Redis is a bedrock technology and, as such, we occasionally see people considering alternative architectures. A few years ago, this was brought up by KeyDB, and recently a new project, Dragonfly, claimed to be the fastest Redis-compatible in-memory datastore. We believe these projects bring many interesting technologies and ideas worth discussing and debating. Here at Redis, we like this kind of challenge, as it requires us to reaffirm the architectural principles that Redis was initially designed with (hat tip to Salvatore Sanfilippo aka antirez).
While we are always looking for opportunities to innovate and advance the performance and capabilities of Redis, we want to share our perspective and some reflection on why the architecture of Redis remains the best in class for an in-memory, real-time datastore (cache, database, and everything in between).
So in the next sections, we highlight our perspectives on speed and architectural differences as it relates to the comparisons being made. At the end of this post, we have also provided the details of the benchmarks and performance comparisons vs. the Dragonfly project, that we discuss below and invite you to review and reproduce these for yourself.
Speed
The Dragonfly benchmark compares a standalone single process Redis instance (that can only utilize a single core) with a multithreaded Dragonfly instance (that can utilize all available cores on a VM/server). Unfortunately, this comparison does not represent how Redis is run in the real world. As technology builders, we strive to understand exactly how our technologies compare to others, so we did what we believe is a fair comparison and compared a 40-shard Redis 7.0 Cluster (that can utilize most of the instance cores) with Dragonfly, using a set of performance tests on the largest instance type used by the Dragonfly team in their benchmarks, AWS c6gn.16xlarge. In our trials, we saw Redis achieve 18% – 40% greater throughput than Dragonfly, even when utilizing only 40 out of the 64 vCores.
Architectural differences
Some background
We believe a lot of the architectural decisions made by the creators of these multithreaded projects were influenced by the pain points they experienced in their previous work. We agree that running a single Redis process on a multi-core machine, sometimes with dozens of cores and hundreds of GBs of memory, is not going to take advantage of the resources that are clearly available. But this is not how Redis was designed to be used; this is just how many of the Redis providers have chosen to run their services.
Redis scales horizontally by running multi-processes (using Redis Cluster) even in the context of a single cloud instance. At Redis (the company) we further developed this concept and built Redis Enterprise that provides a management layer that allows our users to run Redis at scale, with high availability, instant failover, data persistence, and backup enabled by default.
We decided to share some of the principles we use behind the scenes to help people understand what we believe are good engineering practices for running Redis in production environments.
Architectural principles
Run multiple Redis instances per VM
Running multiple Redis instances per VM lets us:
- Scale linearly, both vertically and horizontally, using a completely shared-nothing architecture. This will always provide more flexibility compared to a multithreaded architecture that only scales vertically.
- Increase the speed of replication, as replication is done in parallel across multiple processes.
- Fast recovery from the failure of a VM, due to the fact that the new VM’s Redis instances will be populated with data from multiple external Redis instances simultaneously.
Limit each Redis process to a reasonable size
We don’t allow a single Redis process to grow beyond 25 GB in size (and 50 GB when running Redis on Flash). This allows us:
- To enjoy the benefits of copy-on-write without paying the penalty of large memory overhead when forking Redis for replication, snapshotting, and Append Only File (AOF) rewrite. And ‘yes’ if you don’t do it, you (or your users) will pay a high price, as shown here.
- To easily manage our clusters, migrate shards, reshard, scale, and rebalance in a fast manner, as every instance of Redis is kept small.
Scaling horizontally is paramount
The flexibility to run your in-memory datastore with horizontal scaling is extremely important. Here are just a few reasons why:
- Better resiliency – the more nodes you use in your cluster, the more robust your cluster is. For example, if you run your dataset on a 3-node cluster and one node is degraded, it’s 1/3 of your cluster that is not performing; but if you run your dataset on a 9-nodes cluster and one node is degraded, it’s just 1/9 of your cluster not performing.
- Easier to scale – it’s much easier to add an additional node to your cluster and migrate just a portion of your dataset to it, rather than scaling vertically, where you need to bring a larger node and copy over your entire dataset (and think about all the bad things that may happen in the middle of this potentially long process…)
- Gradually scaling is much more cost-effective – scaling vertically, especially in the cloud, is expensive. In many cases, you need to double your instance size even if you just need to add a few GB to your dataset.
