


Introduction To Caching With Redis
Learn more
Una capa de almacenamiento en caché rápida, de alta disponibilidad, resistente y escalable que abarca nubes, sistemas in situ e híbridos.
Con el almacenamiento en caché, los datos almacenados en bases de datos más lentas pueden lograr un rendimiento inferior al milisegundo. Eso ayuda a las empresas a responder a la necesidad de aplicaciones en tiempo real.
Pero no todas las cachés pueden impulsar aplicaciones de misión crítica. Muchas no alcanzan el objetivo.
Redis Enterprise está diseñado para el almacenamiento en caché a escala. Su funcionalidad de nivel empresarial garantiza que las aplicaciones críticas se ejecuten de manera fiable y súper rápida, al tiempo que brinda integraciones para simplificar el almacenamiento en caché y ahorrar tiempo y dinero.

| Almacenamiento en caché básico | Almacenamiento en caché avanzado | |
|---|---|---|
| Latencia de submilisegundos | • | • |
| Puede acelerar una amplia variedad de bases de datos como almacén de datos clave:valor | • | • |
| Despliegue híbrido y multinube | • | |
| Escalado lineal sin degradación del rendimiento | • | |
| Cinco nueves de alta disponibilidad para acceso a datos siempre activo | • | |
| Latencia local de lectura/escritura en las instalaciones, múltiples nubes y geografías | • | |
| Rentable para grandes conjuntos de datos con niveles de almacenamiento y multiusuario | • | |
| Un equipo de soporte superior con SLA (acuerdos de nivel de servicio) definidos | • | |
| Va más allá de los tipos de datos clave:valor para admitir casos de uso y modelos de datos modernos | • |

¿Puede su caché hacer frente a las necesidades de las aplicaciones modernas?
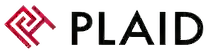


