges of the same type. Our mapping matrix M can hold a pointer to an array of edge IDs, M[I,J] = [ID0, ID1, … IDn], specifying each edge of type R connecting I to J.
To avoid high memory fragmentation, consider a graph with 500 million edges none of which share source or destination nodes, i.e. no multiple edges of the same type between any two nodes. A naive approach would have allocated 500M arrays of length 1, increasing our memory consumption significantly. To encounter this, our mapping matrix entry type remained the same (UINT64). Starting with an empty graph – M[I,J] is empty – when the first edge E is formed, connecting I to J, M[I,J] = ID(E) is a simple constant and no extra memory is allocated. At some point, I is connected once again to J with an edge X of the same type as E, M[I,J] = [ID(E), ID(X)], an array is allocated and a pointer is placed in M[I,J].
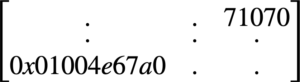
Whenever a graph entity (Node, Edge) is created, an internal unique ID is assigned to it. This ID is immutable throughout the entity life, and you can retrieve an entity ID by using the ID function: MATCH (N) RETURN N, ID(N) LIMIT 10. Similarly, finding a node by its ID: “MATCH (N) WHERE ID(N) = 9 RETURN N” used to perform a full scan, inspecting each node in the graph.
Our latest release of RedisGraph introduces an optimization that replaces these full-scan and filter operations with a single `seek node by id` operation, which runs in constant time.


In RedisGraph, traversals are performed by matrix multiplication. For example, consider the search pattern: (A)-[X]->(B)-[Y]->(c). To find all source nodes (A) that are connected to destination nodes (C), we’re simply multiplying matrix [X] by matrix [Y], X*Y=Z, and Z’s rows and columns represent A and C respectively.
If we’re interested in just a handful of C nodes, we’ll want to avoid performing X*Y, as these might be very large matrices. As such, we’ll tack on a small filter matrix F, (F*X)*Y. By multiplying F*X first, we’re reducing any intermediate matrix computed dimensions, dramatically reducing computation time.
Depending on the result of F*X*Y, we might find ourselves computing a different filter matrix F and re-evaluating this expression to get additional C nodes. This process may repeat itself several times before we have enough data. Now, whenever a search pattern contains left-to-right and right-to-left edges: (A)-[X]->(B)<-[Y]-(C), we’ll have to transpose Y, (F*X)*Transpose(Y) = Z.

Previous versions of RedisGraph transposed Y on every evaluation of this expression, which was costly. Now, as of release 1.2.0, we’ll only transpose once on the first evaluation. Although this results in higher memory consumption per query, the latency gain is definitely worth it.
Overall RedisGraph 1.2.0 (release notes) contains both overdue features and some interesting optimizations, give it a try let us know what you think!