- High throughput – at Redis, we see many customers who are running high throughput workloads on small datasets, with very high network bandwidth and/or high packet per second (PPS) demand. Think about a 1GB dataset with 1M+ ops/sec use case. Does it make sense to run it on a single-node c6gn.16xlarge cluster (128GB with 64 CPUs and 100gbps at $2.7684/hr) instead of 3-node c6gn.xlarge cluster (8GB. 4 CPU up to 25Gbps at $0.1786/hr each) at less than 20% of the costs and in a much more robust manner? Being able to increase throughput while maintaining cost-effectiveness and improving resiliency seems like an easy answer to the question.
- Realities of NUMA – scaling vertically also means running a two-socket server with multiple cores and large DRAM; this NUMA based-architecture is great for a multi-processing architecture like Redis as it behaves more like a network of smaller nodes. But NUMA is more challenging for a multithreaded architecture, and from our experience with other multithreaded projects, NUMA can reduce the performance of an in-memory datastore by as much as 80%.
- Storage throughput limits – external disks like AWS EBS, don’t scale as fast as memory and CPU. In fact, there are storage throughput limits imposed by cloud service providers based on the machine class being used. Therefore, the only way to effectively scale a cluster to avoid the issues already described and meet high data-persistence requirements is by using horizontal scaling, i.e., by adding more nodes and more network-attached disks.
- Ephemeral disks – an ephemeral disk is an excellent way to run Redis on SSD (where SSD is used as a DRAM replacement, but not as persistent storage) and enjoy the costs of a disk-based database while maintaining the Redis speed (see how we do it with Redis on Flash). Again, when the ephemeral disk reaches its limit, the best way, and in many cases, the only way to scale your cluster is by adding more nodes and more ephemeral disks.
- Commodity hardware – lastly, we have many on-premises customers who are running in a local data-center, private cloud, and even in small edge data-centers; in these environments, it can be hard to find machines with more than 64 GB of memory and 8 CPUs, and again the only way to scale is horizontal.
Summary
We appreciate fresh, interesting ideas and technologies from our community as offered by the new wave of multithreaded projects. It’s even possible that some of these concepts may make their way into Redis in the future (like io_uring which we have already started looking into, more modern dictionaries, more tactical use of threads, etc.). But for the foreseeable future, we will not abandon the basic principle of a shared-nothing, multi-process architecture that Redis provides. This design provides the best performance, scaling, and resiliency while also supporting the variety of deployment architectures required by an in-memory, real-time data platform.
Appendix Redis 7.0 vs. Dragonfly benchmark details
Benchmark summary
Versions:
Goals:
- Verify that the Dragonfly results are reproducible and determine the full conditions in which they were retrieved (given there were some configs missing on memtier_benchmark, OS version, etc… ) see more here
- Determine the best achievable OSS Redis 7.0.0 Cluster performance over AWS c6gn.16xlarge instance, matching the benchmark of Dragonfly
Client configurations:
- The OSS Redis 7.0 solution required a larger number of open connections to the Redis Cluster, given each memtier_benchmark thread is connected to all shards
- The OSS Redis 7.0 solution provided the best results with two memtier_benchmark processes running the benchmark but on the same client VM to match the Dragonfly benchmark)
Resource utilization and optimal configuration:
- The OSS Redis Cluster achieved the best result with 40 primary shards, meaning there are 24 spare vCPUs on the VM. Although the machine was not fully utilized, we found that increasing the number of shards didn’t help, but rather reduced the overall performance. We are still investigating this behavior.
- On the other hand, the Dragonfly solution fully topped up the VM with all 64 VCPUs reaching 100% utilization.
- For both solutions, we varied the client configurations to achieve the best possible outcome. As can be seen below, we managed to replicate the majority of the Dragonfly data and even surpass the best results for a pipeline equal to 30.
- This means that there is a potential to further increase the numbers we achieved with Redis.
Last, we also found that both Redis and Dragonfly were not limited by the network PPS or bandwidth, given we’ve confirmed that between the 2 used VMs (for client and server, bot using c6gn.16xlarge) we can reach > 10M PPS and >30 Gbps for TCP with ~300B payload.
