


Introduction To Caching With Redis
Learn more
Ein schneller, hochverfügbarer, robuster und skalierbarer Caching-Layer für alle Clouds
Mit der Zwischenspeicherung können Daten, die in langsameren Datenbanken gespeichert sind, eine Leistung von weniger als einer Millisekunde erreichen. Das hilft Unternehmen, auf den Bedarf an Echtzeitanwendungen zu reagieren.
Aber nicht alle Caches können geschäftskritische Anwendungen betreiben. Viele verfehlen das Ziel.
Redis Enterprise wurde für das Caching in großem Maßstab entwickelt. Seine unternehmenstauglichen Funktionen sorgen dafür, dass kritische Anwendungen zuverlässig und superschnell laufen, und bieten gleichzeitig Integrationen, die das Caching vereinfachen und Zeit und Geld sparen.

| Grundlegendes Caching | Erweitertes Caching | |
|---|---|---|
| Latenzzeit unter einer Millisekunde | • | • |
| Kann als Key:Value-Datenspeicher eine Vielzahl von Datenbanken beschleunigen | • | • |
| Hybride und Multicloud-Bereitstellung | • | |
| Lineare Skalierung ohne Leistungseinbußen | • | |
| Fünfmalige Hochverfügbarkeit für jederzeitigen Datenzugriff | • | |
| Lokale Lese-/Schreiblatenz vor Ort, in verschiedenen Clouds und an verschiedenen Standorten | • | |
