

Learn how Redis PubSub can be used with Bytewax for effective real-time data processing. This guide provides insights into creating custom input sources and aggregating clickstream data efficiently.
In this guide, we’ll showcase how to write a custom input source for bytewax that reads from a Redis pubsub channel. All code can be found in the bytewax/example-redis repository.
Let’s start by taking a look at the Redis PUBSUB channels. Essentially, it’s a messaging paradigm and while Redis is renowned as a caching system, its capabilities go beyond that (the PUBSUB channels are only one of the many ways you can use Redis cluster in your data infrastructure). The PUBSUB channels feature has been around since version 2.8.0, released in November 2013. A more recent addition is Redis Streams, introduced in Redis 5.0 in 2018. These two differ mainly in delivery guarantees. Streams offer both at-most-once and at-least-once semantics, while PUBSUB supports only at-most-once. I find that PUBSUB is a more prevalent feature, but after this guide, adapting to Streams should be smooth anyway.
Let’s say that we are starting with two Python scripts — a publisher and a listener (perhaps handed down to us by another fellow developer on our team). Both scripts utilize the official redis-py library for basic operations: connecting and exchanging messages.
Let’s say that our messages are some sort of clickstream. For simplicity, we will be reading this from a file, and the messages look like this:
{"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "aperry@yahoo.com", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
{"click_id": "dd5a2b23-3357-4bba-857a-1afdb45f9144", "os": "Android 1.5", "os_name": "Android", "os_timezone": "America/Sao_Paulo", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "hessjuan@gmail.com", "user_domain_id": "e7a09617-3635-44b5-b119-8c1034865a9f"}
{"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "aperry@yahoo.com", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
...
You can inspect the events file in the repository
The publisher script below reads a .jsonl file and publishes its content to a Redis channel:
# redis_publisher.py
import os
import pathlib
import redis # pip install redis
# Configuration
REDIS_HOST = os.getenv('REDIS_HOST', 'localhost')
REDIS_PORT = int(os.getenv('REDIS_PORT', '6379'))
CHANNEL_NAME = os.getenv('REDIS_CHANNEL_NAME', 'device_events')
JSONL_FILE = 'events.jsonl'
# Connect to Redis
r = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)
# Read the .jsonl file and publish it to the Redis channel
with pathlib.Path(JSONL_FILE).open() as file:
for line in file:
r.publish(CHANNEL_NAME, line)
print("👍 events published")
A docker command to run a Redis instance:
docker run -d --rm -p 6379:6379 redis:latest
To publish messages:
python redis_publisher.py
When using JSONL file format, every line of the file is a json object so we don’t need to do any processing on the publishing side and just send the messages “as is”. If we run the container using the provided command, we would use default connection settings so we don’t need to provide any environment variables and just run the publisher script with no arguments (assuming the events.jsonl is in the same directory)
The listener script listens to a channel and logs the incoming messages. It is rather straightforward except for the polling mechanism. Here’s how such a script might look like:
# redis_listener.py
import logging
import os
import redis
# Set up logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# Configuration
REDIS_HOST = os.getenv('REDIS_HOST', 'localhost')
REDIS_PORT = int(os.getenv('REDIS_PORT', '6379'))
CHANNEL_NAME = os.getenv('REDIS_CHANNEL_NAME', 'device_events')
# Connect to Redis
r = redis.Redis(host=REDIS_HOST, port=REDIS_PORT)
# Function to handle the messages from the channel
def message_handler(message):
data = message['data'].decode('utf-8')
logger.info(f'Received data: {data}')
# Subscribe to the channel
pubsub = r.pubsub()
pubsub.subscribe(**{CHANNEL_NAME: message_handler})
# Listen for incoming messages
logger.info(f'Listening to channel: {CHANNEL_NAME}')
pubsub.run_in_thread(sleep_time=0.001)
Running this script and then publishing messages to the channel should output something like this:
INFO:__main__:Listening to channel: device_events
INFO:__main__:Received data: {"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "aperry@yahoo.com", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
INFO:__main__:Received data: {"click_id": "dd5a2b23-3357-4bba-857a-1afdb45f9144", "os": "Android 1.5", "os_name": "Android", "os_timezone": "America/Sao_Paulo", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "hessjuan@gmail.com", "user_domain_id": "e7a09617-3635-44b5-b119-8c1034865a9f"}
...
