


Deploying a Microservice Data Layer on Kubernetes
Learn more
Microservice architectures make it possible to launch new products faster, help them scale easier, and respond better to customer demands. With its multiple modern data models, fault tolerance in any scenario, multi-tenancy for isolation, and the flexibility to deploy across multiple environments, Redis Enterprise enables devs and operators to optimize their data layer for a microservices architecture.

As defined by Chris Richardson, noted microservices expert, microservices architecture is an architectural style for structuring apps as a collection of loosely coupled services that are highly maintainable and testable, independently deployable, bounded by specific business domains, and owned by small teams. A microservice architecture enables the rapid, frequent, and reliable delivery of large, complex apps.

Microservices-based apps enable strategic digital transformation and cloud migration initiatives
Microservices is an architecture style that has helped development teams create better software, faster, and minimize the costs and complexity of app modernization. As a result, microservices architectures have been adopted across all industries, for projects that justifiably can be labeled “digital transformation initiatives” as well as for more mundane but important tasks such as bootstrapping cloud deployments.
This architecture style and its related software development culture enable microservices development teams to operate on their own release cycles, embrace end-to-end product ownership, and adopt a DevOps framework built on continuous integration/continuous delivery. The result is that enterprises can reduce time-to-market for new service development, often from projects measured in months to days.
Microservices accelerate data tier cloud migrations. That’s because they primarily rely on cloud-native NoSQL databases. NoSQL databases are replacing on-premises relational databases that were not built for the cloud nor for independent release cycles, according to a 2021 IDC InfoBrief survey.
In addition, some organizations cannot migrate their legacy monolith apps to cloud-native all at once. Microservices enable incremental migration of subdomains from a monolithic architecture to modern technology stacks.
In a microservices environment, services that need to run in real-time must compensate for networking overhead. Redis Enterprise delivers sub-millisecond latency for all Redis data types and models. In addition, it scales instantly and linearly to almost any throughput needed.


To ensure your apps are failure resilient, Redis Enterprise uses a shared-nothing cluster architecture. It is fault tolerant at all levels: with automated failover at the process level, for individual nodes, and even across infrastructure availability zones. It also includes tunable persistence and disaster recovery.
Redis Enterprise allows developers to choose the data model best suited to their performance and data access requirements for their microservices architecture and domain driven design, while retaining isolation with multi-tenant deployment on a single data platform.


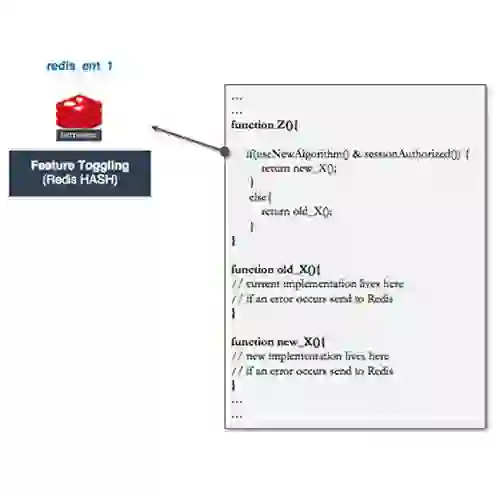
Redis Enterprise provides a unified operational interface that reduces technology sprawl, simplifies operations, and reduces service latency. The Redis Enterprise Operator for Kubernetes gives you consistent, automated deployments to reduce risk. That lets dev teams focus on innovation and business value.
Choose where your database should run. Redis Enterprise can be deployed anywhere: on any cloud platform, on-premises, or in a multicloud or hybrid cloud architecture.

Isolation or bounded context is an important characteristic of a microservice architecture. As part of domain-driven design, each service can have a dedicated database with its own unique data model and service level agreement performance goals. Query caching, a cache pattern commonly used to reduce microservice response times, works by deploying a Redis Enterprise cache alongside each microservice to deliver data that is needed within a single business context. (That is, it serves only one microservice.)
The Redis Smart Cache is an open source library that seamlessly adds caching to any JDBC—compliant platform, app, or microservice, improving query performance while reducing operational complexity – and you don’t need to change app code. Redis Enterprise supports multiple data models that can be easily deployed multi-tenant, yet remain isolated, all without sacrificing performance.