| Kosteneffizient für große Datenmengen mit Storage Tiering und Multitenancy | • | |
| Ein hervorragendes Support-Team mit definierten SLAs | • | |
| Geht über Schlüssel:Wert-Datentypen hinaus und unterstützt moderne Anwendungsfälle und Datenmodellea | • |

Kann Ihr Cache den Anforderungen moderner Anwendungen gerecht werden?
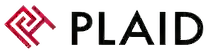


Um mehr zu erfahren, lesen Sie The Definitive Guide to Caching at Scale
Redis Enterprise arbeitet mit Ihrer Architeaktur Wir bieten mehrere Optionen an, von denen eine sicher auch Ihren Bedürfnissen entspricht.
Dies ist die häufigste Art, Redis als Cache zu verwenden. Cache-aside ist eine ausgezeichnete Wahl für leseintensive Anwendungen, bei denen Cache-Misses akzeptabel sind. Bei der Verwendung eines Cache-Aside-Musters übernimmt die Anwendung alle Datenoperationen und kommuniziert direkt mit dem Cache und der Datenbank.
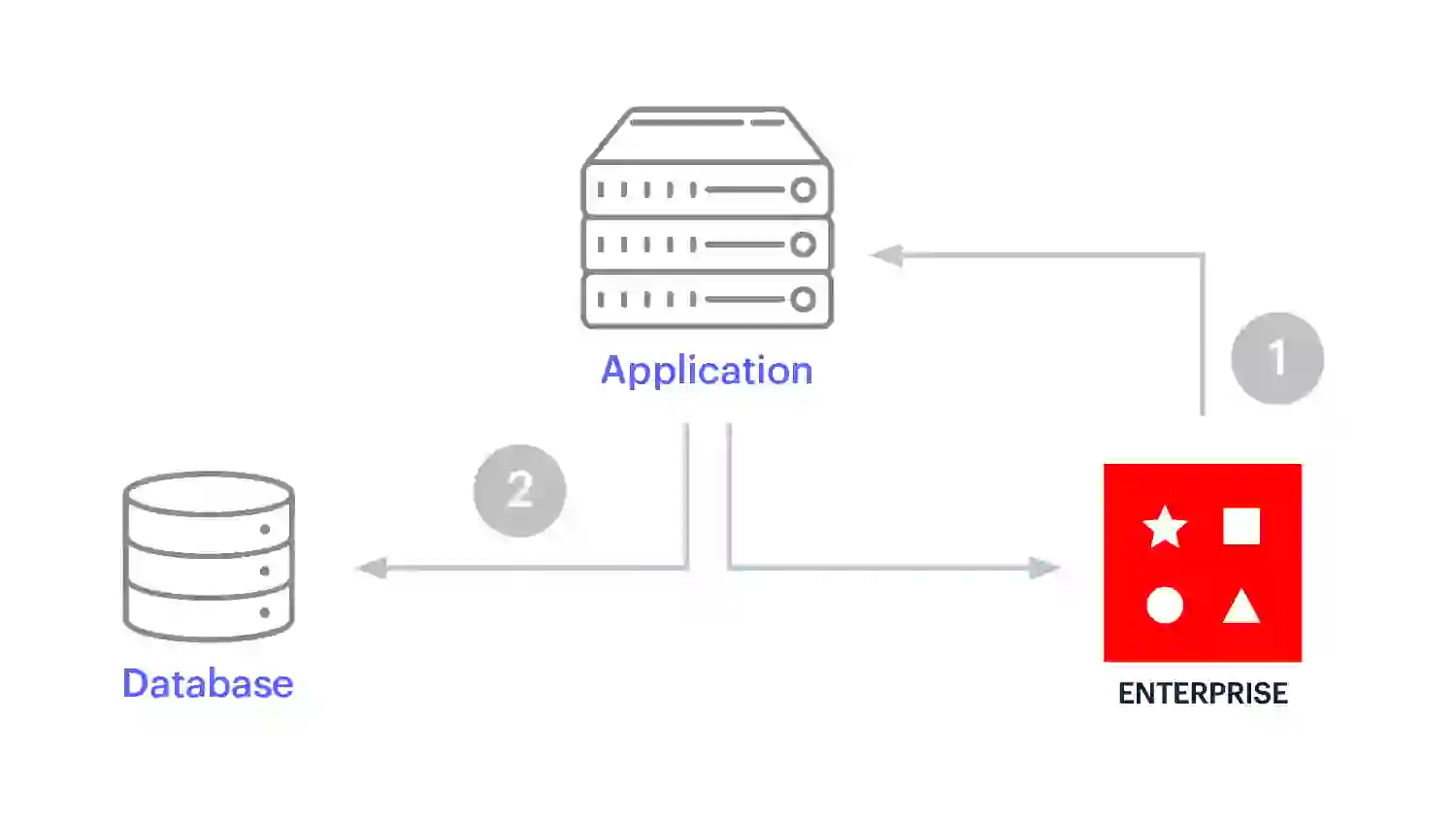
Abfrage-Caching ist eine einfache Implementierung des Cache-Aside-Musters, bei dem keine Umwandlung von Daten in eine andere Datenstruktur erfolgt. Dieses Muster ist eine beliebte Wahl, wenn Entwickler wiederholte einfache SQL-Abfragen beschleunigen wollen oder wenn sie zu Microservices migrieren müssen, ohne ihre aktuellen Systeme neu zu formatieren.
