



Data 101: The Fundamentals of Data Science
Learn more


Data architectures can be classified based on their operational mode or topology, including data fabric, data hub, and data mesh. What’s the distinction between those? Buckle in.
Previously, when I explained velocity-based data architectures, I went into detail about Lambda and Kappa architectures. But that’s just the beginning of the story.
While data architectures can be grouped in relation to data velocity, as we’ve seen with Lambda and Kappa, another way to classify them is technology-agnostic operational models. As you surely remember if you have been following along with this Data Basics series, three types of operating models can exist in any organization: centralized, decentralized, and hybrid.
Here, I describe three topology-based data architectures in more detail: data fabric, data mesh, and data hub.
A data hub is an architecture for managing data in a centralized way. Think of it as a data exchange with frictionless data flow at its core.
A data hub acts as a central repository of information with connections to other systems and customers, allowing data sharing between them. Endpoints interact with the data hub by providing data into it or receiving data from it. The hub provides a mediation and management point, making visible how data flows across the enterprise.
A data hub architecture facilitates this exchange by connecting producers and consumers of data. The seminal work was a Gartner research paper, Implementing the Data Hub: Architecture and Technology Choices, published in 2017. Gartner suggested a technology-neutral architecture for connecting data producers and consumers, which was more advantageous than point-to-point alternatives. Subsequent research further developed this concept, resulting in the current definition of a data hub’s attributes.

The hub is structured and consumed according to the models defined by its users. Governance policies are established by data managers to ensure data privacy, access control, security, retention, and secure information disposal. Developers can use integration strategies such as APIs or Extract-Transform-Load (ETL) processes to work with the data stored within the hub. The persistence attribute defines which type of datastore should be used for storing this data (such as data lakes, data warehouses, or data lakehouses) and the different parameters of storage, such as the raw support, storage system, and storage layers.
Implementing a data hub architecture facilitates:
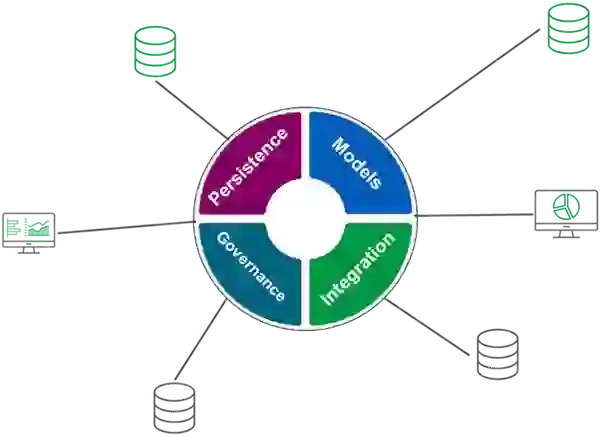
Gartner proposed that businesses could use specialized, purpose-built data hubs. For instance, analytics data hubs might collect and share information for downstream analytics processes. Or application data hubs could be used as domain context for specific applications or suites.
Data centralization implemented in data hubs ensures that data is managed from a central source–with a unified vision–and it keeps the data accessible from many different points. The beneift is that it minimizes data silos, fosters collaboration, and provides visibility into emerging trends and impacts across the enterprise.
However, there are challenges with data centralization. Processes can be slow without putting accelerators or some sort of self-service strategy in place. As a result, requests take longer and longer to get done. The business can’t move forward fast enough, and opportunities for better customer experiences and improved revenue are lost simply because they can’t be achieved quickly.
That’s among the reasons Gartner recently updated its data hub concept to allow organizations to run multiple hubs in an interconnected way. This way, the data hub can take advantage of data centralization and leverage decentralization by giving the lines of business more responsibility and power.
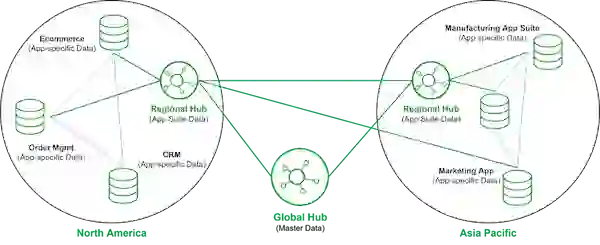
The most common data hub usage is data warehouses. A data warehouse is a central data hub used for reporting and analysis. Typically, data in a data warehouse is highly formatted and structured for analytics use cases. As a result, it’s among the oldest and most well-established data architectures.
In 1989, Bill Inmon originated the notion of the data warehouse, which he described as “a subject-oriented, integrated, nonvolatile, and time-variant collection of data in support of management’s decisions.” Though the technical aspects of the data warehouse have evolved significantly, the original definition still holds its weight.