This approach, though functional, can seem clunky, especially when complexity rises. If you have some experience writing Python, you probably already spotted a few things about this script that might have raised your eyebrow. The message handler is registered using the kwargs argument, with an awkward channel name -> function dict and then we use threads to run the listener. I don’t know about you, but for me working with threads in Python is never fun. Furthermore, I always end up questioning myself every time I see a sleep somewhere in my code with some float value next to it. And it’s all for just a simple echo-like pipeline: if we were to add more steps it might easily become a messy highly cyclomatically complex callback function.
It is worth mentioning that there are different ways to set up pub/sub with redis-py, some are more elegant than others. Depending on your context you can find a more suitable one but you would still need to manage the complexity of your processing. So, for a more structured and scalable pipeline, we’ll turn to bytewax.
Before going forward, let’s recap how our current small echo pipeline looks and agree on some terminology:
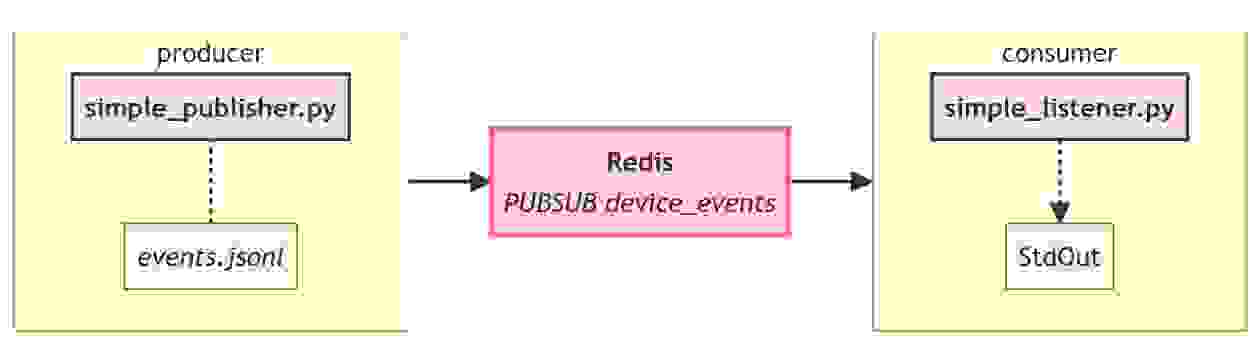
We are going to refer to “everything to the left of Redis” as “producer” and “everything on the right of the Redis” as “consumer”. It’s just a convention, we could’ve picked “writer”/”reader” or “publisher”/”subscriber”. Technically, if you want to nitpick, those terms have some differences, but in the context of this post, they are irrelevant. Using this terminology we should add that:
Now as we go further and use bytewax to rewrite the consumer, everything on the left would stay the same. Bytewax, of course, can be used on the producer side as well but it’s a story for another blog post 🙂
Starting small is always a good idea when experimenting with new tools. So, we’ll begin by replicating our echo pipeline with bytewax. We can always add more computational steps once we verify the basic functionality. Fortunately, since we already have our functioning listener script, the task primarily involves integrating it into bytewax in a correct manner.
A great reference for making your own connector is the built-in KafkaSource. We’ll name ours RedisPubSubSource, and it should be a subclass of FixedPartitionedSource, ensuring that each partition maintains a distinct StatefulSourcePartition object, which we will actually need to write as well. Let’s dive into that.
The core logic for message processing resides in the StatefulSourcePartition and that is where we would place our channel processing code:
class RedisPubSubPartition(StatefulSourcePartition):
def __init__(self, redis_host, redis_port, channel):
r = redis.Redis(host=redis_host, port=redis_port)
self.pubsub = r.pubsub(ignore_subscribe_messages=True)
self.pubsub.subscribe(channel)
def next_batch(self, _sched):
message = self.pubsub.get_message()
if message is None:
return []
data = message['data']
if isinstance(data, bytes):
data = data.decode('utf-8')
return [data]
def snapshot(self):
return None
def close(self):
self.pubsub.close()
Remember, this is not a production-ready code. In a real-world application, you’d likely want more settings in for the connection and would need to address other nuances. But for our purposes, this serves well.
Let’s take a closer look at the next_batch function:
def next_batch(self, _sched):
message = self.pubsub.get_message()
if message is None:
return []
data = message['data']
if isinstance(data, bytes):
data = data.decode('utf-8')
return [data]
Here, it first retrieves a message from the subscribed channel. If there’s no message, it returns an empty list. When a message is received, we decode it. This is not essential to happen inside the next_batch, but it reduces redundancy in the subsequent pipeline. However, as you might have spotted, the deserialization isn’t included here. This is because we aim to be flexible in changing serialization formats that suit the pipeline need without over-complicating the code. Of course, this is not strictly restricted and for sources with a stable schema, it might be practical to include the deserialization step already here. Alternatively, subclassing or passing serialization functions as constructor parameters is also a way to achieve that.
