




Can Your Cache Power Modern Applications? Find Out With Redis’ New Caching Assessment
Learn more


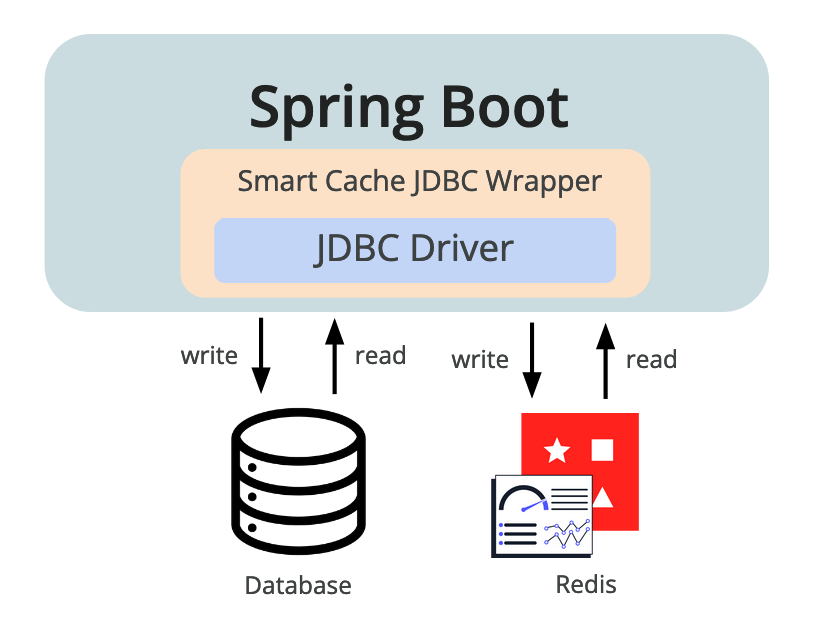
Redis Smart Cache is an open source library that seamlessly adds caching to any JDBC-compliant platform, application, or microservice.
Cache-aside is the most common caching pattern implemented by Redis developers for optimizing application performance. And while cache-aside is conceptually simple, correctly implementing it can be more difficult, outage-prone, and time-consuming than it appears.
In keeping with a primary pillar of the Redis manifesto – we’re against complexity – we developed a new solution called Redis Smart Cache, an open-source library that seamlessly adds caching to any platform, application, or microservice that uses a JDBC-compliant driver for connectivity with its system-of-record.
Redis Smart Cache allows developers to identify their worst-performing queries, dynamically enable query caching, and observe ongoing query performance. All without changing any code. As a result, you can optimize an application’s performance and take advantage of Redis’ speed and reliability simply through configuration.
Redis Smart Cache is useful for optimizing demanding online transaction processing (OLTP) applications, data warehouses, and analytical workloads. For example, you can integrate Smart Cache with Tableau, instantly making live dashboards more responsive.
Since the proof is in the pudding, we recommend going straight to the Redis Smart Cache demo. You’ll have Smart Cache up and running in minutes, and you’ll see first-hand how quickly you can optimize an application with cache-aside at Redis speed.
Typically, adding Redis to an application, for query caching, requires that you change the source code. In the most naive implementation, these modifications take the form of a simple if statement. Consider this pseudo-code implementation of the cache-aside pattern:
if redis_cache.contains(query):
return redis_cache.get(query)
else:
result = backend_database.query(query)
redis_cache.put(query, result)
return result
However, it’s considerably more complex in practice, especially for mission-critical applications and microservices.
First, you will need to discover which queries are slow by examining the database’s query log or consulting your application performance monitoring system. Assuming these queries can be effectively cached, you will then need to associate them with the application code from which they are produced. Once you find each query’s origin, you can implement the cache-aside pattern.
In addition, you’ll also need to design a key schema for the Redis cache and properly configure each cached query’s time-to-live (TTL). Don’t forget to add error handling where needed. It’s also worthwhile to ensure that serializing the result set is reasonably compact and performant. If you’re using a high-level application framework, such as Spring Boot, you might enable caching through a series of configurations and annotations instead.
For business cases with spiky behavior, you will need to account for query performance during seasonal peak usage, changes in user behavior, and maintenance changes to the queries themselves.
Finally, you need to test. Even with caching annotations, you have to ensure that the intended database queries are indeed cached as expected.
Using the Redis manifesto as our guiding principle, we set out to reduce application complexity and provide insights about the queries flowing through SQL-based drivers. We also wanted to empower developers to easily update caching rules as their data access patterns change.
We began with the basic requirements for implementing SQL query-caching within an application, microservice, or third-party platform.

Next, we challenged ourselves to implement these requirements in a way that allows existing applications to add Redis without refactoring their code. In other words, a no-code solution that could be managed solely via dynamic configuration.