Traditionally, a data warehouse pulls data from application systems by using ETL. The extraction phase pulls data from source systems. The transformation phase cleans and standardizes the data, organizing and imposing business logic in a highly modeled form.
One ETL variation is Extract-Load-Transform (ELT). With the ELT mode in data warehouse architectures, data is moved more or less directly from production systems into a staging area in the data warehouse. In this context, staging indicates that the data is in a raw form. Rather than using an external system, transformations are handled directly in the data warehouse. Data is processed in batches, and transformed output is written into tables and views for analytics.

When the Big Data era began, the data lake emerged as another centralized architecture. The idea was (and is) to create a central repository where all types of structured and unstructured data are stored without any strict structural constraints. The data lake was intended to empower businesses by providing unlimited data supply.
The initial version of the data lake started with distributed systems like Hadoop (HDFS). As the cloud grew in popularity, these data lakes moved to cloud-based object storage, which could depend on extremely cheap storage costs and virtually limitless storage capacity. Instead of relying on a monolithic data warehouse where storage and compute are tightly coupled, the data lake stores an immense amount of data of any size and type.
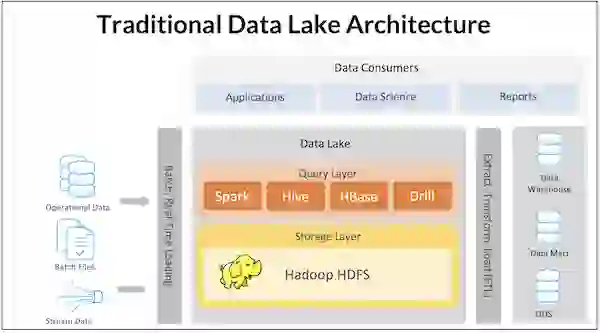
It got a lot of hype. But the first generation of data lakes–data lake 1.0–had significant drawbacks. The data lakes essentially turned into a dumping ground, creating terms such as “data swamp” and “dark data,” as many data projects failed to live up to their initial promise. Management became increasingly difficult as the data volume grew exponentially, and schema management, data cataloging, and discovery tools were lacking. In addition, the original data lake concept was essentially write-only, creating huge headaches with the arrival of regulations such as GDPR that required targeted deletion of user records. Processing data was also a major challenge, with relatively basic data transformations, such as joins, requiring the implementation of complex MapReduce jobs.
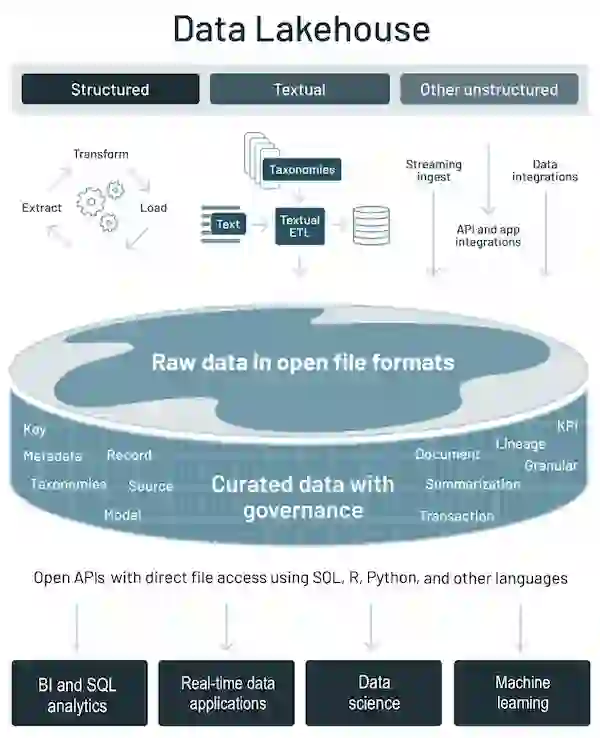
Various industry players have sought to enhance the data lake concept to fully realize its promise and to respond to the first-generation data lake limitations. For example, Databricks introduced the notion of a data lakehouse, which suggests a convergence between data lakes and data warehouses. The lakehouse incorporates the controls, data management, and data structures found in a data warehouse while still housing data in object storage and supporting a variety of query and transformation engines. In particular, the data lakehouse supports atomicity, consistency, isolation, and durability (ACID) transactions. It is a significant disruption from the original data lake, where you simply pour in data and never update or delete it.
Data decentralization is a data management approach that eliminates the need for a central repository by distributing data storage, cleaning, optimization, output, and consumption across organizational departments. This helps reduce complexity when dealing with large amounts of data and issues such as changing schema, downtime, upgrades, and backward compatibility.
