

Early on Tuesday, November 12, the Redis DevOps team started to get bursts of alerts from our production clusters located in the Amazon Web Services eu-central region (Frankfurt, Germany). Upon further examination, they realized a significant outage was happening in AWS’ eu-central-1 data center, which was confirmed on the AWS status page, and eventually covered in the press:

Cloud outages are not new to us. We have been running production Redis clusters since early 2013 and during that time we’ve experienced more than 3,000 instances failures and over 100 complete data center outages. We deeply appreciate the hard work the cloud providers do to stabilize their infrastructure, but we also know that failures are inevitable. That’s why we invested extensive engineering resources over the years to make sure that our Redis Enterprise Cloud service is built to provide an industry-leading five-nines (99.999%) availability.
Before sharing details about how we overcome outages, let’s take a quick look at the Redis Enterprise Cloud architecture. The service deploys and manages multiple Redis Enterprise clusters across all three major public clouds (AWS, Microsoft Azure, and Google Cloud) and regions. Each Redis Enterprise cluster manages multiple databases of various configurations (for example: single-instance Redis, high-availability Redis, masters-only Redis cluster, and high-availability Redis cluster) in a multi-tenant and isolated manner. We like to think of it as an orchestration platform for Redis databases. That means a failure in one of our clusters can potentially affect hundreds or even thousands of our customers’ databases.
Given the stakes, we promote a multi-AZ (multiple availability zones) database configuration to help customers avoid database failures due to infrastructure outages like what happened on Tuesday.
In this specific case, although all our AWS eu-central clusters were affected, all of our customers were deployed across multiple availability zones and therefore the outage didn’t affect the clusters’ operation and availability—even when in one of the clusters, 5 of 15 nodes clusters went down! Furthermore, hundreds of auto-failover events went smoothly without any data loss (of course) and without a single urgent support ticket. A few users complained that it took more time than expected to execute some admin operations, but that is not surprising during an outage like this.
How is this possible? Here are the principles behind running Redis Enterprise in a multi-AZ configuration:
1. In-memory replication. All Redis Enterprise databases use pure in-memory replication (a feature we contributed back to the OSS project that will soon be a part of Redis 6.0). In-memory replication makes replication twice as fast, which minimizes the time Redis is exposed to double failure events.
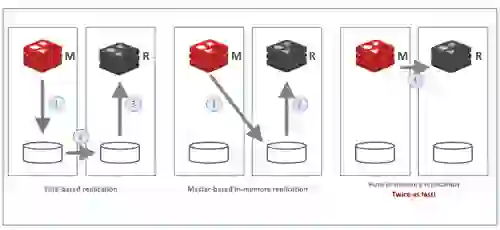
2. Master and replica instances of the same dataset (hash-slots) are deployed on different nodes. In a multi-AZ deployment they are also deployed in a different availability zone.
3. Each cluster node is connected to external persistent memory to allow fast recovery in case of a complete cluster failure.(Luckily that did not happen this time.)
4. Our clusters always include uneven number of nodes; this design allows us to deal with a split-brain situation, as in the case of a network split event.
5. For the same reason, in a multi-AZ configuration, our clusters are deployed across an uneven number of zones.
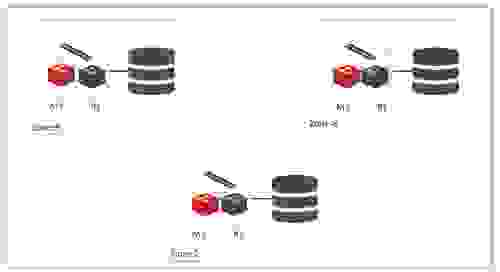
6. We make sure that the number of nodes deployed in each zone is always less than half of the number of cluster nodes. This guarantees that a single-AZ failure will not result in a quorum loss.
A typical Redis Enterprise Cloud multi-AZ configuration might look like this:
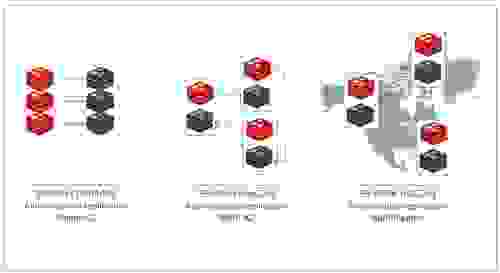
Every modern database should provide multi-AZ capabilities, but that alone is not enough to guarantee 99.999% availability. Five-nines availability, or less than 26.3 seconds of downtime a month, cannot be achieved without a true Active-Active multi-region deployment that lets customers instantly recover from a complete region failure. The following figure summarizes the types of SLA we provide with Redis Enterprise Cloud:
It’s always satisfying when a capability we worked so hard to build actually works as designed under extreme and unexpected production conditions. This event represents yet another example of how Redis Enterprise can be used as primary database for mission-critical use cases, especially for customers who require sub-millisecond latency at extremely high throughput.


