When something persists, it lasts. In the context of databases, that means you intend for a piece of information that is going to be saved in some way (in memory or on disk) for some period of time, so that it can be recovered even if a computer process is killed. With data persistence, existing data from an application stays intact between sessions, preserving it for use in a following application session without suffering data loss. Data persistence is particularly essential in the event of a server restart, because data stored only in-memory is gone when the power flickers.
Redis Enterprise is a fully durable database that serves all data directly from memory, using either RAM or Redis on Flash. With regards to persistent data, Redis only reads this data when both the primary and secondary shards in a high-availability database are lost.
Redis supports append-only file data persistence (AOF) as well as snapshotting. It is also possible to use both RDB and AOF together, known as “hybrid persistence” to take advantage of the strengths of both options. Lets dive into to each of the Redis data persistence options below with further explanation and more detailed information about the strengths and weaknesses of each.
Append-only file (AOF) is a logging mechanism that writes to a log file on disk every write operation performed on a Redis database. The log file is used to reconstruct the database in the event of a crash or failure.
AOF works by appending each database write operation to the end of the log file, hence the name append-only file. When Redis restarts, it reads the log file and re-executes the write operations preserved in the file to restore the database to its previous state.
AOF provides better data durability than the snapshot persistence option, creating only point-in-time data snapshots.
Redis uses a multi-part AOF mechanism, wherein the original AOF splits into base and incremental files. The base file represents an initial snapshot of the data present when the AOF is written. The incremental files contain changes since the last base AOF was created.
You can configure AOFs to be rewritten in the background when it gets too large, using a process called AOF fsync. The fsync configuration directive controls how often the AOF log file is synchronized to disk.
The latest AOF mechanism implementation reduces the memory consumption and the amount of I/O operations that are performed during an AOF rewrite.
A snapshot is a point-in-time copy of the Redis data stored in memory. Snapshots are created using the Redis DataBase (RDB) persistence option, which allows the state of the Redis database to be saved to disk at specified intervals.When an RDB snapshot is taken, Redis creates a child process to perform the snapshotting, allowing the main process to continue serving requests.
Snapshots are useful for creating backups of the Redis database, as well as for migrating data between Redis instances. They can be created manually using the ‘SAVE’ or ‘BGSAVE’ command, or automatically using the ‘save’ configuration directive in the Redis configuration file.
It is important to note that while snapshots allow the data in Redis to be persisted to disk, they do not provide the same level of data durability as the AOF persistence option. AOF writes every write operation performed on the Redis database to a log file on disk, which can be used to reconstruct the database in the event of a crash or failure.
Snapshots and backup are designed for two different things. While snapshot supports data durability (i.e. to automatically recover data when there is no copy of the dataset in memory), backup supports disaster recovery (i.e. when the entire cluster needs to be rebuilt from scratch).
Data durability refers to the ability of data to remain stored and accessible over a period of time, even in the face of various types of failures or disasters. Data availability, on the other hand, refers to the ability of users to access and use the data when needed.
Data availability involves designing systems and processes that allow users to access and use the data when needed. This can involve desinging systems with high uptime and fast response times, as well as implementing failover and load balancing mechanisms to ensure that the data is alaways available to users, even if some of the systems fail.
For a data center, availability is an important metric as is durability. A data center will support persistence by using redundant storage systems, such as storage are networks (SANs) or network-attached storage (NAS) systems. These systems provide multiple copies of data, so that if one copy becomes unavailable, there are other copies that can be accessed.
See our blog Data Durability and Availability for more information on this topic.
In cloud native deployments such as a public cloud, private cloud, or virtual private cloud, ephemeral (instance) storage cannot be used for data durability purposes.
Ephemeral storage, or volatile temporary storage, disposes of data once its corresponding container reaches the end of its lifespan.
Instead, a network-attached storage (NAS) like Amazon Elastic Block Store (EBS), Microsoft Azure Disk Storage, or Google Cloud Platform Persistent Disk is required. That’s because, just as it sounds, ephemeral storage is ephemeral! When a cloud instance fails (which is relatively common), the contents of its local disk are also lost.
Persistent storage, also known as non-volatile storage, refers to any storage device capable of keeping data intact and available when it is no longer powered on.
Persistent storage is useful for maintaining critical data and making it available for later use. A hard disk drive is a common example of a persistent storage device.
The Redis Enterprise cluster is designed to work with network-attached storage for persistent data. By default, every node in the cluster is connected to a network-attached storage resource, making the cluster immune to data-loss events such as multiple node failures with no copies of the dataset left in DRAM. This data durability-proven architecture is illustrated here:

As illustrated above, in cases where there is no copy of the dataset left in DRAM, Redis Enterprise will find the most recent copy of the dataset in the network-attached devices that were connected to the failed node, and use that to populate the Redis shard on the new cloud instance.
By default, when data persistence is enabled Redis Enterprise sets data persistence at the replica of each shard of the database. In this configuration there is no impact on performance, as the primary shard is not affected by the slowness of the disk; on the other hand, replication adds latencies that may break the data persistence SLA. Therefore, Redis Enterprise allows you to enable data persistence on both the primary and replica shards. This is a more reliable configuration that doesn’t infringe on your data persistence SLA, but if the disk speed cannot cope with the throughput of ‘writes,’ it will affect the latency of your database, as Redis delays its processing when it cannot commit to disk. If you use Redis Enterprise DBaaS deployments (Cloud or VPC) you will automatically be tuned to work with a storage engine and the right shards configuration to support your persistent storage load; in an on-premises deployment, we recommend you consult with Redis solutions architects regarding your sizing. Data persistence options are shown here:

