


Introduction To Caching With Redis
Learn more
Une couche de mise en cache rapide, hautement disponible, résiliente et évolutive qui s’étend sur les clouds, sur site et hybride
Avec la mise en cache, les données stockées dans des bases de données plus lentes peuvent atteindre des performances inférieures à la milliseconde. Cela aide les entreprises à répondre au besoin d’applications en temps réel.
Cependant, tous les caches ne peuvent pas alimenter les applications critiques. Beaucoup n’atteignent pas l’objectif.
Redis Enterprise est conçu pour la mise en cache à grande échelle. Sa fonctionnalité de niveau entreprise garantit que les applications critiques fonctionnent de manière fiable et ultra-rapide, tout en fournissant des intégrations pour simplifier la mise en cache et économiser du temps et de l’argent.

| Basic Caching | Advanced Caching | |
|---|---|---|
| Une latence sous la milliseconde | • | • |
| Peut accélérer une grande variété de bases de données en tant que clé : magasin de données de valeur | • | • |
| Déploiement hybride et multicloud | • | |
| Évolution linéaire sans dégradation des performances | • | |
| 99,9999 % haute disponibilité pour un accès permanent aux données | • | |
| Latence de lecture/écriture locale sur site, plusieurs clouds et zones géographiques | • | |
| Rentabilité pour les grands ensembles de données grâce à l’échelonnement du stockage et à l’utilisation multiple | • | |
| Une équipe d’assistance supérieure avec des SLA définis | • | |
| Va au-delà d’une base de données clé-valeur pour prendre en charge les cas d’utilisation et les modèles de données modernes | • |