Para obtener más información, lea La guía definitiva para el almacenamiento en caché a escala
Los patrones de almacenamiento en caché deben coincidir con el escenario de la aplicación. Ofrecemos varias opciones,
una de las cuales seguramente satisfará sus necesidades.
Esta es la forma más común de utilizar Redis como caché. Caché al margen es una excelente opción para aplicaciones de lectura intensiva cuando los fallos de caché son aceptables. La aplicación maneja todas las operaciones de datos cuando usa un patrón de caché al margen y se comunica directamente con la caché y la base de datos.
El almacenamiento en caché de consultas es una implementación simple del patrón de Caché al margen donde no hay transformación de datos en otra estructura de datos. Este patrón es una opción popular cuando los desarrolladores buscan acelerar las consultas SQL simples repetidas o cuando necesitan migrar a microservicios sin cambiar la plataforma de sus sistemas de registro actuales.
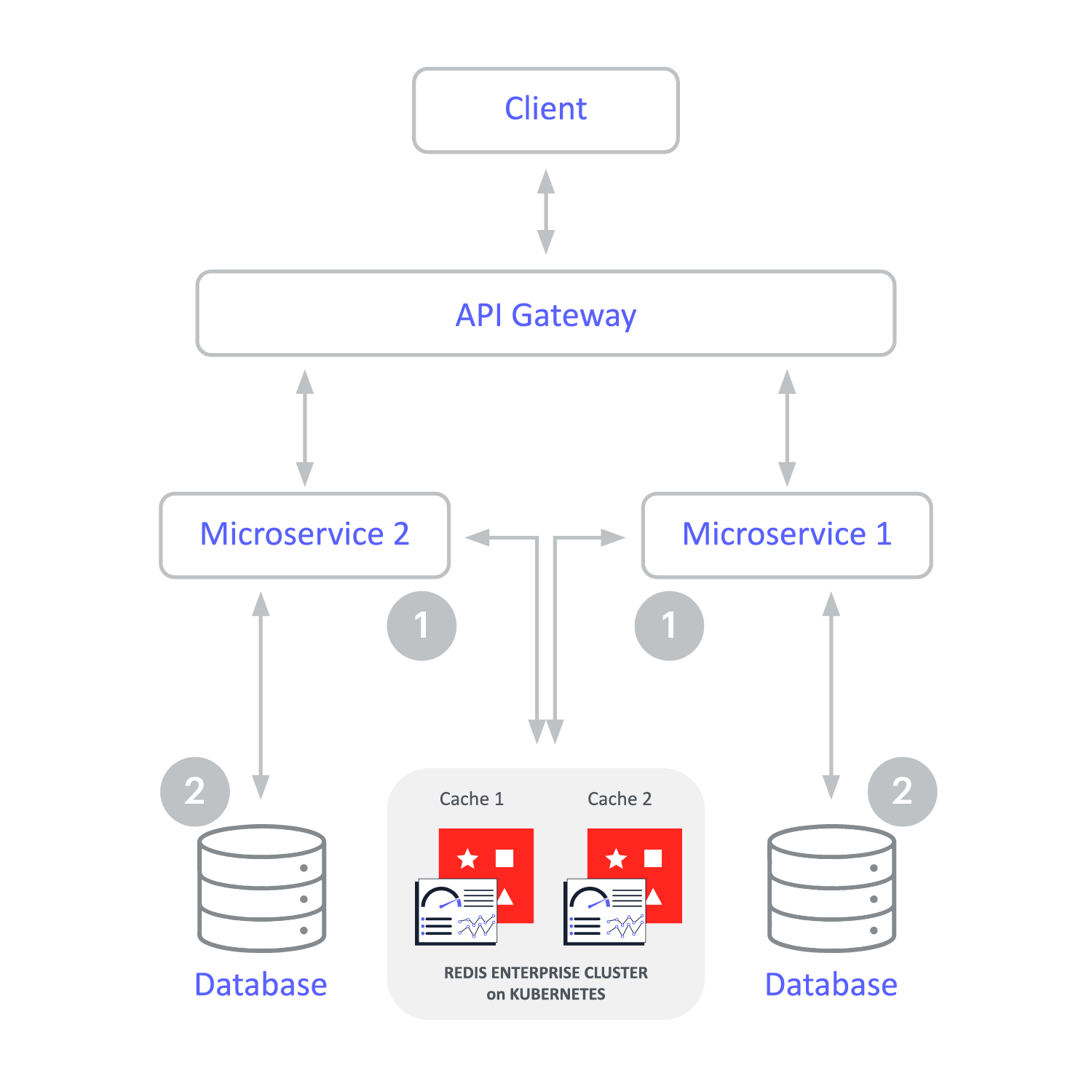
El almacenamiento en caché de escritura indirecta mejora el rendimiento de escritura. La aplicación escribe en un solo lugar, la memoria caché de Redis Enterprise, y Redis Enterprise actualiza de forma asincrónica la base de datos de back-end. Eso simplifica el desarrollo.
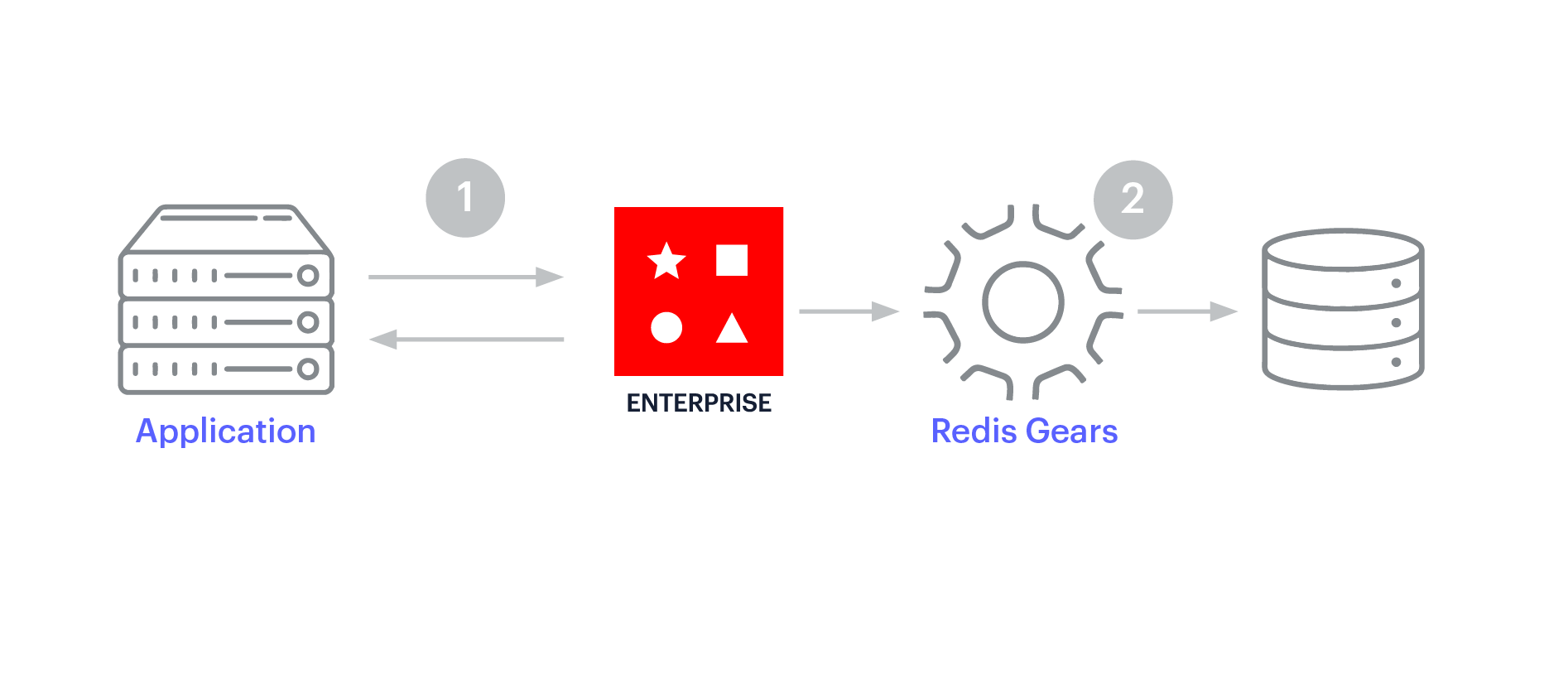
El almacenamiento en caché de escritura directa es similar a la caché de escritura indirecta, ya que la caché se encuentra entre la