Let’s outline these two guiding principles for creating your own bytewax StatefulSourcePartition:
Additionally, aside from next_batch, we add two helper methods related to snapshot mechanics and resource lifespan. While KafkaSourcePartition employs offsets for snapshots, Redis PubSub channels do not, therefore we use a placeholder function there that just returns None. Closing the connection requires a call to PubSub’s .close() method. Note that we haven’t used any threading, and overall the code so far is a cleaner, more Pythonic approach compared to our original listener’s code.
Next, we’ll outline the Source class, that uses Partition and creates an input (or, one can say, “data entrypoint”) to our dataflow.
The main purpose of the Input is to initialize the PubSub source we wrote earlier and initialize it with necessary connection details from the environment. If there’s a need for sanity checks, incorporating them into the constructor of this Input class would be the most logical choice.
import os
import redis
from bytewax.inputs import FixedPartitionedSource, StatefulSourcePartition
class RedisPubSubPartition(StatefulSourcePartition):
...
class RedisPubSubSource(FixedPartitionedSource):
def __init__(self):
self.redis_host = os.getenv('REDIS_HOST', 'localhost')
self.redis_port = int(os.getenv('REDIS_PORT', '6379'))
self.channel_name = os.getenv('REDIS_CHANNEL_NAME', 'device_events')
def list_parts(self):
return ['single-part']
def build_part(self, now, for_key, resume_state):
return RedisPubSubPartition(
self.redis_host,
self.redis_port,
self.channel_name,
)
Comparing the Input code to our earlier simple listener script, it becomes noticeable that this segment aligns closely with the configuration section of the original script. As for the handling of messages, we are not using the direct callbacks we used before as processing is delegated to the RedisPubSubPartition. Two additional methods, list_parts and build_part are worth talking a bit more about.
Bytewax’s underlying architecture treats partitioned inputs as a set of distinct, separate streams. Ideally, as you build your pipeline, you’d know how many data partitions are present in the input source, and this would be valid for any data processing pipeline. It is common to have more than 1 partition for big data processing, and bytewax is designed to be adaptive to diverse data requirements, so it needs to have an API that offers this level of flexibility. For you as a developer, it basically means you need to implement these two methods, list_parts to fetch a list of partitions, and build_part to build an individual Partition object for each of them.
So, the bytewax’s flexibility comes at the cost of performing this additional ceremony even when you’re dealing with just one partition. This also streamlines several internal considerations, such as snapshot restoration and recovery. The choice to make this ceremony obligatory was deliberate, as it balances the provided API in a way that avoids any “magical automation” that might confuse users (“explicit is better than implicit”). Fortunately, our current scenario uses just a single-channel partition, which makes our implementation relatively uncomplicated.
With all components in place, we can now combine it all and effectively recreate our previous solution
# An echo dataflow would consist of an input and an output to stdout
from bytewax.dataflow import Dataflow
from bytewax.connectors.stdio import StdOutSink
from bytewax import operators as op
# ... (definitions of RedisPubSubPartition, RedisPubSubSource)
flow = Dataflow('redis_echo')
stream = op.input('inp', RedisPubSubSource())
op.output('out', stream, StdOutSink())
The entire code is available in the example repository. Our present implementation looks like this:
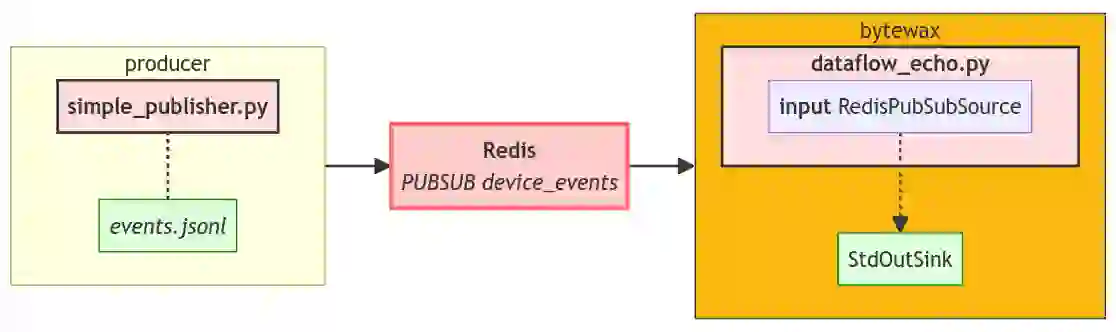
Structurally, this mirrors our previous implementation, with the left-hand side of the pipeline remaining unchanged.