Votre cache peut-il répondre aux besoins des applications modernes ?
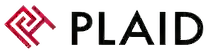


Pour en savoir plus, lisez le Guide définitif de la mise en cache à grande échelle
Les modèles de mise en cache doivent correspondre au scénario d’application. Nous vous proposons plusieurs options,
l’une d’entre elles répondra certainement à vos besoins.
C’est la façon la plus courante d’utiliser Redis en cache. Cache-aside est un excellent choix pour les applications lourdes en lecture lorsque les erreurs de cache sont acceptables. L’application gère toutes les opérations de données lorsque vous utilisez un modèle de mise de côté du cache et communique directement avec le cache et la base de données.
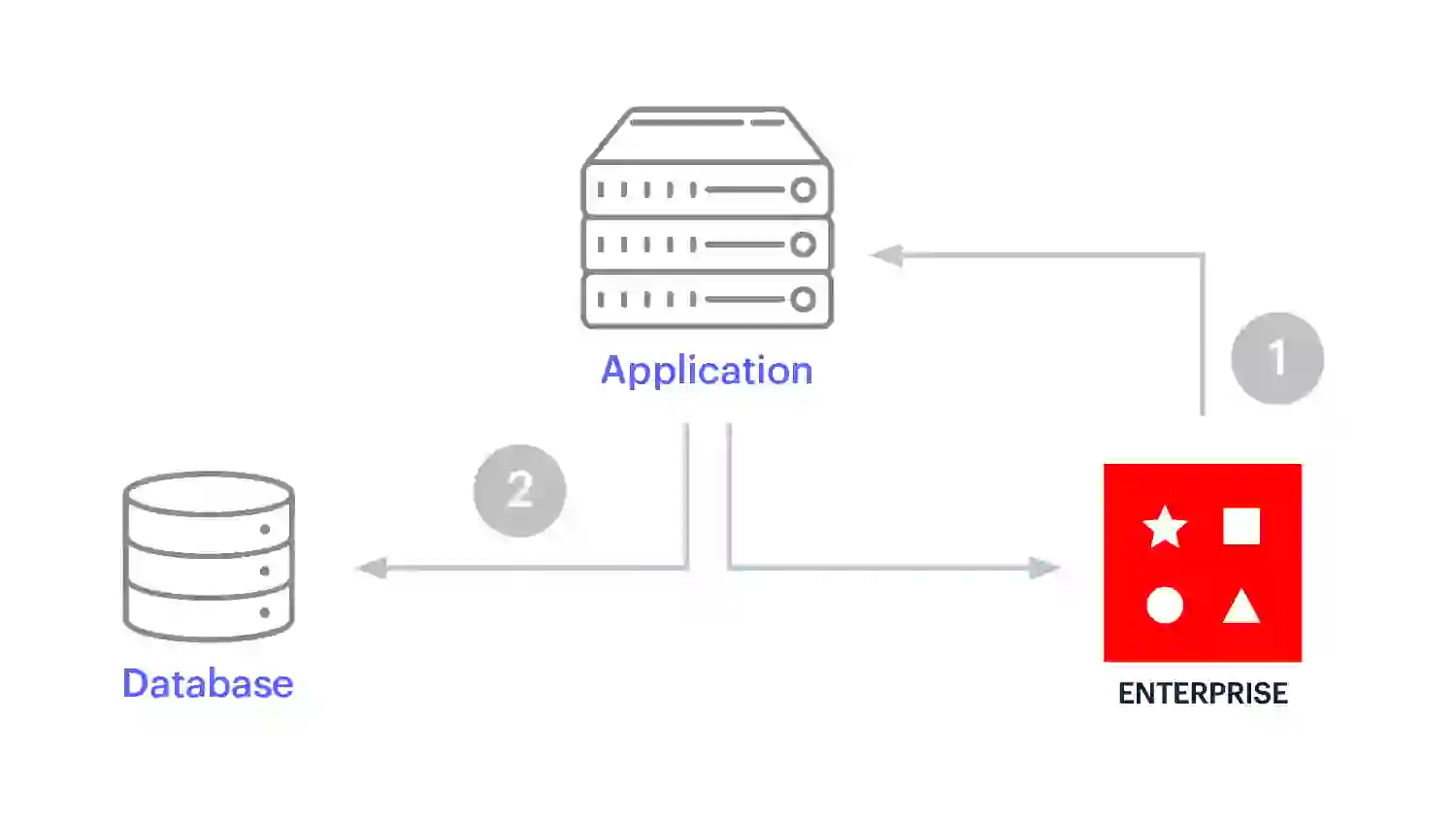
Query caching est une mise en œuvre simple du modèle de mise de côté du cache, où il n’y a pas de transformation des données en une autre structure de données. Ce modèle est un choix populaire lorsque les développeurs visent à accélérer les requêtes SQL simples répétées ou lorsqu’ils doivent migrer vers des microservices sans devoir effectuer de migration leurs systèmes d’enregistrement actuels vers une autre plateforme.
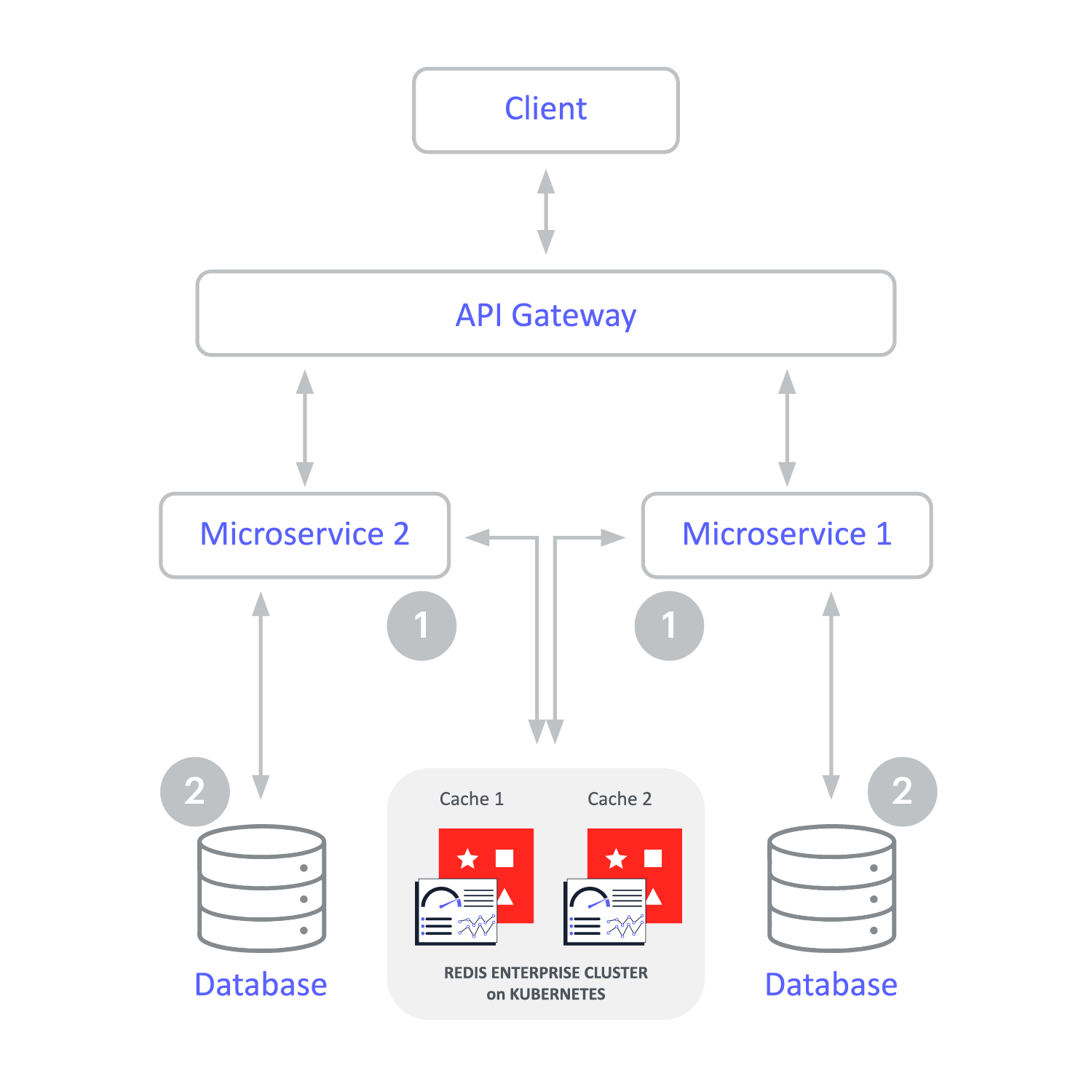
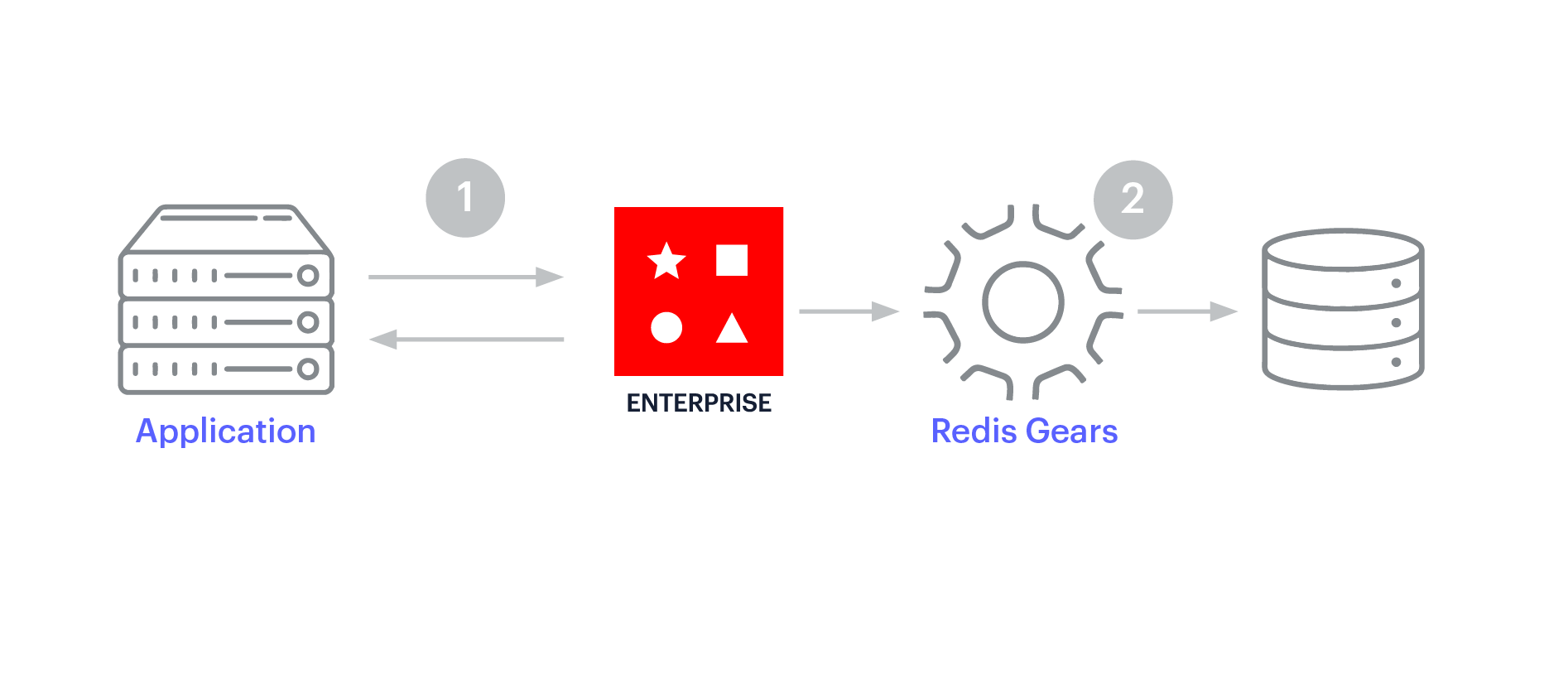
La mise en cache en écriture différée améliore les performances d’écriture. L’application n’écrit qu’à un seul endroit – le cache Redis Enterprise – et Redis Enterprise met à jour de manière asynchrone la base de données backend. Cela simplifie le développement.
