



Learn JSON From Redis Experts
Learn more


These five videos break down the general concepts of clustering through webinars, tutorials, walk-through demos, and even a real-world customer success story from a Fortune 500 company.
So many large datasets, so little time.
Clustering has been a major boon for DevOps. We define a cluster as “a set of cloud instances, virtual machine/container nodes, or bare-metal servers that let you create any number of Redis databases in a memory/storage pool that’s shared across the set.”
Clustering allows IT teams to parse enormous blocks of data quickly, giving them more time to work on other projects, not to mention the flexibility, cost-efficiency, and reliability it generates in your applications. These five videos run the gamut to explain clustering and show how it’s used, from high-level information for those just getting started with clustering to hands-on demos you can follow along with.
How does clustering work? In this video, Justin Castilla, a senior developer advocate at Redis, breaks down clusterings’ top concepts. He explains how it amplifies availability for applications and scales for extra memory, CPU capacity, and throughput.
“Scalability is the property of a system to handle a growing amount of work by adding resources to the system,” says Castilla. To further explain how clustering works, he focuses on the two most common scaling strategies: vertical scaling (also called scaling up) and horizontal scaling (scaling out).
Castilla breaks the video into chapters: sharding, resharding, hash slots, high availability, and split-brain situation, making for a high-level but thorough examination of how clusters work.
Take a closer look at this video’s description on YouTube; Castilla provides a helpful supplemental tutorial and Redis cluster specification links to help you get started.
Are you past the basic clustering concepts and ready to create your own Redis clusters? Justin Castilla is there again.
In just ten minutes, Castilla walks you through his demonstration in four steps:
It’s practical information that you can put to use.
In this presentation from RedisConf 2021, Uber software engineers Anders Persson and Bisheng Huang present the use cases that called for enhanced application scalability. They go through the process by which they migrated to a cluster from initial evaluation to production launch.
Persson and Huang detail how their team built a cluster management library in Go to automate its cluster management. They explain how this new framework could handle several operations, such as adding and removing nodes, restarting nodes, scaling clusters horizontally and vertically, as well as failure recovery protocols.