You’d need to run the dataflow as usual, using bytewax.run helper:
python -m bytewax.run ./src/dataflow_echo.py:flow
The output would remain unchanged, which is good because that’s what we’re hoping for:
{"click_id": "811320f1-3bc2-42b9-a841-5a1e5a812f2d", "os": "iPad; CPU iPad OS 4_2_1 like Mac OS X", "os_name": "iOS", "os_timezone": "Europe/Berlin", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "aperry@yahoo.com", "user_domain_id": "1ab06c9f-0e2e-4f46-9b6c-91a0e9a86a4d"}
{"click_id": "dd5a2b23-3357-4bba-857a-1afdb45f9144", "os": "Android 1.5", "os_name": "Android", "os_timezone": "America/Sao_Paulo", "device_type": "Mobile", "device_is_mobile": true, "user_custom_id": "hessjuan@gmail.com", "user_domain_id": "e7a09617-3635-44b5-b119-8c1034865a9f"}
Before going further, let’s quickly dockerize the setup. This ensures we are working in an isolated environment and also makes it easier to rerun the publisher part of our pipeline.
The compose file will contain our pipeline, producer script, and the bytewax dataflow:
version: '3.8'
services:
redis:
image: "redis:7.2.1"
ports:
- "6379:6379"
simple-publisher:
build:
context: .
dockerfile: docker/redis-simple.Dockerfile
command: python /app/redis_publisher.py
depends_on:
- redis
environment:
REDIS_HOST: redis
REDIS_PORT: 6379
REDIS_CHANNEL_NAME: device_events
EVENTS_JSONL_FILE: /data/events.jsonl
volumes:
- ./data:/data
bytewax-echo:
build:
context: .
dockerfile: docker/redis-bytewax.Dockerfile
command: python -m bytewax.run /app/dataflow_echo.py:flow
depends_on:
- redis
environment:
REDIS_HOST: redis
REDIS_PORT: 6379
REDIS_CHANNEL_NAME: device_events
The Dockerfile for bytewax dataflow installs redis and bytewax and copies the necessary files. The publisher script Dockerfile is essentially the same, but sans bytewax.
With this structure in place, we’re 100% ready to start making our dataflow more sophisticated, so let’s do that! For those eager to go directly to the end result, the full source code for this example is available here. Simply clone the repository and execute docker compose up to check out the dataflow we’ll be building in the next section.
With our RedisPubSubSource ready and tested, there’s no longer a need to focus on Redis for any data processing we might be interested in. This offers us the freedom to use any pre-existing dataflow steps with minimal changes or, of course, write our own from scratch stringing together the desired operations. One could even utilize this RedisPubSubSource as a preliminary test setup with a very small infrastructure overhead before transitioning the pipeline to a full-fledged Kafka system.
To showcase some of the bytewax’s capabilities, let’s find out how many mobile users we have across different regions. To accomplish this, we will need to carry out the following procedure:
Each of the above points roughly equates to a distinct step in our dataflow. The complete code for the resulting dataflow:
import json
from datetime import timedelta, datetime, timezone
from bytewax import operators as op
from bytewax.connectors.stdio import StdOutSink
from bytewax.dataflow import Dataflow
from bytewax.operators.window import SystemClockConfig, TumblingWindow
from bytewax.operators import window as window_op
from bytewax_redis_input import RedisPubSubSource
def deserialize(payload):
try:
data = json.loads(payload)
except json.decoder.JSONDecodeError:
return None
return data
def initial_count(data):
if data is None:
return 'Uknown', 0
return data['os_timezone'], int(data['device_is_mobile'])
def add(count1, count2):
return count1 + count2
def jsonify(timezone__mobile_count):
tz, count = timezone__mobile_count
return {'timezone': tz, 'num_mobile_users': count}
clock_config = SystemClockConfig()
window_config = TumblingWindow(
length=timedelta(seconds=5),
align_to=datetime(2023, 1, 1, tzinfo=timezone.utc),
)
## build the dataflow
flow = Dataflow('dataflow_mobile_counts)
inp = op.input('inp', flow, RedisPubSubSource())
des = op.map('deserialize', inp, deserialize)
init_count = op.map('initial_count', des, initial_count)
reduce = window_op.reduce_window('sum', init_count, clock_config, window_config, add)
serialize = op.map('jsonify', reduce, jsonify)
op.output('out', serialize, StdOutSink())
That’s a lot of steps! If we run this dataflow we should see the following output:
{'timezone': 'America/El_Salvador', 'num_mobile_users': 0}
{'timezone': 'Asia/Bangkok', 'num_mobile_users': 0}
{'timezone': 'Europe/Madrid', 'num_mobile_users': 45}
{'timezone': 'America/New_York', 'num_mobile_users': 37}
{'timezone': 'Europe/Berlin', 'num_mobile_users': 29}
{'timezone': 'Africa/Lubumbashi', 'num_mobile_users': 6}
...
