



Getting Started with Redis Streams and Java
Learn more


Redis is developed with a great emphasis on performance. We do our best with every release to ensure you’ll experience a very stable and fast product.
Nevertheless, if you’re finding room to improve the efficiency of Redis or are pursuing a performance regression investigation, you will need a concise methodical way of monitoring and analyzing Redis’ performance. This is the story of one of those optimizations.
In the end, we’ve improved stream’s ingest performance by around 20%, an improvement you can already take advantage of on the Redis v7.0.
Before jumping into the optimization, we want to give you a high-level idea of how we got to it.
As stated before, we want to identify Redis performance regressions and/or potential on-CPU performance improvements. To do so, we felt the need to foster a set of cross-company and cross-community standards on all matters related to performance and observability requirements and expectations.
In a nutshell, we constantly run the SPEC’s benchmarks by breaking them down by branch/tag and interpret the resulting performance data that includes profiling tools/probers outputs and client outputs in a “zero-touch” fully automated mode.
The used instruments are all open source and rely on tools/popular frameworks like memtier_benchmark, redis-benchmark, Linux perf_events, bcc/BPF tracing tools, and Brendan Greg’s FlameGraph repo.
If you’re interested in further details on how we use profilers with Redis, we recommend taking a look at our extremely detailed “Performance engineering guide for on-CPU profiling and tracing.”
As soon as this first step was given, we started interpreting the profiling tools/probers’ outputs. One of the benchmarks that presented an interesting pattern was the Streams’ ingested benchmark which simply ingests data into a stream with a command similar to the one below:
`XADD key * field value`.
We’ve observed that when adding to a stream without an ID, it creates duplicate work on SDS creation/freeing/sdslen that costs about 10% of the CPU cycles, as showcased in detail in the next two perf report prints.
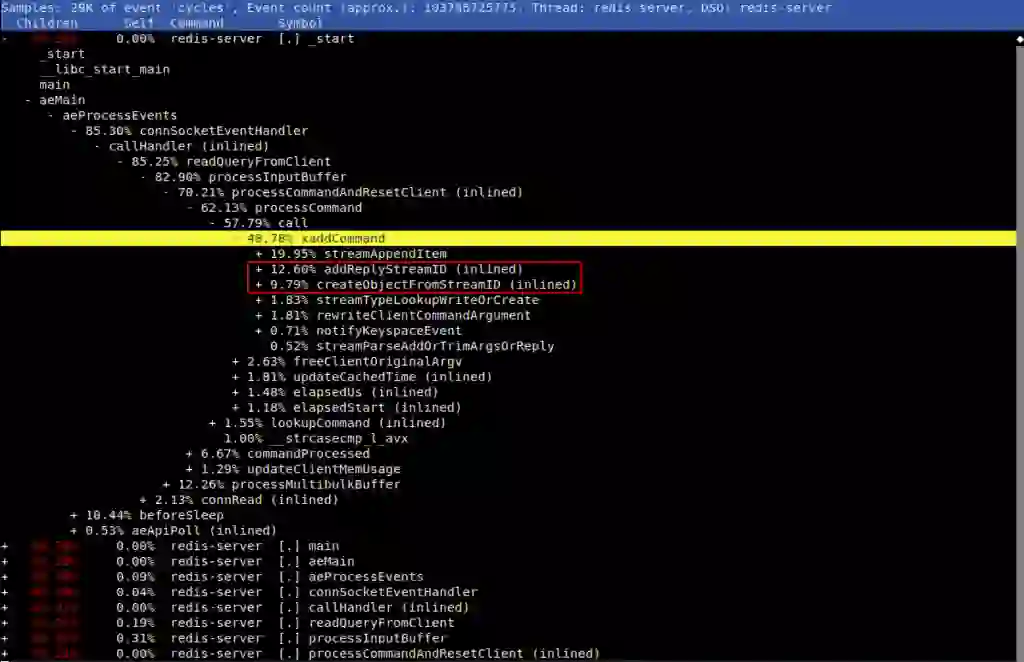
For the same inputs, sdscatfmt and _sdsnewlen were being called twice:

This allowed us to optimize Streams ingestion in around 9-10% as confirmed following benchmark results:
Baseline on unstable branch (6b403f5) :
First commit of this PR (avoid dup work):

The initial focus of this use-case improvement lead to further analysis from Oran (one of the core-team members) that noticed yet another waste of CPU cycles. This time, it was due to non-optimal memory management within the same code block. We were allocating an empty SDS, and then re-allocating it. Reducing the number of calls will give us yet another speed improvement, as shown below.
Second commit (avoid reallocs):

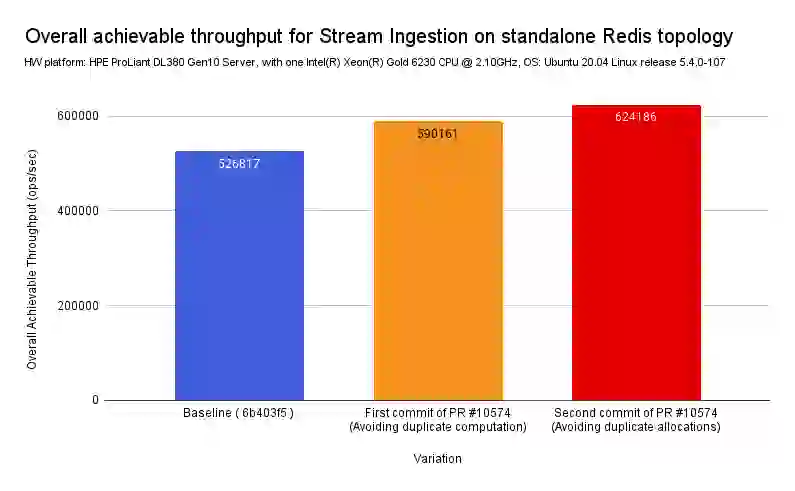
As expected, by simply reusing intermediate computation and consequently reducing the redundant computation and allocations within the internally called functions, we’ve measured a reduction in the overall CPU time of ~= 20% of Redis Streams.
We believe this is an example of how methodical simple improvements can lead to significant bumps in performance, even for already deeply optimized code like Redis.
Our goal is to expand the performance visibility we have of Redis, and members from both industry and academia, including organizations and individuals, are encouraged to contribute. If we don’t measure it, we can’t improve it.