Watch and listen as they outline the important lessons learned during their migration process.
AWS was also on hand at RedisConf 2021 to discuss clustering. Its representative explained how clustering is seen as a solid, consistent strategy to establish high availability and maximize application performance.
Presented by Madelyn Olson, a software engineer for Amazon ElastiCache, this presentation covers how clustering helps achieve millions of operations per second and the opportunities for improving performance and reliability.
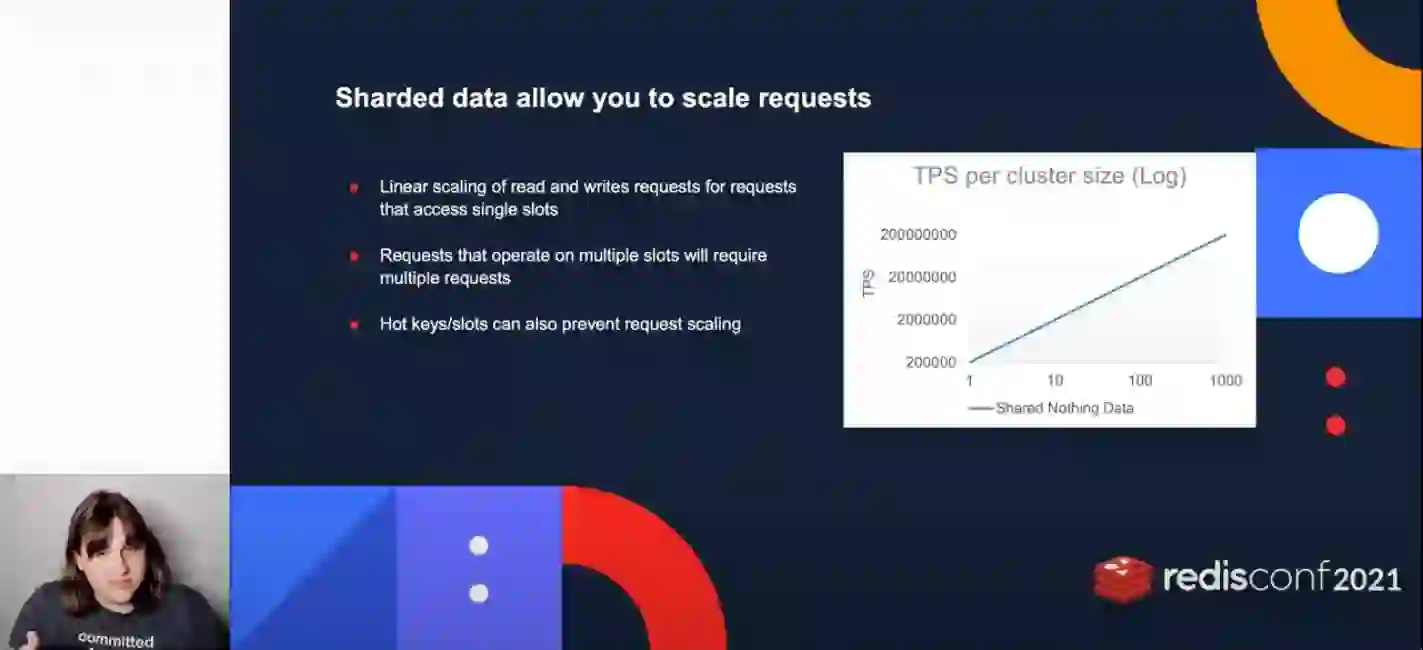
Olson introduced her presentation by saying she hopes “not to just give a bullet point list of what [a cluster does], but to give everyone an intuitive understanding of what it is and some of the choices that were made during development.” Watch her presentation to learn how to use meshes between different nodes in a cluster and how to shard data so that each shard has its own unique data set.
One of the challenges of using clusters is keeping data together that belongs to the same user or application. As Justin Castilla explains in this demonstration, data is stored in different shards based on its hash slot.
What’s a hash slot? As Castilla describes it, “Hash slots are a way to distribute data across shards in [a cluster]. Each key is assigned to a single hash slot, and all keys in the same hash slot are stored on the same shard. This ensures that all of the data for a particular key is always stored together, which can improve performance and scalability.”
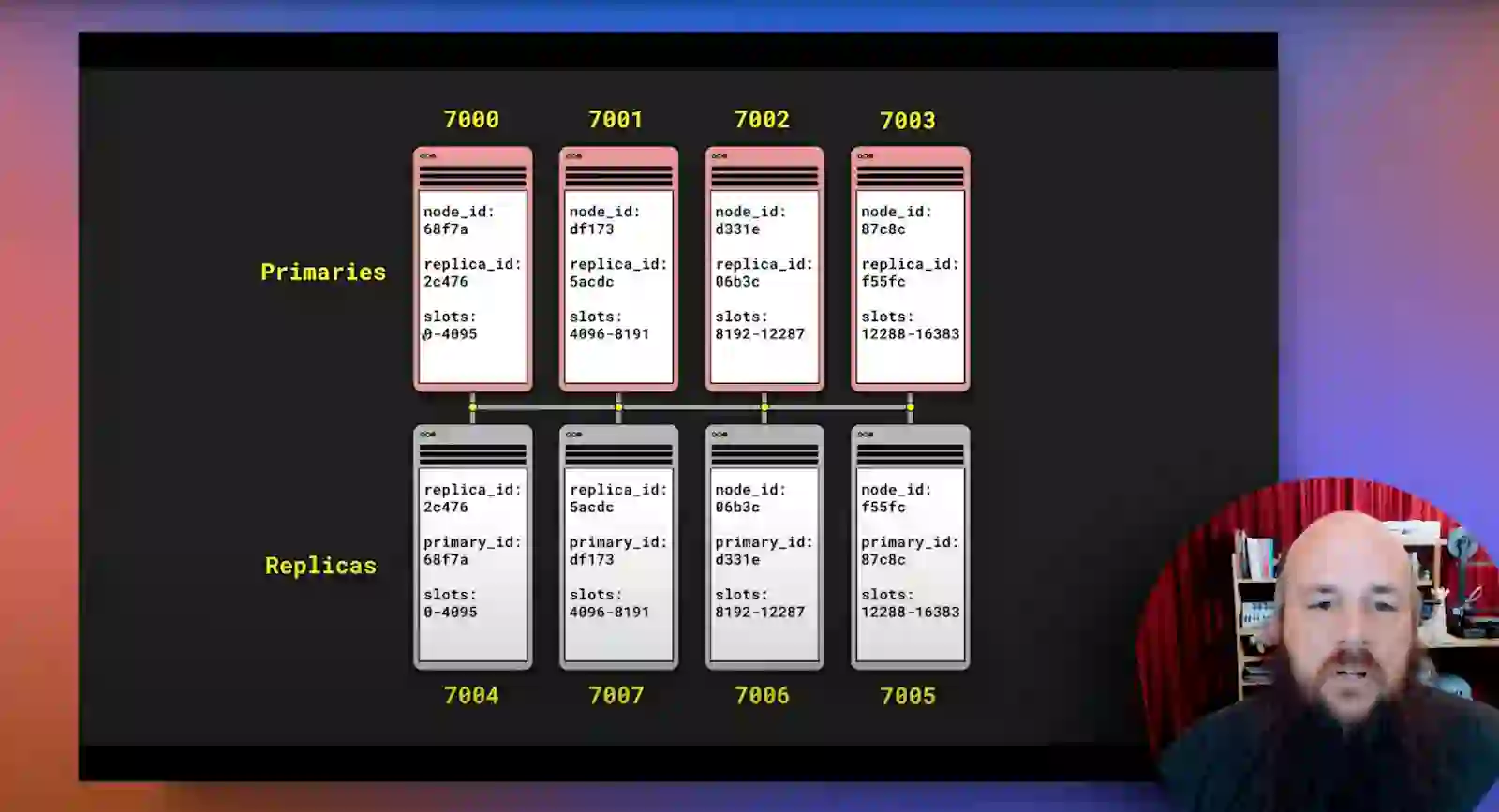
Castilla notes that hashtags are the piece that “allows you to group your data in a given slot since we don’t want to force you to reverse engineer the crc16 to make sure all the data ends up together.”
Castilla demonstrates how hash slots work, provides examples of clusters, cluster slots, and cluster visualization, covers a section on primary shards, using hash slots, and reviews clustering limitations.
How do clusters work with key-value stores? Dive into Redis Clustering Best Practices With Multiple Keys to understand the value of working with keyspaces, avoiding CROSSSLOTS errors, and evaluating MULTI/EXEC transactions.
Looking to understand how clusters power today’s microservices? Download our e-book Redis Microservices for Dummies for more information.