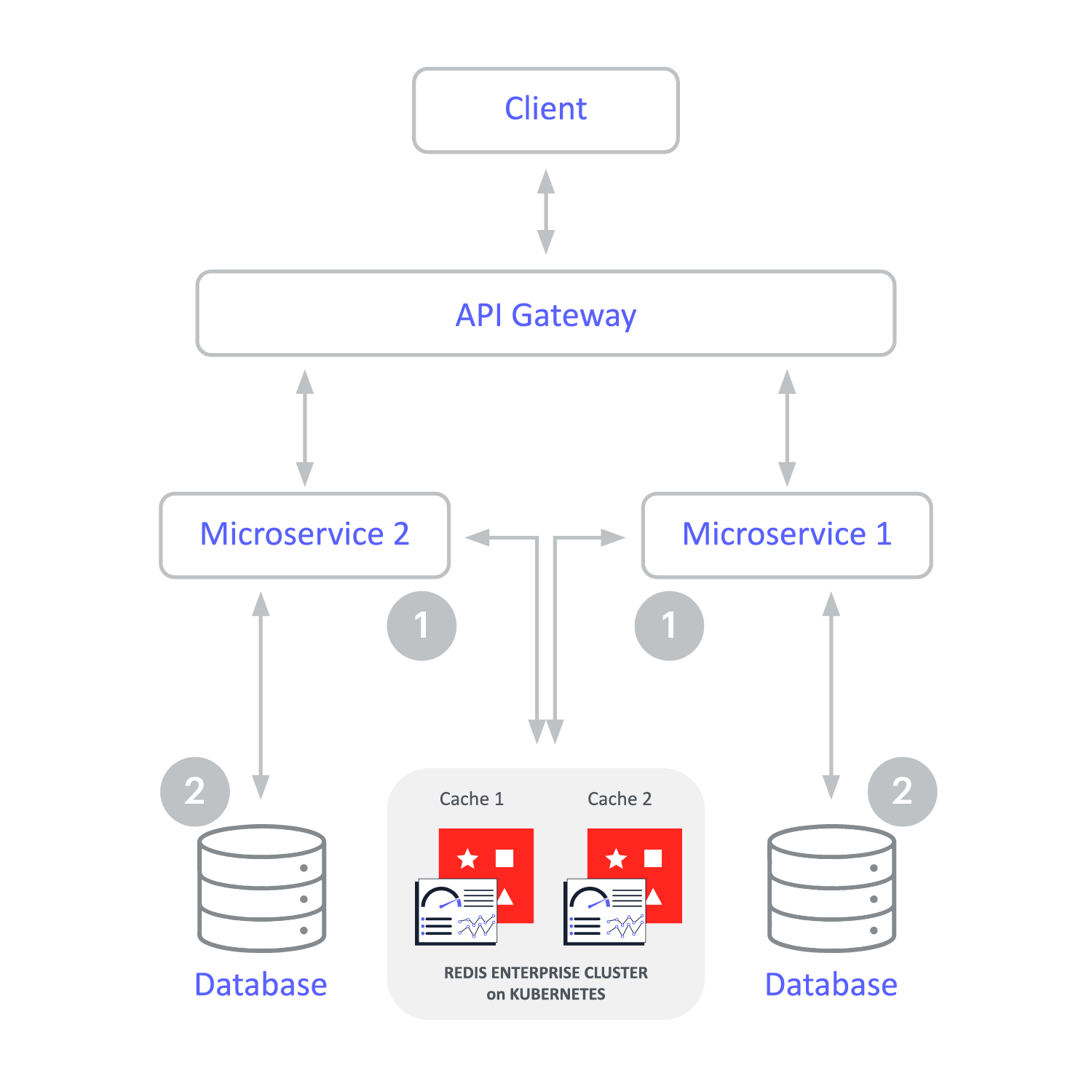
Write-Behind-Caching verbessert die Schreibleistung. Die Anwendung schreibt nur an einer Stelle – dem Redis Enterprise-Cache – und Redis Enterprise aktualisiert asynchron die Backend-Datenbank. Das vereinfacht die Entwicklung.