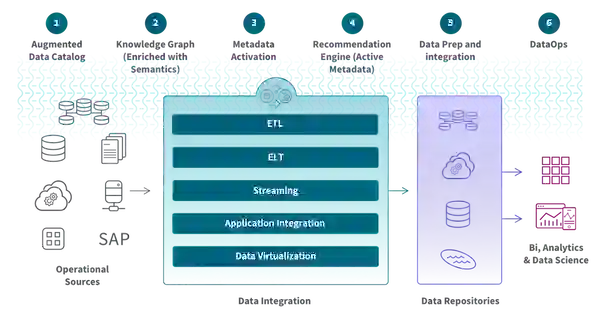
Data fabric was created first as a distributed data environment that enables the ingestion, transformation, management, storage, and access of data from various repositories for use cases such as business intelligence (BI) tools and operational applications. It provides an interconnected web-like layer to integrate data-related processes by leveraging continuous analytics over current and inferred metadata assets. To maximize efficiency, it uses techniques like active metadata management, semantic knowledge graphs, and embedded machine learning/AutoML capabilities.
This concept was coined in 2016 by Noel Yuhanna of Forrester Research in Forrester Wave: Big Data Fabric, and has been updated since then. Yuhanna’s paper described a technology-oriented approach combining disparate data sources into one unified platform using Hadoop and Apache Spark for processing. The goal is to increase agility by creating an automated semantic layer. This later accelerates the delivery of data value while minimizing pipelines complexity.
Over the years, Yuhanna developed his Big Data Fabric concept further. His current vision for data fabrics is for them solve a certain class of business needs, such as creating an all-encompassing view of customers, customer intelligence, and analytics related to the Internet of Things. The data fabric’s components include AI/ML, data catalog, data transformation, data preparation, data modeling, and data discovery. It also provides governance and modeling capabilities.
Gartner also adopted the term “data fabric” and defined it similarly. The analyst firm describes it as “an emerging data management and integration design that enables flexible, reusable, and enhanced data integration pipelines, services, and semantics to support various operational or analytics use cases across multiple deployment platforms”.
Data fabrics combine different data integration techniques while using active metadata, knowledge graphs, semantics, and machine learning (ML) to improve their design process. They organize them into five inner attributes.

In a fabric, active metadata contains catalogs of passive data elements such as schemas, field types, data values, and knowledge graph relationships. The knowledge graph stores and visualizes the complex relationships between multiple data entities. It maintains data ontologies to help non-technical users interpret data.
With the help of AI and ML features, a data fabric may assist and enhance data management activities. It also offers integration capabilities to dynamically ingest disparate data into the fabric to be stored, analyzed, and accessed. Automated data orchestration allows users to apply DataOps principles throughout the process for agile, reliable, and repeatable data pipelines.
Data fabric is a technology-agnostic architecture. Its implementation enables you to scale Big Data operations for both batch processes and real-time streaming, providing consistent capabilities across cloud, hybrid multi-cloud, on-premises, and edge devices. It simplifies the flow of information between different environments so that a complete set of up-to-date data is available for analytics applications or business processes. And it reduces time and cost by offering pre-configured components and connectors, so nobody has to manually code each connection.
Data mesh was introduced in 2019 by Zhamak Dehghani, who argued that a decentralized architecture was necessary due to shortcomings in centralized data warehouses and data lakes.
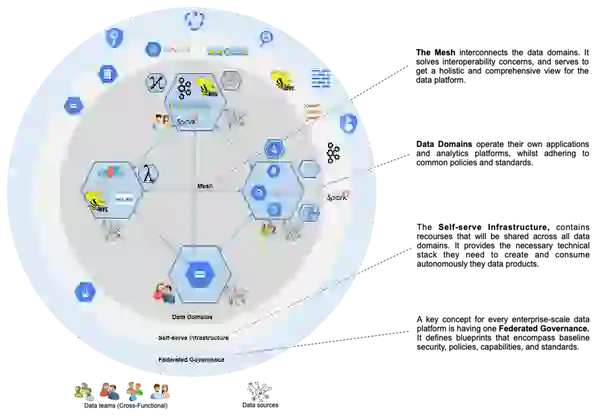
A data mesh is a framework that enables business domains to own and operate their domain-specific data without the need for a centralized intermediary. It draws from distributed computing principles, where software components are shared among multiple computers running together as a system. In this way, data ownership is spread across business domains, each of which is responsible for creating its own products. A data mesh–in theory, anyway–allows easier contextualization of the collected information to generate deeper insights while simultaneously facilitating collaboration between domain owners to create tailored solutions according to specific needs.
Dehghani later revised her position to propose four principles that form this new paradigm: domain-oriented, data-as-product, self-service, and federated governance.
