Leaderboards Aren’t Just for Games: A Pep-talk To Inspire Developers
Learn more


The purpose of Redis OSS’s logical databases, either self-deployed or launched as a managed service such as ElastiCache, is to simplify a developer’s work by reducing administrative needs and by providing out-of-the-box one-size-fits-all defaults.
However, in production, there might come a time when your functional and operational needs change, and a single Redis instance is no longer sufficient.
Here are four signs you might be outgrowing Redis OSS’s logical databases.
Let’s imagine you are a developer at a gaming company. You use three Redis logical databases: one for caching and leaderboards, one for matchmaking, and one as a message broker. Your company recently released a successful new game, and you have peak matchmaking requests every evening. But your leaderboards show stale data during that time period, and your message broker’s latency is increasing.
This is likely because a single Redis instance uses a single thread from the point of view of command execution, and it serves each request sequentially. Because logical databases all share the same instance, this thread may be slowed down or even become blocked by operations executed against a specific logical database and thus impact the other ones. This can cause problems if you have throughput-intensive use cases or your application uses O(n) Redis commands.
In another scenario, you might have a bug. In the context of microservices, for example, where each service reads and writes to a dedicated logical database, all of the services’ databases could fail at once because of a bug in a single microservice. Centralizing multiple use cases in one single Redis instance is not fault tolerant.
What if you used dedicated instances instead of logical databases? Processing each microservice’s requests with a dedicated database would result in better performance for each service, as well as make your application more resilient.
One way to avoid noisy neighbor shortcomings is to scale your database. To do this, you can use OSS Redis Cluster, which allows you to cluster databases across multiple nodes.
However, doing so is only supported on the logical database located in Index 0, which means you can scale only one of your logical databases. This might lead you to store data relative to your more significant use cases in the same logical space, negating the initial intent of keeping separate namespaces.
What if you used dedicated instances instead of logical databases? You could then scale each database as needed without restriction.
Let’s imagine now that you are a software developer at an e-commerce company. You use one logical database for caching and another one for session management. You have the following requirements:
Despite these requirements, your two logical databases must share the same high availability and durability configuration because they both share the same redis.conf files.
The same goes for eviction policies and memory limits, which are specific to caching use cases, as well as TLS certificates, passwords, and, more generally, all configuration options of Redis OSS’s redis.conf file.
What if you used dedicated instances instead of logical databases? No more compromises. You could configure each database as your business requires.
Because logical databases share the same Redis process, you might find monitoring and troubleshooting to be tedious.
A first example is the monitor command, which streams back every command processed by the Redis server. Whichever logical database you run it from, it returns all commands sent to all logical databases running on the server, albeit displaying the database index for each command.
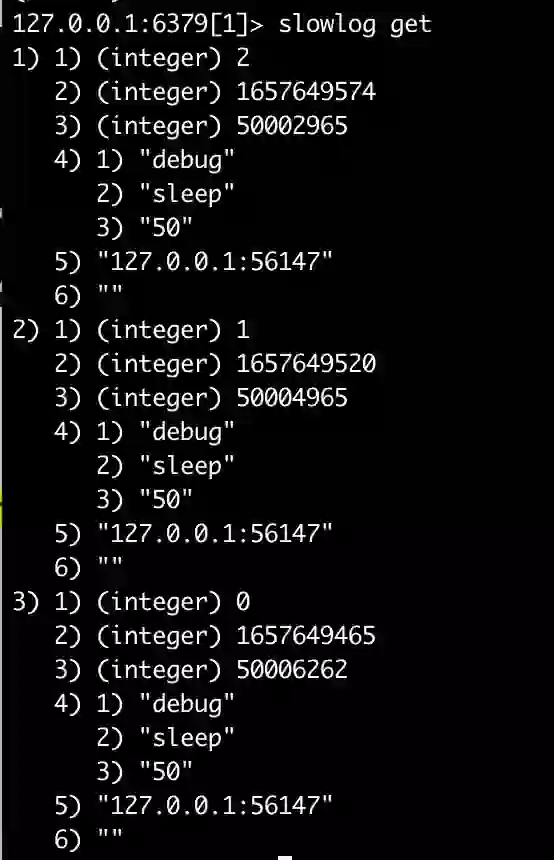
Another example are the slowlog commands. Here, no distinction is made between the logical databases in which the logged commands were run. For example, to artificially create some slow execution commands:
The same goes for logs, latency subcommands, or if you want to grep or get any values from the Redis info command: number of connected clients, used_memory, current IOPS, number of evicted keys, etc.
If you use a third-party tool to monitor Redis, such as Grafana, you have the option to specify the database number when you define your Redis data source. However, the data displayed in the dashboard is not necessarily exclusive to the database index you defined. You do get the right number of keys in the keyspace, but command statistics, client connections, and IOPS are not specific to the selected index; those values are common to the entire Redis instance.
Finally, let’s imagine that, despite the complexity of reading dashboards and logs, you identified that the latency on your caching logical database comes from the fact you enabled AOF upon every write because your session store database needs it. Then what can you do outside of relaxing the persistence requirements for your session database? That goes back here to two of the earlier signs that you are outgrowing logical databases: noisy neighbors and unique configuration requirements.
So what if you used dedicated instances instead of logical databases? It would be easier and faster for you to monitor the performance and identify issues of each database, saving you operational time and effort.
Well, you can start by using separate Redis OSS instances to address your different needs. Or, you could leverage Redis Enterprise’s cluster-level multi-tenancy, which addresses noisy neighboring, fault-tolerance, and generic configuration concerns.
Whichever option you choose, it requires you to migrate your logical indexes to different dedicated databases. Since all logical databases are persisted in the same RDB file, the first step of such a migration is to manually extract the data of each logical database into a separate file. Doing so requires a repetitive process of loading, flushing, and restarting a secondary Redis server.
To save you the trouble, this script automates the process. It loads your data into a secondary Redis server launched as a child process and uses this server to create one RDB file per logical database: 0.rdb, 1.rdb, and so on.
The Redis technical teams are happy to assist you with planning your migration. When you contact us, mention that you want to migrate your logical databases based on what you read in this article.