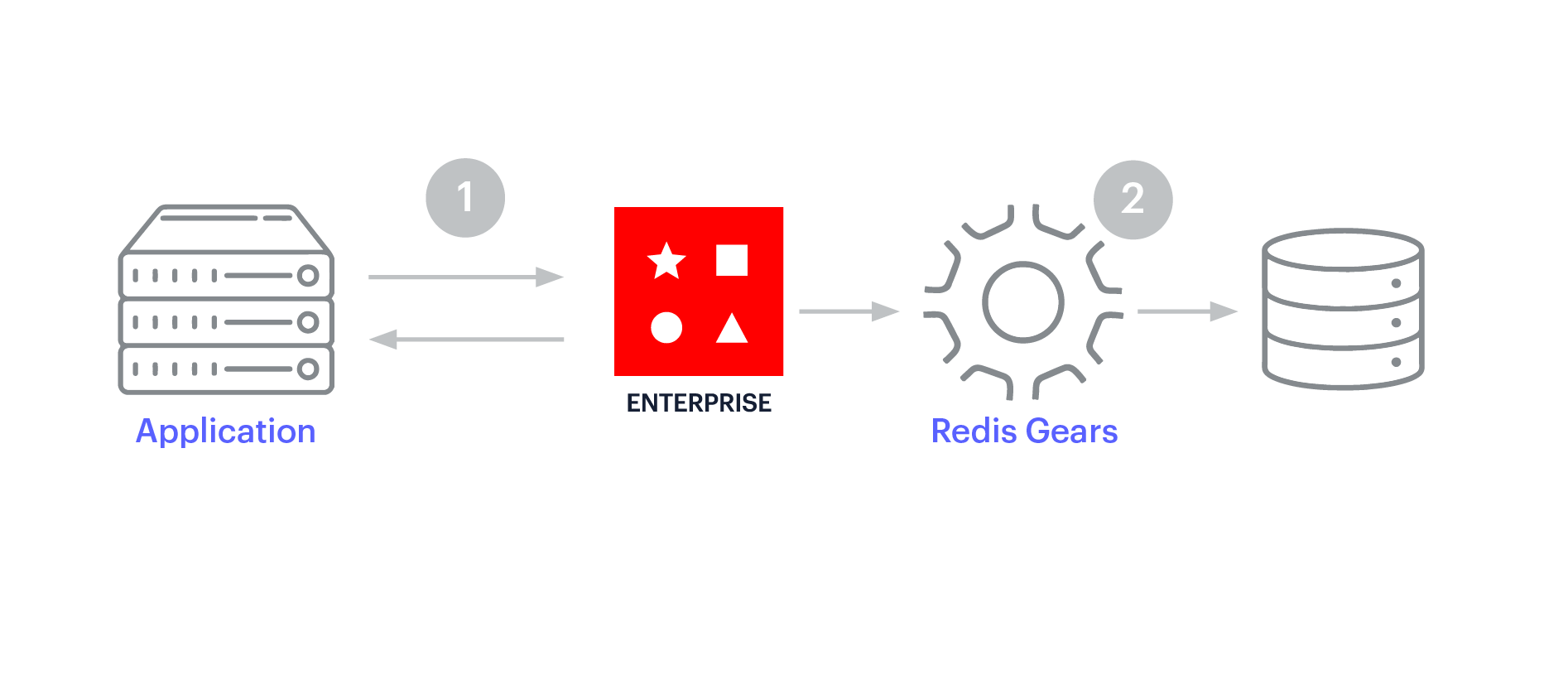
Das Write-Through-Caching ähnelt dem Write-Behind-Caching insofern, als sich der Cache zwischen der Anwendung und dem operativen Datenspeicher befindet. Beim Write-Through-Caching sind die Aktualisierungen im Cache jedoch synchron und fließen durch den Cache zur Datenbank. Das Write-Through-Muster begünstigt die Datenkonsistenz zwischen dem Cache und dem Datenspeicher.