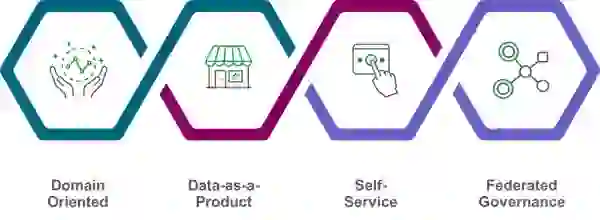
The data mesh concept is based on decentralizing and distributing responsibility for analytical data, its metadata, and the computation necessary to serve it to people closest to the data. This allows for continuous change and scalability in an organization’s data ecosystem.
To do this, data meshes decompose components along organizational units or business domains that localize changes or evolution within that bounded context. By doing so, ownership of these components can be distributed across stakeholders close to the data.
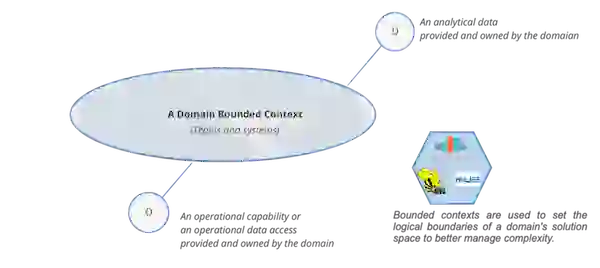
One issue with existing analytical data architectures is that it can be difficult and expensive to discover, understand, trust, and use quality data. The problem only gets worse as more teams provide data (domains) in a decentralized manner, which would violate the first principle.
To address these challenges related to data quality and silos, a data mesh must treat analytical data provided by domains as a product and treat the consumers of that product as customers. The product becomes the new unit of architecture that should be built, deployed, and maintained as a single quantum. It ensures that data consumers can easily discover, understand, and securely use high-quality data across many domains.
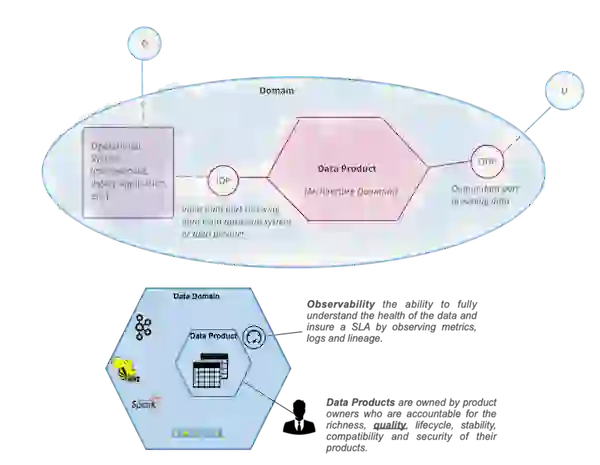
The infrastructure platform allows domain teams to autonomously create and consume data products without worrying about the underlying complexity of the building, executing, and maintaining secure and interoperable solutions. A self-service infrastructure should provide a streamlined experience that enables data domain owners to focus on core objectives instead of worrying about technical details.
The self-serve platform capabilities fall into multiple categories or planes:
Data mesh implementation requires a governance model that supports decentralization and domain self-sovereignty, interoperability through a dynamic topology, and automated execution of decisions by the platform. Integrating global governance and interoperability standards into the mesh ecosystem allows data consumers to gain value from combining and comparing different data products within the same system.
The data mesh combines these principles into a unified, decentralized, and distributed system. The premise is that data product owners have a self-service, shared infrastructure that supports data-sharing pipelines that work in an open yet governed manner. This allows the developers to be productive without sacrificing governance or control over their domain’s data assets.
A data mesh differs from traditional approaches, where pipelines and data are managed as separate entities with shared storage infrastructure. Instead, it views all components (i.e., pipelines, data, and storage infrastructure) at the granularity of a bounded context within a given domain to create an integrated product. This allows for greater flexibility in terms of scalability and customization while providing better visibility into how different parts interact.
How do we put all that together? Data types are increasing in number, usage patterns have grown significantly, and a renewed emphasis has been placed on building pipelines with Lambda and Kappa architectures in the form of data hubs or fabrics. Whether grouped by velocity or the kind of topology they provide, data architectures are not orthogonal. The data architectures and paradigms I described in these blog posts, so far, can be used as appropriate for a given need. And, of course, they can be mixed in architectures like data mesh, in which each data product is a standalone artifact. We can imagine scenarios where a Lambda architecture is implemented in some data products and Kappa architectures are employed in others.
Want more detail? Our white paper, Best Practices for a Modern Data Layer in Financial Services, discusses the steps to modernize a rigid and slow IT legacy system.

