

Introduction to Caching with Redis
Intro to Caching with Redis Are your applications not responding fast enough? When you scale applications, do you hit a performance penalty wall? Sounds like you might need…

With caching, data stored in slower databases can achieve sub-millisecond performance. That helps businesses to respond to the need for real-time applications.
But not all caches can power mission-critical applications. Many fall short of the goal.
Redis Enterprise is designed for caching at scale. Its enterprise-grade functionality ensures that critical applications run reliably and super-fast, while providing integrations to simplify caching and save time and money.
| Basic Caching | Advanced Caching | |
|---|---|---|
| Sub-millisecond latency | • | • |
| Can speed up a wide variety of databases as a key:value datastore | • | • |
| Hybrid and multicloud deployment | • | |
| Linear scaling without performance degradation | • | |
| Five-nines high availability for always-on data access | • | |
| Local read/write latency across on-premise, multiple clouds, and geographies | • | |
| Cost efficient for large datasets with storage tiering and multitenancy | • | |
| A superior support team with defined SLAs | • | |
| Goes beyond key:value data types to support modern use-cases and data models | • |
Caching patterns need to match with the application scenario. We offer several options, one of which is certain to meet your needs.
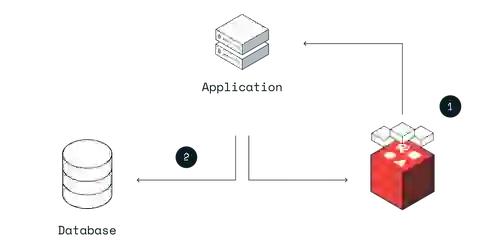
This is the most common way to use Redis as a cache. Cache-aside is an excellent choice for read-heavy applications when cache misses are acceptable. The application handles all data operations when you use a cache-aside pattern, and it directly communicates with both the cache and database.
Query caching is a simple implementation of the cache-aside pattern where there is no transformation of data into another data structure. This pattern is a popular choice when developers aim to speed up repeated simple SQL queries or when they need to migrate to microservices without replatforming their current systems of record.
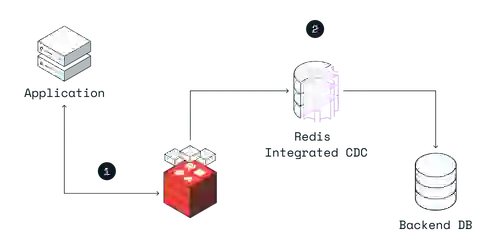
Write-behind caching improves write performance. The application writes to only one place – the Redis Enterprise cache – and Redis Enterprise asynchronously updates the backend database. That simplifies development.
Write-through caching is similar to the write-behind cache, as the cache sits between the application and the operational data store. However, with write-through caching, the updates to the cache are synchronous and flow through the cache to the database. The write-through pattern favors data consistency between the cache and the data store.
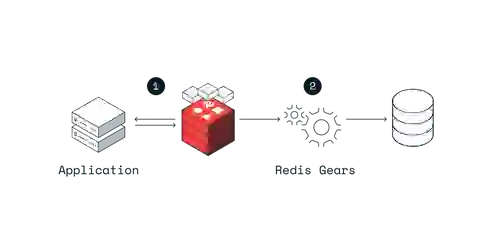
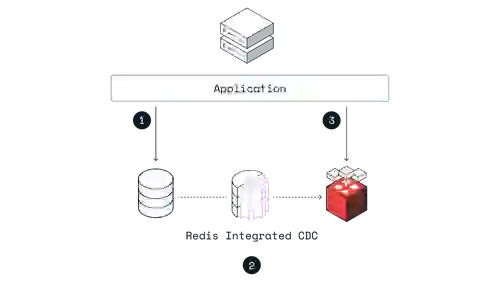
Cache prefetching is used for continuous replication when write-optimized and read-optimized workloads have to stay in sync. With this caching pattern, the application writes directly to the database. The data is replicated to Redis Enterprise as it changes in the system of record, so the data arrives in the cache before the application needs to read it.

Maintains sub-millisecond performance at up to 200 million operations per second

Backed by a 99.999% uptime SLA

Seamlessly use a single platform on premises, in any cloud, and in hybrid architectures

A highly trained team of Redis experts is available 24/7 to operate, scale, monitor, and support your cache

Multi-tenancy and tiered storage reduce the cost, providing up to 80% savings
Caching refers to the process of storing frequently accessed data in a temporary, high-speed storage system to reduce the response time of requests made by applications. Caching can help improve the performance, scalability, and cost-effectiveness of cloud applications by reducing the need for repeated data access from slower, more expensive storage systems.
In-memory caching is a technique where frequently accessed data is stored in memory instead of being retrieved from disk or remote storage. This technique improves application performance by reducing the time needed to fetch data from slow storage devices. Data can be cached in memory by caching systems like Redis.