Since most of our enterprise customers leverage Java, we began by extending the JDBC API as it acts as the bridge between most JVM-based applications, microservices, and third-party frameworks for SQL-compliant database connectivity. The databases supported include household names such as Oracle, IBM DB2, Microsoft SQL Server, PostgreSQL, and MySQL, as well as Snowflake, BigQuery, Tableau, and other platforms that support JDBC-compliant drivers.
Let’s imagine a real-world application. Suppose you work for an investment brokerage firm that deploys a portfolio management application.
The application has two components:
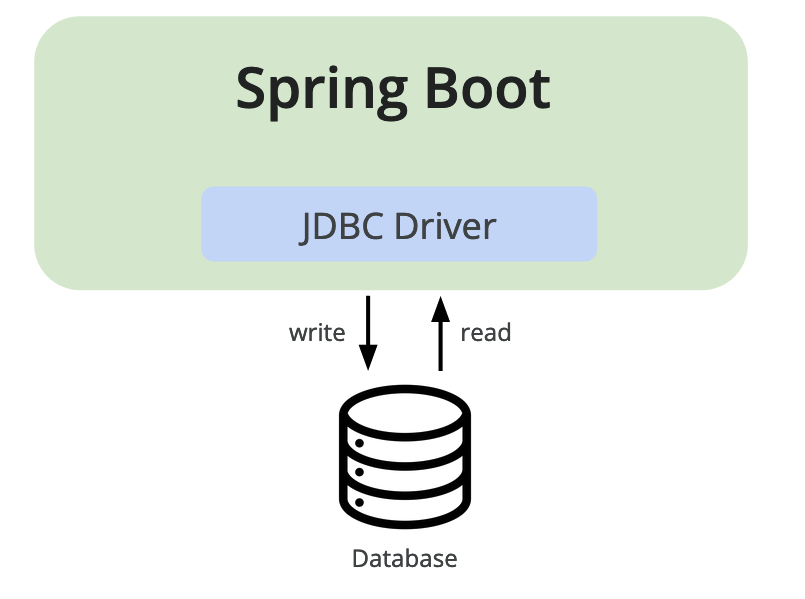
If this application isn’t performing within acceptable service level agreements (SLAs), and data access patterns make caching a feasible solution, the engineering team could write the necessary code to address the problems.
Doing so begins with the developers analyzing the existing code. Research on how to use Redis for query-caching and performing the actual programming. The QA team would run their load tests, and finally, the application is ready for production.
Depending on the amount of technical debt in your application, the effort to cache-aside a few queries might not be so bad. However, if the previous developer didn’t maintain an abstracted layer for each query’s prepared statements or this was just one of many microservices, then it could be a tougher project than it originally seemed before analysis.
The accumulated refactoring costs and the longer than expected project timeline are typically where we see these initiatives fall apart. Until the user experience becomes unbearable that is.
Here’s the alternative. With Redis Smart Cache you can deliver the same outcome with a few simple steps:
(For a production deployment, we recommend consulting the Redis Smart Cache installation guide for more details and configuration options.)
That’s it. With Redis Smart Cache, there is no need for code analysis, no need to learn much about Redis (although we do recommend it as a rewarding activity), and you can avoid technical debt which improves your time-to-market. You don’t even have to learn the best ways to handle failover and thundering herds. It’s all baked into the cake. Simplicity!
The Redis Smart Cache CLI is a command-line interface (CLI) for managing Redis Smart Cache. While you can configure Smart Cache entirely using JDBC properties, the CLI lets you construct query rules interactively and apply new configurations dynamically.