Microservices need fast access to data, but that can be a challenge when dozens or hundreds of microservices try to read from the same slow disk-based database. Cross-domain data needs to be available to each microservice in real-time—and to do so without breaking the scope of its focused business context and goal.
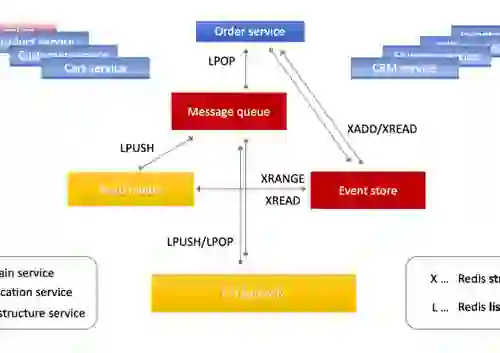
Command Query Responsibility Segregation (CQRS) is a critical pre-fetch cache pattern within microservice architectures that decouple reads (queries) and writes (commands). This enables an app to write data to a slower disk-based SQL database, while pre-fetching and caching that data using the integrated Change Data Capture (CDC) capability in Redis Enterprise for lightning-fast reads. Doing so makes that data immediately available to other microservices that need it.
Microservices apps can cache globally accessed data at the API gateway level to distribute and speed up data that is accessed by all services. Typically this would be session data (such as user ID and preferences) and authentication data (tokens, authorization status, permissions). This enables frequently needed data available in real time to all services. The result? Reducing app latency without breaking the bounds of each microservice business context.
Rate limiting, in which one meters the number of API requests in a certain timespan, can also be implemented at the API gateway using Redis Enterprise. This can prevent overloading the system and prevents DDoS attacks.


Microservices must communicate state, events, and data with one another without breaking isolation, and they have to stay decoupled. A common solution is to bring a publish—subscribe messaging broker into the architecture—that is, to make inter-service communication event-driven and eventually consistent–and to treat every message between microservices as an event.
Redis Streams is an immutable time-ordered log data structure that enables a service (producer) to publish asynchronous messages to which multiple consumers can subscribe. It can be configured to handle different delivery guarantees, support consumer groups, and to apply other features that are comparable to Apache Kafka topic partitions. Even better, Redis Streams helps to create reporting, analytics, auditing, and forensic analysis on the backend.
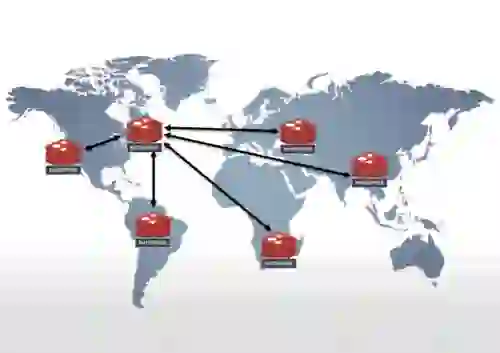
A microservices architecture has many connected services, yet it faces the same performance demands as monolithic apps. To minimize latency, data should reside as close to the services as possible. You also need to ensure databases are consistent with one another in the event of failures or conflicting updates. Redis Enterprise can be deployed as an Active-Active, conflict-free replicated database to handle updates from multiple local installations of your services without compromising latency or data consistency and providing continuity in the event of failures.
Redis Enterprise provides multiple data structures (hashes, strings, Streams, lists, etc.) and models including JSON, search, time-series, and graph that let you choose the data model best suited for your microservice domain, performance, and data-access requirements. And it’s all in a single data platform.
Within a microservices architecture database design, a single Redis Enterprise cluster can provide databases to many different services, each with its own isolated instance, tuned for the given workload. Each database instance is deployed, scaled, and modeled independently of the others, while leveraging the same cluster environment, isolating data between services without increasing operational complexity.
Microservices provide a great deal of technology flexibility, and choosing where you want to run your database should be no exception. Redis Enterprise can be deployed anywhere: on any cloud platform, on-premises, or in a multicloud or hybrid-cloud architecture. It is also available on Kubernetes, Pivotal Kubernetes Service (PKS), and Red Hat OpenShift.
Containers are closely aligned with and help enterprises implement microservice apps. Kubernetes is the de facto standard platform for container deployment, scheduling, and orchestration. Redis is the top database technology running on containers, with over two billion Docker hub launches. Redis Enterprise Operator for Kubernetes provides: automatic scalability, persistent storage volumes, simplified database endpoint management, and zero downtime rolling upgrades. It is available on multiple Kubernetes platforms and cloud managed services, including RedHat OpenShift, VMware Tanzu Kubernetes Grid (formerly Enterprise PKS), upstream Kubernetes, and Azure Kubernetes Service (AKS), Google Kubernetes Engine (GKE), or Amazon Elastic Kubernetes Service (EKS).
Learn more

Learn more

Learn more

Learn more

Learn more

Learn more

Learn more

Learn more
Learn more

Learn more

Learn more

Learn more
Learn more

Learn more
Learn more

Learn more