aplicación y el almacén de datos operativos. Sin embargo, con el almacenamiento en caché de escritura directa, las actualizaciones de la memoria caché son síncronas y fluyen a través de la memoria caché hasta la base de datos. El patrón de escritura directa favorece la consistencia de los datos entre la memoria caché y el almacén de datos.
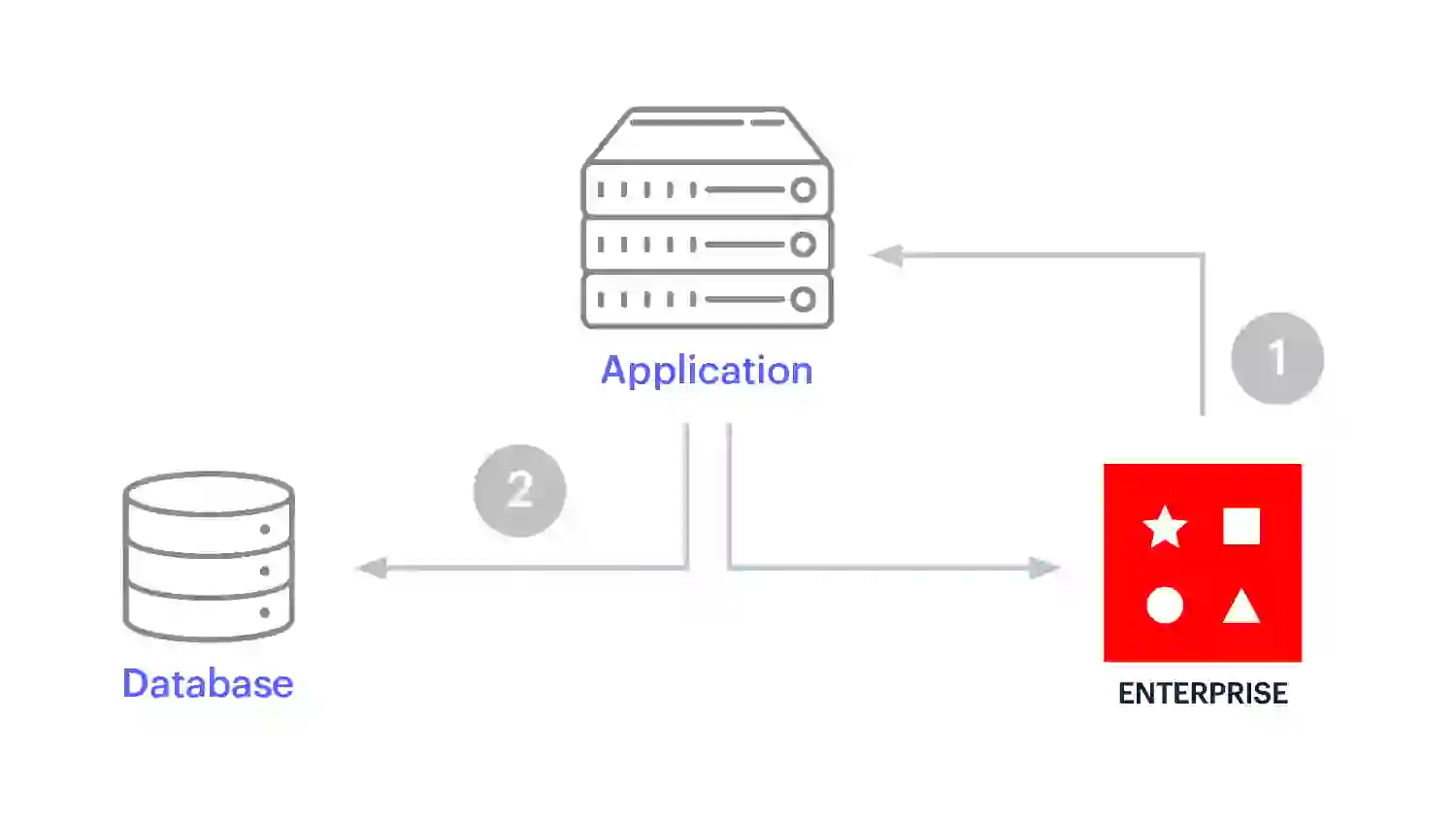
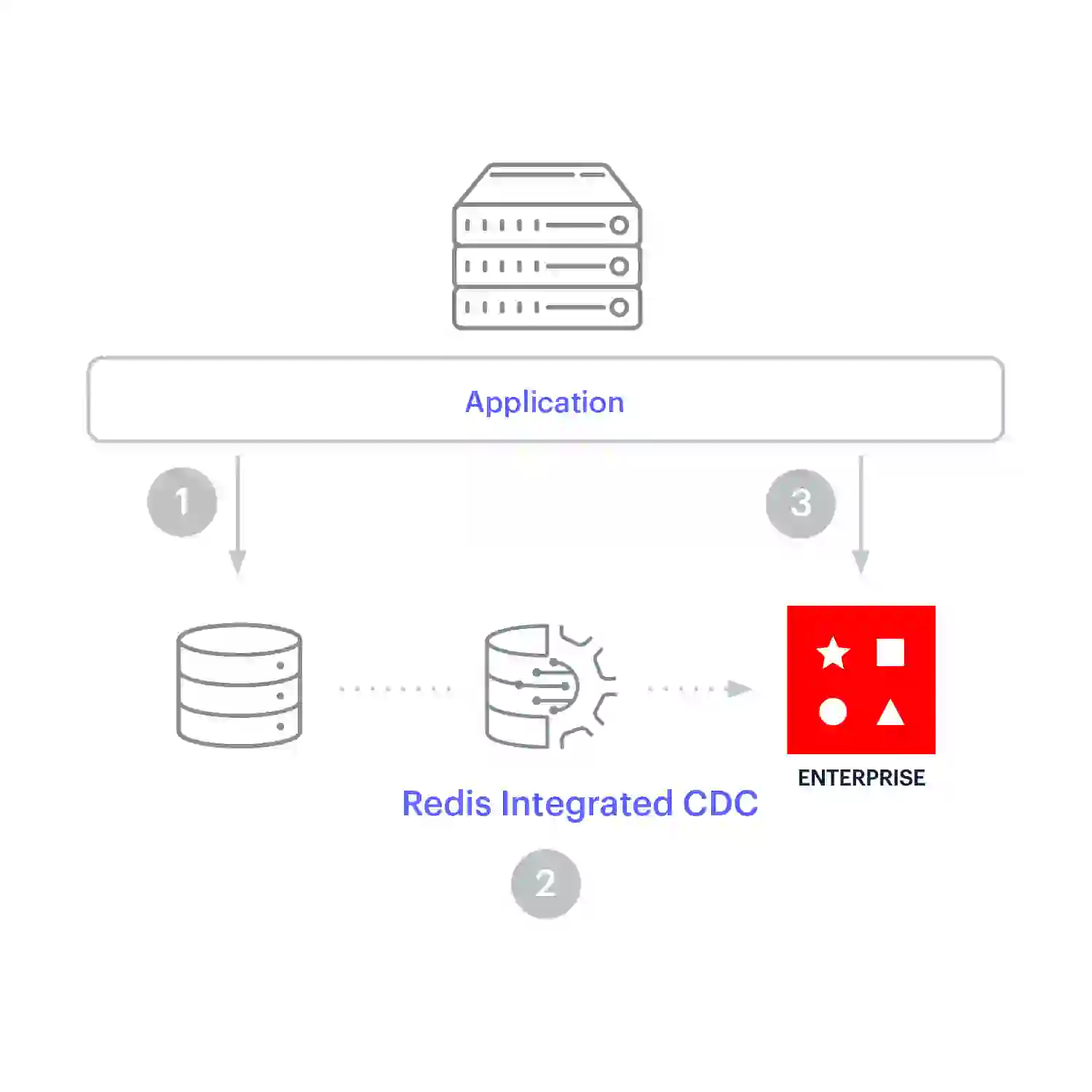
La obtención previa de caché se utiliza para la replicación continua cuando las cargas de trabajo optimizadas para escritura y lectura tienen que permanecer sincronizadas. Con este patrón de almacenamiento en caché, la aplicación escribe directamente en la base de datos. Los datos se replican en Redis Enterprise a medida que cambian en el sistema de registro, por lo que llegan a la memoria caché antes de que la aplicación necesite leerlos.
Mantiene un rendimiento de submilisegundos de hasta 200 millones de operaciones por segundo
Respaldado por un SLA de tiempo de actividad del 99,999 %
El almacenamiento multi-arrendamiento y en niveles reduce el coste y proporciona hasta un 80 % de ahorro
Utilice sin problemas una sola plataforma en las instalaciones, en cualquier nube y en arquitecturas híbridas
Un equipo altamente capacitado de expertos de Redis está disponible las 24 horas del día, los 7 días de la semana para operar, escalar, monitorizar y respaldar su caché
Learn more

Learn more

Learn more

Learn more

Learn more

Learn more