Redis Enterprise enhances the Redis storage engine to increase the throughput of the Redis core with data persistence enabled, and to better utilize cluster resources by allowing multiple Redis instances to run on the same cluster node without affecting performance:
A storage engine benchmark performed by Dell-EMC and Redis showed that when using Redis Enterprise’s enhanced storage engine with Dell-EMC VMAX, Redis performance is nearly unaffected by AOF every-write operation, as shown here:
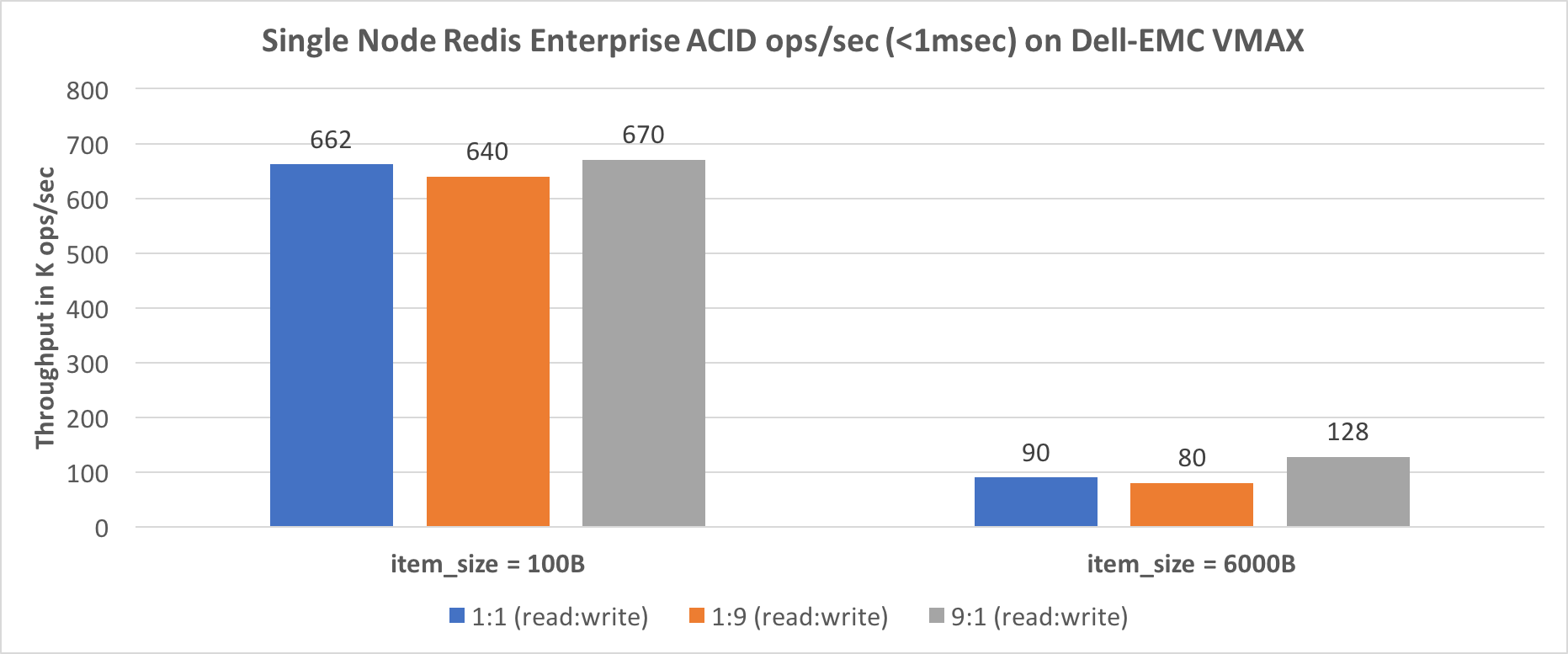
More information on this benchmark can be found here:


Also known as non-volatile storage, persistent storage refers to a device that keeps data intact and accessible, even when the storage device has no power.
It is synonymous with persistent storage. Non-volatile storage refers to a storage device whose data suffers no loss from its loss of power.
This layer is included in an application’s stack to facilitate the retrieval of data found in persistent storage. A persistence layer strategy is dependent on the chosen application’s data structure. NoSQL databases require a different kind of data layer implementation than relational databases, for example.
It enables critical data to be readily accessible when needed, as its persistence is not tied to the lifespan of a container or to the electrical power of a storage device.
If an application is closed, persistent data enables that data to be fully available for the application’s following session, whereas non-persistent data becomes irretrievable if any writes are performed mid-termination.
Data persistence has drastically shaped modern digital experiences. Take streaming, for example. Suppose a customer is watching a series in Michigan, but pauses the show midway to catch an international flight. The expectation is that the following session, even a session halfway across the globe, should allow the customer to have immediate access to the data upon request. The seamless continuity of available data, even across geographical regions and multiple sessions, is an example of data persistence.
Cloud storage is a service that allows you to store data on remote servers that are accessed over the internet, rather than on your local computer or on-site data storage systems. With cloud storage, you can storage and access your data from any device that has an internet connection. Some examples of cloud storage services include Google Drive, Microsoft OneDrive, and Dropbox.
Watch our recent Tech Talk on Buy vs Build: Disaster Recovery in Redis Open Source vs Redis Enterprise

Next section ► Backup, Restore, and Cluster Recovery