Analyzing the results
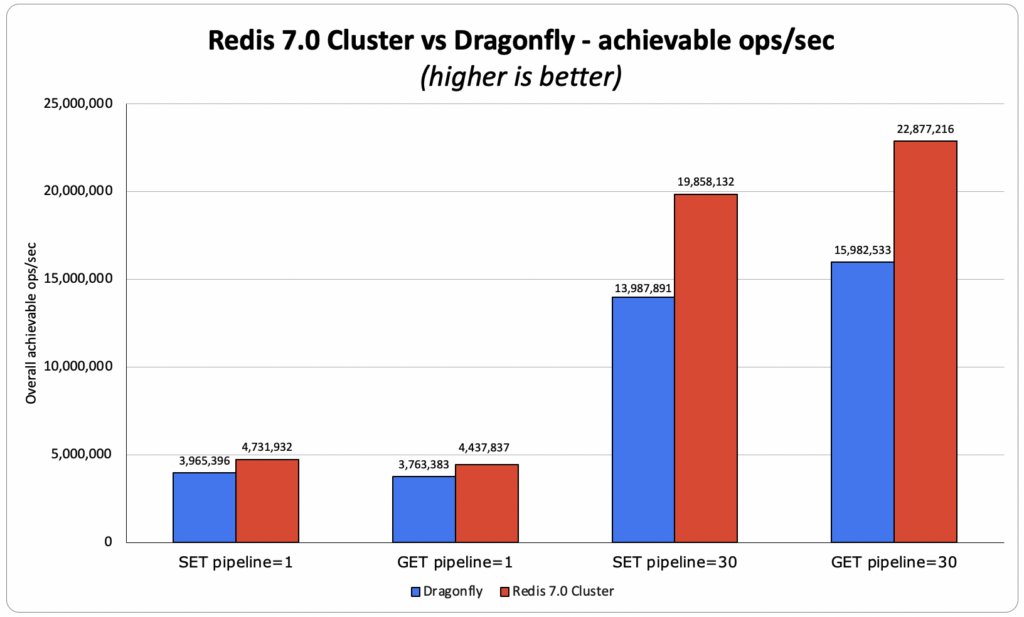
- GET pipeline 1 sub-ms:
- OSS Redis: 4.43M ops/sec, where both avg and p50 achieved sub-millisecond latency. The average client latency was 0.383 ms
- Dragonfly claimed 4M ops/sec:
- We’ve managed to reproduce 3.8M ops/sec, with an average client latency of 0.390 ms
- Redis vs Dragonfly – Redis throughput is greater by 10% vs. Dragonfly claimed results and by 18% vs. the Dragonfly results, which we were able to reproduce.
- GET pipeline 30:
- OSS Redis: 22.9M ops/sec with an average client latency of 2.239 ms
- Dragonfly claimed 15M ops/sec:
- We’ve managed to reproduce 15.9M ops/sec with an average client latency of 3.99 ms
- Redis vs Dragonfly – Redis is better by 43% (vs Dragonfly reproduced results) and by 52% (vs Dragonfly claimed results)
- SET pipeline 1 sub-ms:
- OSS Redis: 4.74M ops/sec, where both avg and p50 achieved sub-millisecond latency.The average client latency was 0.391 ms
- Dragonfly claimed 4M ops/sec:
- We’ve managed to reproduce 4M ops/sec, with an average client latency of 0.500 ms
- Redis vs Dragonfly – Redis is better by 19% (we reproduced the same results that Dragonfly claimed to have)
- SET pipeline 30:
- OSS Redis: 19.85M ops/sec, with an average client latency of 2.879 ms
- Dragonfly claimed 10M ops/sec:
- We’ve managed to reproduce 14M ops/sec, with an average client latency of 4.203 ms)
- Redis vs Dragonfly – Redis is better by 42% (vs Dragonfly reproduced results) and 99% (vs Dragonfly claimed results)
memtier_benchmark commands used for each variation:
- GET pipeline 1 sub-ms
- Redis:
- 2X: memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram
- Dragonfly:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- GET pipeline 30
- Redis:
- 2X: memtier_benchmark –ratio 0:1 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram –pipeline 30
- Dragonfly:
- memtier_benchmark –ratio 0:1 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
- SET pipeline 1 sub-ms
- Redis:
- 2X: memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram
- Dragonfly:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram
- SET pipeline 30
- Redis:
- 2X: memtier_benchmark –ratio 1:0 -t 24 -c 1 –test-time 180 –distinct-client-seed -d 256 –cluster-mode -s 10.3.1.88 –port 30001 –key-maximum 1000000 –hide-histogram –pipeline 30
- Dragonfly:
- memtier_benchmark –ratio 1:0 -t 55 -c 30 -n 200000 –distinct-client-seed -d 256 -s 10.3.1.6 –key-maximum 1000000 –hide-histogram –pipeline 30
Infrastructure details
We used the same VM type for both client (for running memtier_benchmark) and the server (for running Redis and Dragonfly), here is the spec:
- VM:
- AWS c6gn.16xlarge
- aarch64
- ARM Neoverse-N1
- Core(s) per socket: 64
- Thread(s) per core: 1
- NUMA node(s): 1
- Kernel: Arm64 Kernel 5.10
- Installed Memory: 126GB