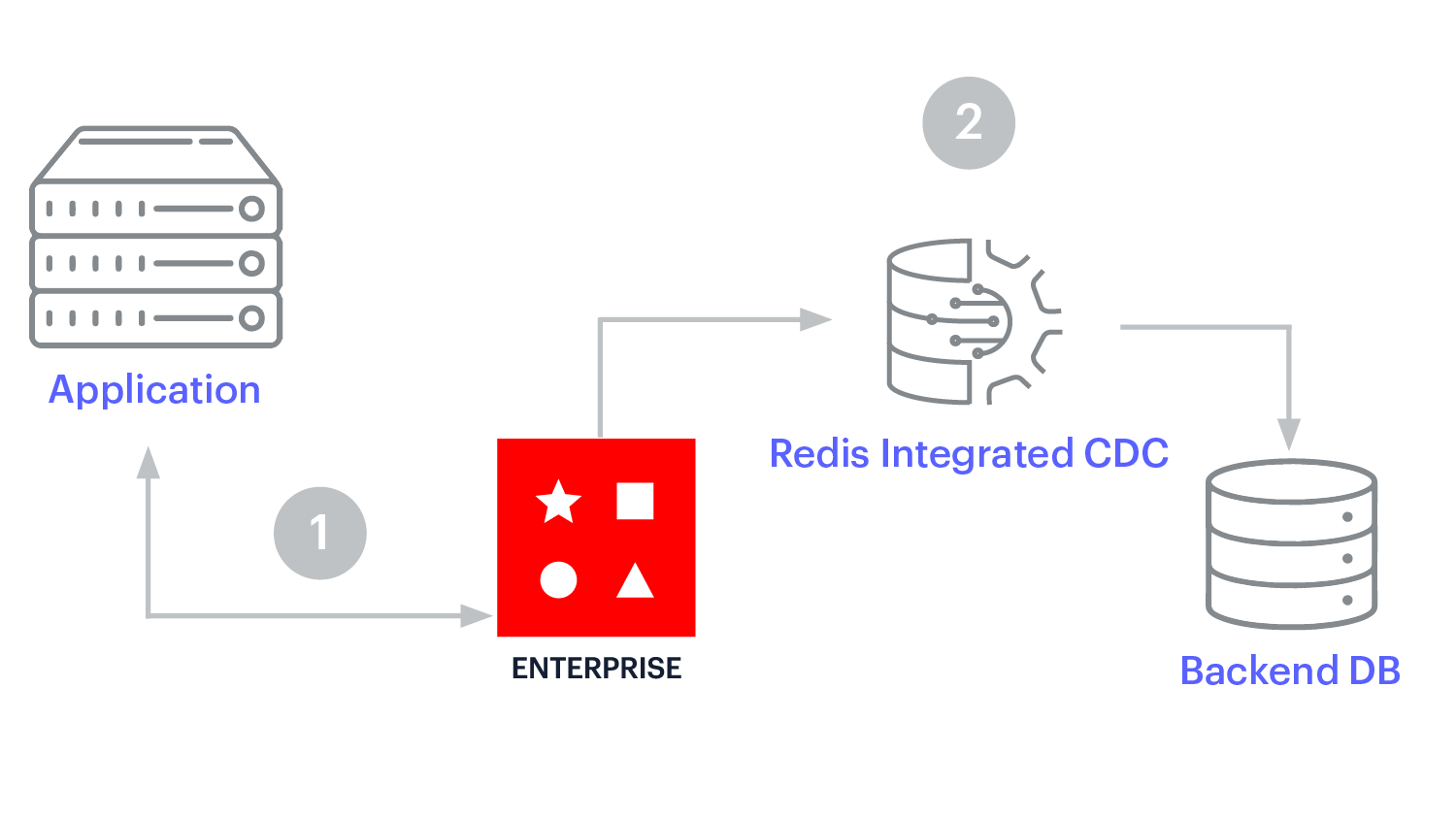
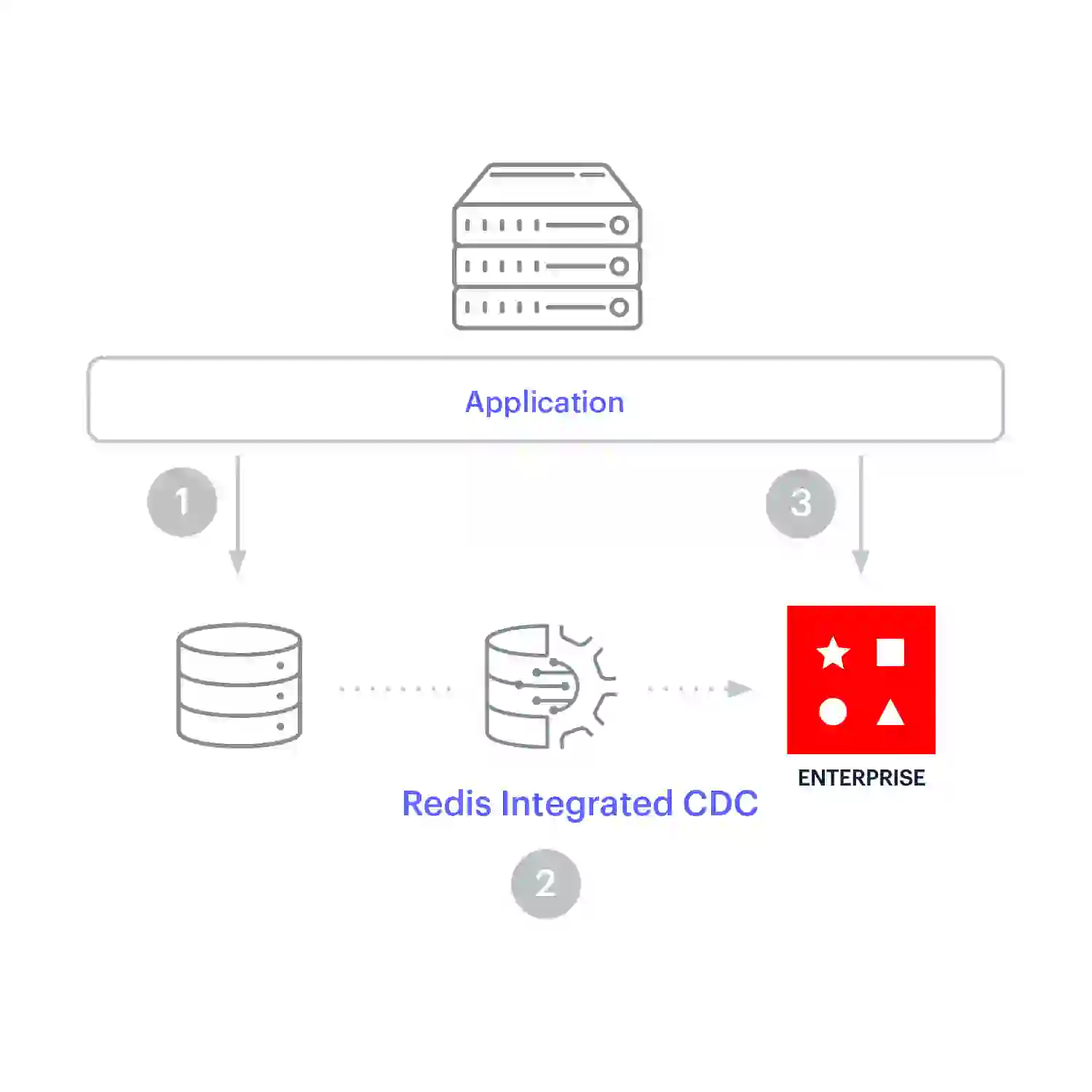
La mise en cache des écriture est similaire au cache d’écriture derrière, car le cache se trouve entre l’application et le magasin de données opérationnelles. Cependant, avec la mise en cache d’écriture, les mises à jour du cache sont synchrones et circulent dans le cache vers la base de données. Le modèle d’écriture favorise la cohérence des données entre le cache et le magasin de données.
Cache prefetching est utilisée pour la réplication continue lorsque les charges de travail optimisées pour l’écriture et la lecture doivent rester synchronisées. Avec ce modèle de mise en cache, l’application écrit directement dans la base de données. Les données sont répliquées dans Redis Enterprise à mesure qu’elles changent dans le système d’enregistrement, de sorte que les données arrivent dans le cache avant que l’application n’ait besoin de les lire.
Maintient des performances inférieures à la milliseconde jusqu’à 200 millions d’opérations par seconde
Soutenu par un SLA de disponibilité de 99,999 %
Le stockage multi-locataires et à plusieurs niveaux réduit les coûts, ce qui permet de réaliser jusqu’à 80 % d’économies
Utilisez en toute transparence une plateforme unique sur site, dans n’importe quel cloud et dans des architectures hybrides
Une équipe d’experts Redis hautement qualifiés est disponible 24 h/24, 7 j/7 pour faire fonctionner, mettre à l’échelle, surveiller et prendre en charge votre cache
Learn more

Learn more

Learn more

Learn more

Learn more

Learn more