



13 Years Later – Does Redis Need a New Architecture?
Learn more


We received a lot of good feedback on our post titled, “Learn How Redis Simplifies Your Architecture in 90 Seconds,” so we decided to do a follow-up about Redis as a cache versus Redis as both a cache and a primary database.
Get Started With Redis Cloud: Try Free
Redis began as a caching database, but it has since evolved into a primary database. Many applications built today use Redis as a primary database. However, most Redis service providers support Redis as a cache but not as a primary database. This means you need a separate database like DynamoDB in addition to using Redis. This adds complexity, compromises latency, and prevents you from realizing the full potential of Redis.
StackOverflow voted Redis the Most Loved Database three years in a row, and more than 2 billion Redis Docker containers have been launched. Knowing this, it shouldn’t be hard to find Redis expertise. And when Redis developers get stuck, there are literally thousands of resource books, tutorials, blog posts, and more to help resolve the issues.
There are hundreds of Redis client libraries covering every major programming language and even some obscure ones. In many languages, developers can choose from various libraries to get just the right style and abstraction level. Redis is a database for a range of data sizes, from a few megabytes to hundreds of terabytes.
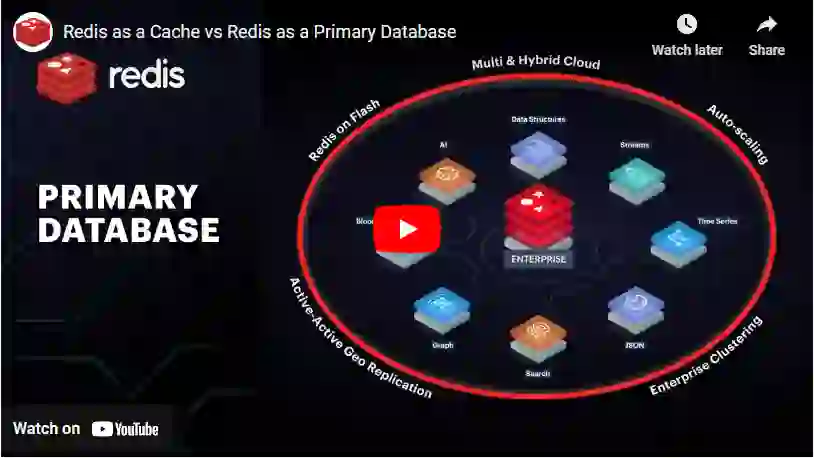
With Redis Enterprise, you can use Redis as both an in-memory cache and a primary database in a single system, thus eliminating the complexity and latency of two separate systems. Not only that, you can use it as a multi-model primary database, enabling you to build modern applications, as well as low-latency microservice-based architectures, all on top of Redis.
Instead of relying on separate databases and caches, utilize the native features of Redis Enterprise, such as
Leverage all of the above with auto-scaling, enterprise clustering, and Active-Active Geo-Distribution.
Watch the video below to see what we mean:
Scaling both a cache and a database is often complicated; each data layer scales differently, reaching infrastructure and optimization opportunities at different times. Additionally, reducing the number of moving parts reduces latency; even though any given piece of the architecture may be fast, each item adds some sort of latency, either through the database itself or the connections made between items. Going to a single data store eliminates several internal network traversals. Finally, developing applications with a single data store requires only a single programmatic interface. Hence, developers need only understand the intricacies of a single database rather than a database and a cache. That reduces the mental cost of context-switching during development.
Redis Enterprise’s Active-Active deployments are integral to achieving that 99.999% reliability and global scalability. This means a single dataset can be replicated to many clusters spread across wide geographic areas, with each cluster remaining fully able to accept reads and writes.
Redis Enterprise uses Conflict-Free Replicated Data Types (CRDTs) to automatically resolve any conflicts at the database level and without data loss. Spreading clusters widely keeps data available at a geo-local latency and adds resiliency to cope with even catastrophic infrastructure failures.
Many applications have relatively simple data needs, which can easily be supported via Redis’ built-in data structures. Other applications may need a bit more. For them, Redis provides an extensible engine that allows modules to add just the capabilities needed and no more. This approach extends to durability – Redis gives you the option of being entirely ephemeral, achieving durability through periodic snapshotting, or going all the way up to on-write durability with Append-only File (AOF). Redis can make the optimal trade-off between performance and durability depending on your use case.
BSD-licensed and relatively compact, Redis is often cited as an example of a clean, well-organized C codebase. If something doesn’t make sense, it’s easy to find out and understand the absolute truth of what the database is doing. Nothing Redis does is magic – it’s just using long-established, efficient patterns to implement fundamental data structures.
Performance expectations are a mainstay and are only getting more stringent with time. You’ll never hear a business leader say, “I wish our database was slower.” Thinking about building modern applications involves making them real-time, easy to develop, operationally elegant, scalable, and future-proof.
Sure, Redis makes a great database cache but expanding Redis’ role as a primary database gives developers a head start on building the applications of tomorrow.