The full diagram of our pipeline is a bit more complex now
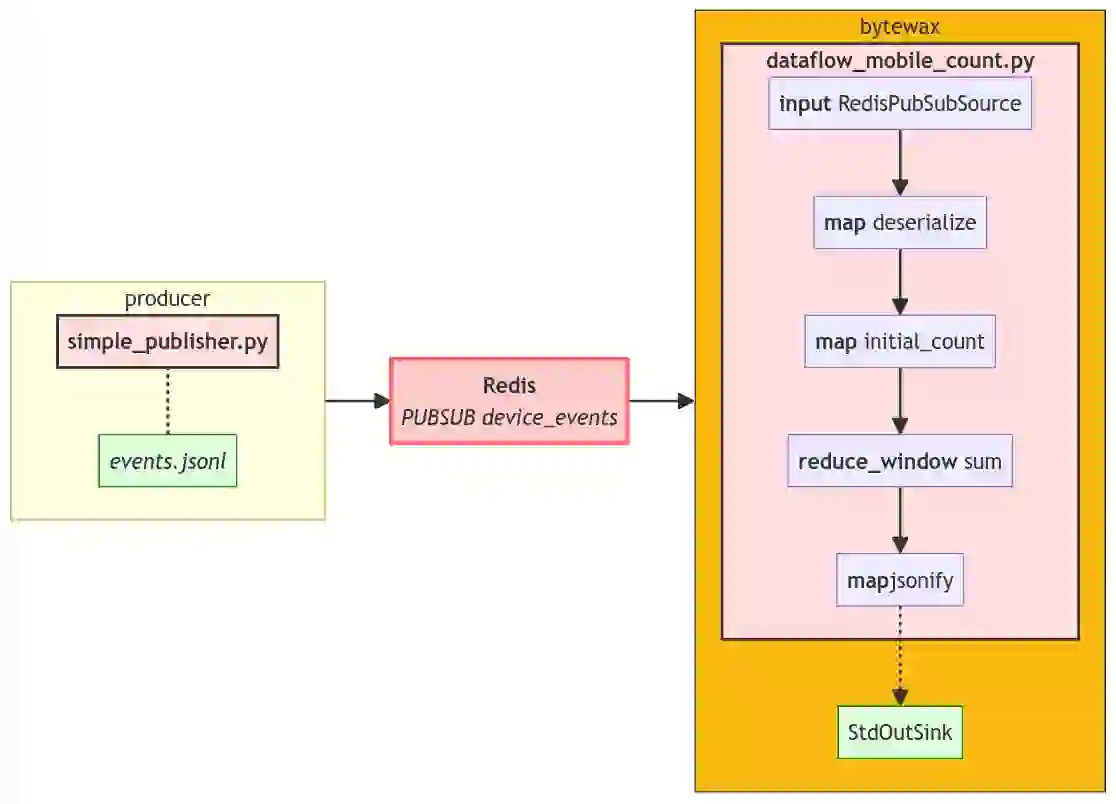
Each step performs its specific function and is isolated enough to be easily tested and debugged. If you’re seeking clarification on how the reduce_window works, I’d kindly direct you to our documentation, as isn’t the primary focus here. So, what is the main focus, you might wonder? Well, I’m glad you asked! The primary focus is on highlighting how pythonic and streamlined the overall pipeline appears now! Each step is straightforward to read and modify; in essence, there are just a few lines of code that efficiently organize the influx of data into a set of counts, ready, for example, for submission to some external BI platform.
But don’t just take our word for it, we encourage you to explore and experiment yourself! You can access the full code in the dedicated repository. Feel free to add add more steps, adjust the pipeline logic, or even consider reworking the RedisPubSubSource class — whatever path you choose, bytewax got you covered.
In this post, we outlined how to write your own bytewax Input using redis PubSub channels as an example. We went from a simple echo example to a windowed calculation. The example is easily extendable for other systems.
A few takeaways:
Hope this post will inspire you to write your own inputs and demystify the process. If you have any comments or suggestions, reach out in the community channel or raise an issue in the bytewax/example-redis repo.