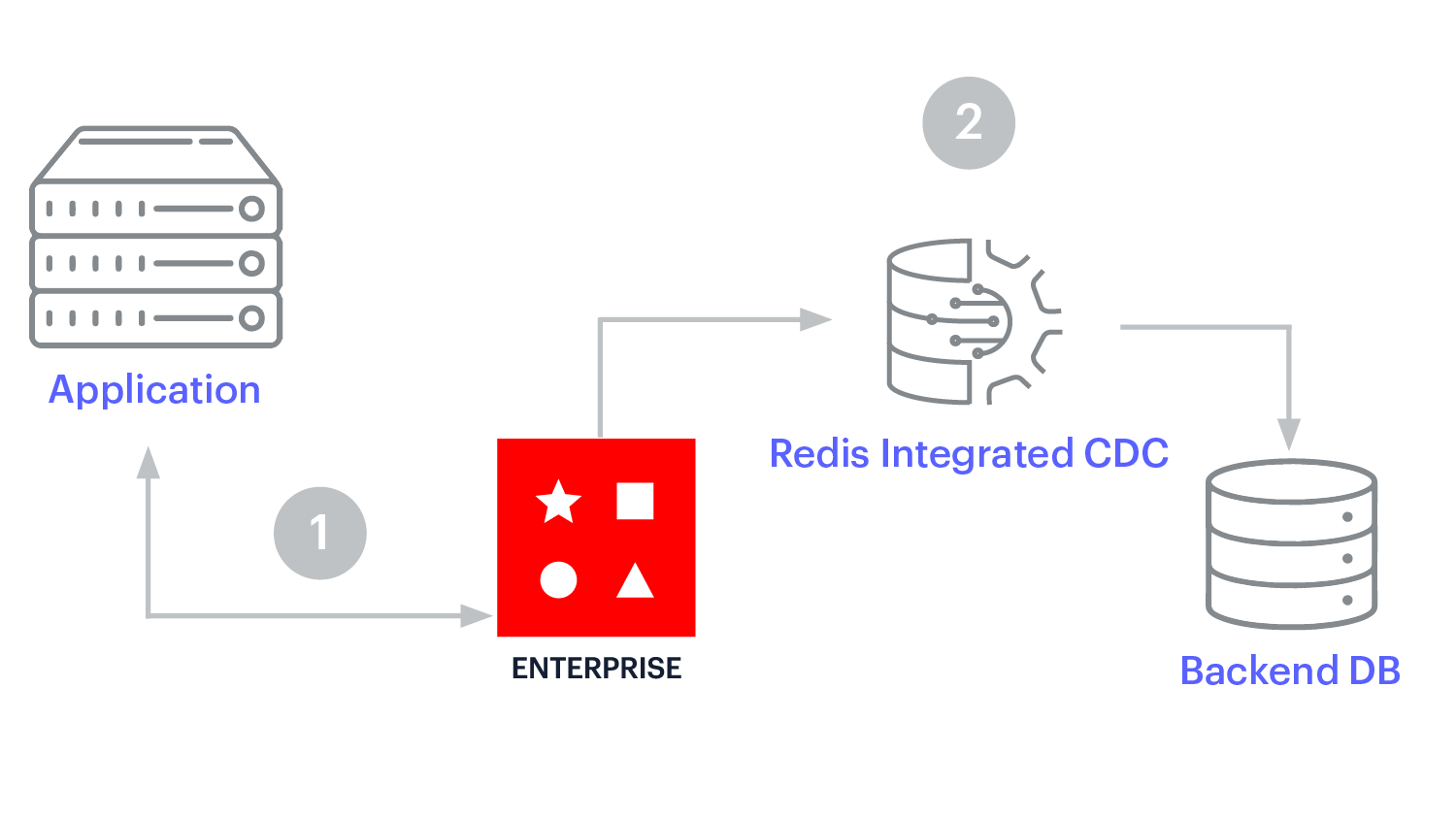
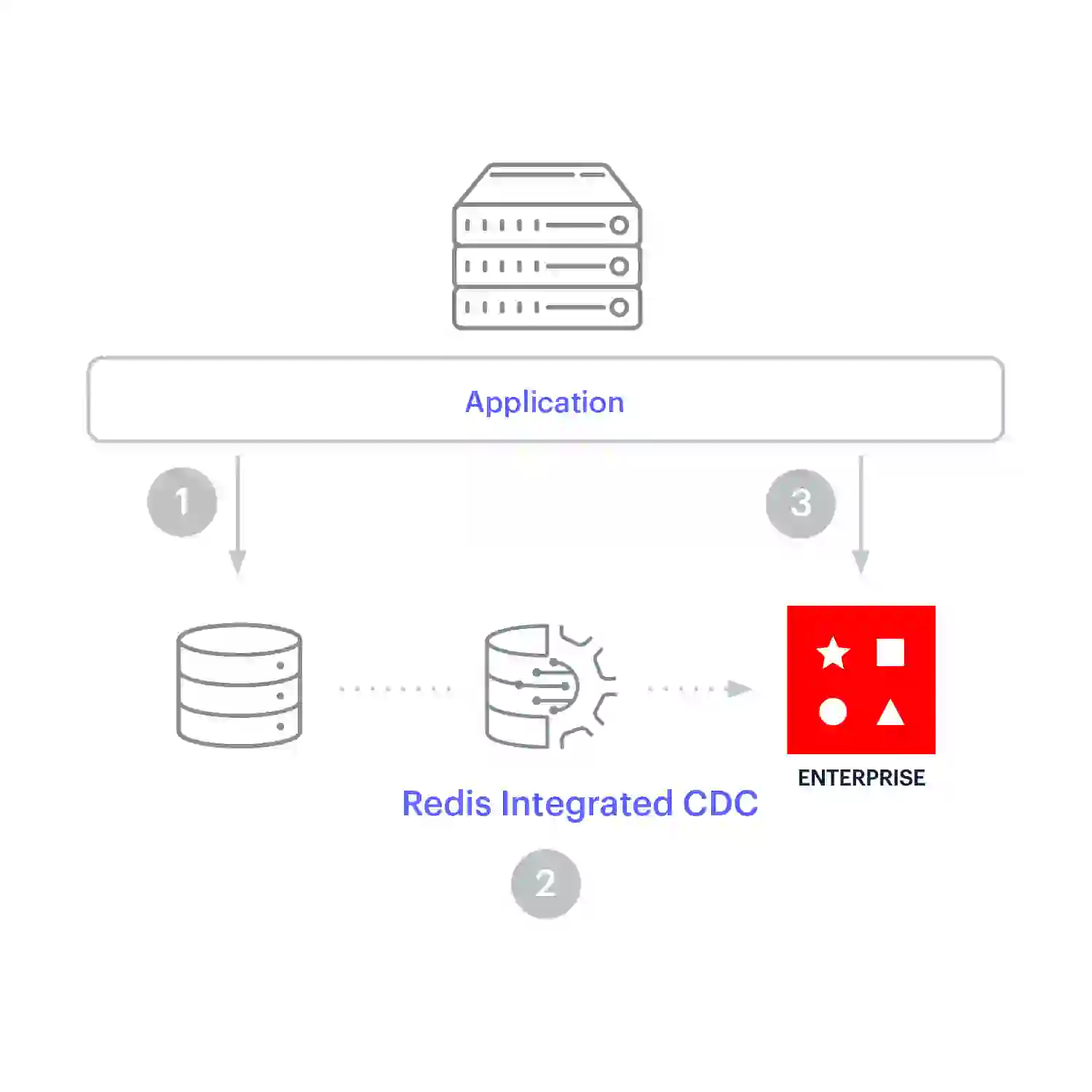
Cache-Prefetching wird für die kontinuierliche Replikation verwendet, wenn schreiboptimierte und leseoptimierte Arbeitslasten synchron bleiben müssen. Bei diesem Caching-Muster schreibt die Anwendung direkt in die Datenbank. Die Daten werden in Redis Enterprise repliziert, sobald sie sich im Aufzeichnungssystem ändern, sodass die Daten im Cache ankommen, bevor die Anwendung sie lesen muss.
Hält die Leistung im Sub-Millisekundenbereich bei bis zu 200 Millionen Operationen pro Sekunde aufrecht
Unterstützt durch eine 99,999%ige Betriebszeit-SLA
Multi-Tenancy und Tiered Storage senken die Kosten und ermöglichen Einasparungen von bis zu 80 %.
Nahtlose Nutzung einer einzigen Plattform vor Ort, in jeder Cloud und in hybriden Architekturen
Ein hochqualifiziertes Team von Redis-Experten ist rund um die Uhr verfügbar, um Ihren Cache zu betreiben, zu skalieren, zu überwachen und zu unterstützen.
Learn more

Learn more

Learn more

Learn more

Learn more

Learn more