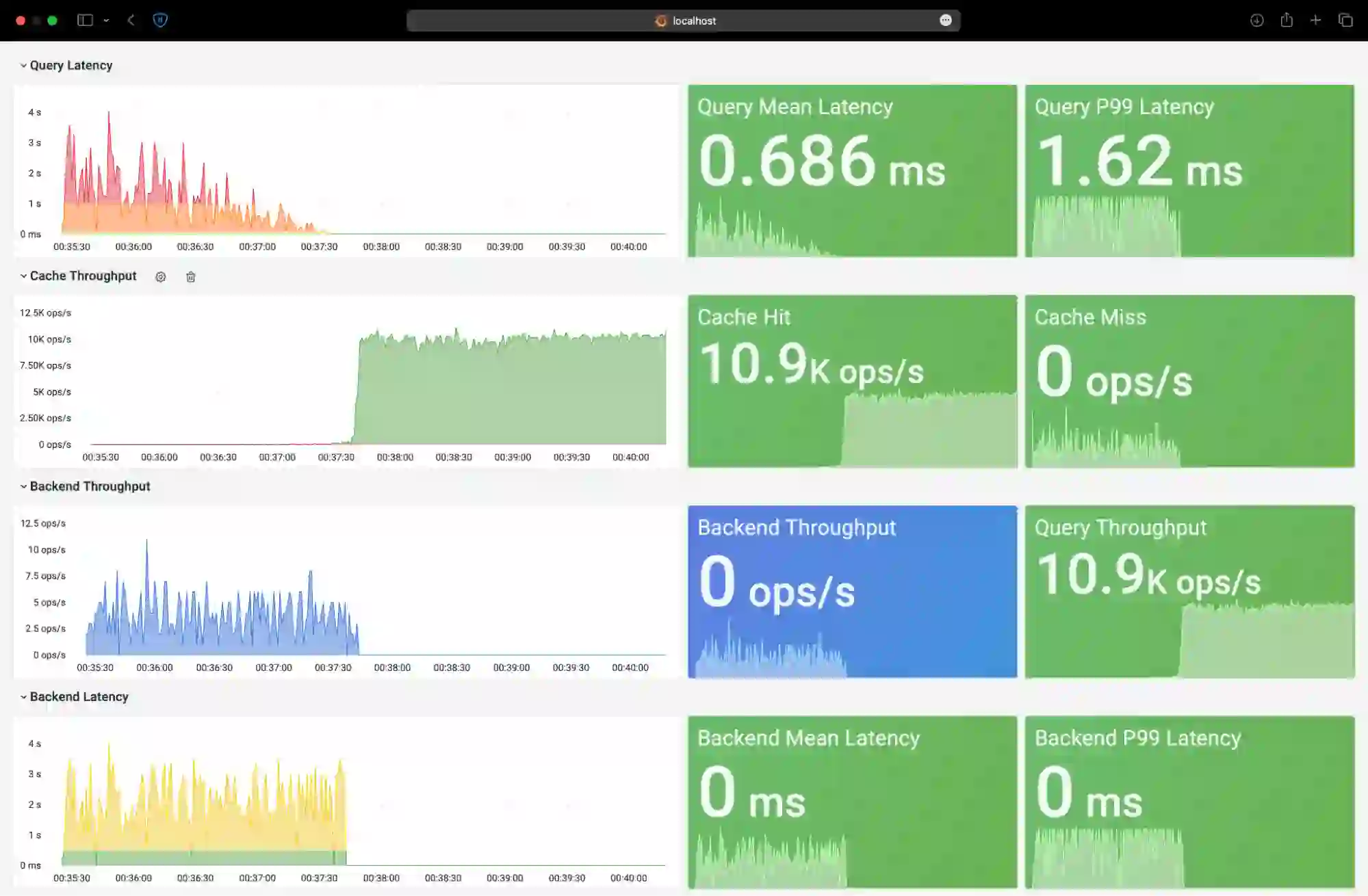
With the CLI, you can also view your application’s parameterized queries, or prepared statements, and the duration of each query. Redis Smart Cache captures access frequency, mean query time, query metadata, and additional metrics. These metrics are exposed via pre-built grafana dashboards; the included visualizations help you decide which query caching rules to apply.
Once you identify the ideal queries to be cached, you can use the CLI to stage and then commit a new caching configuration.
For example, suppose you want to cache all queries initiated against the TRANSACTION_HISTORY table for up to five minutes. First, you would select create query caching rule from the CLI, then create a match-any table rule, supply the table name (TRANSACTION_HISTORY), and add a TTL of 5m.
This new rule change is marked as pending until you commit it. Once committed, every application instance using the Smart Cache library consumes the new configuration and starts caching queries that match this rule.
When you first install Smart Cache, you won’t see any changes to your application’s behavior. This is by design. Smart Cache starts capturing the system of record’s query performance metrics but doesn’t cache any queries until you explicitly decide which queries to cache.
This is because Smart Cache effectively operates as a rules engine. The configuration that you create is a collection of caching rules. You can build per-query rules that match an application’s exact parameterized queries or create more general rules.
As illustrated in the example above, Smart Cache can even match all queries that contain a particular table or set of tables. If the query-matching and table-matching rules still aren’t granular enough, you can also create your own regular expressions for query matching.
To get started with Redis Smart Cache, follow the installation guide. The Redis Smart Cache core library is open source and can be used with any Redis deployment.
To use the CLI, analytics, or dynamic configuration features, you need a Redis database that includes the capabilities of Redis Stack. In particular, Smart Cache CLI requires search and time series. If you’re unable to deploy Redis Stack on your own or in production, we recommend Redis Cloud and Redis Enterprise.
Don’t hesitate to file an issue to suggest improvements, and feel free to contact us for assistance. We’re eager to help and are just getting started! Already on the docket are a number of exciting capabilities, including enhanced Grafana dashboards for monitoring Smart Cache’s performance, prescriptive TTLs, and a cache invalidation protocol to minimize the time window for stale data.
To learn more about Query Caching with Redis Enterprise, see our caching solutions overview.
Huge thanks to our dedicated field engineers Julien Ruaux for building the core Redis Smart Cache JDBC driver and Steve Lorello for creating the Smart Cache CLI.

